

There are several different strategies available for getting improved performance when processing large quantities of data. If you’re working with substantial vectors or matrices of floating-point numbers, you should first look at what Apple’s Accelerate can offer. This uses what should be the optimal hardware for any given Mac, whether it has an Intel or Arm processor. It has access to the AMX co-processor in M1 chips, for example, which you can’t use even with assembly language. Apple’s frameworks and libraries can also use the Neural Engine when appropriate, another feature of the M1 chip which doesn’t have direct third-party access.
There are occasions, though, when Accelerate and other features don’t offer anything better than using the NEON SIMD features in the Arm processor. It’s also important to be able to read and understand assembly language which uses SIMD, or you won’t be able to grok sections of disassembled ARM64 code when they use SIMD.
The SIMD model
Instead of having a complete new instruction set to perform SIMD operations like parallel multiplication, ARM64 uses many of the same instructions as floating-point scalar code, but by applying them to SIMD packed registers, they’re recognised and run as SIMD. For example, you can multiply two double-precision scalars using
FMUL D0, D1, D2
which multiplies the doubles in D1 and D2 and stores the result in D0. The same instruction applied to SIMD operands
FMUL V0.4S, V1.4S, V2.4S
multiplies four packed single-precision floating-point values in the SIMD registers V1 and V2, and stores the results of those four multiplications as four packed single-precision floating-point values in V0. The giveaway here is that the registers themselves are special 128-bit SIMD registers, V0 to V31, and each operand specifies the laning to be used, in this case packing the 128-bit register with four single-precision floating-point lanes.
SIMD instructions can be applied to signed and unsigned integers from 8-bit to 64-bit, and on 32-bit and 64-bit (and, in some ARM processors, 16-bit) floating-point numbers, packed into SIMD registers of total width 64 or 128 bits.
Packed registers and lanes
To cope with such a broad range of data types and sizes, there are strict conventions for the formation of operands for SIMD operations. These are shown in the diagram below.
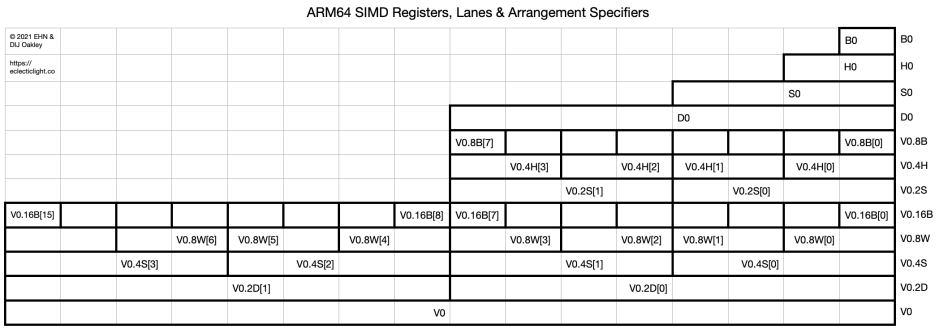
These give all the ways in which the first register, numbered 0, can be referenced. At the top are the conventional registers from 8-bit B0 to 64-bit floating-point D0, with the 128-bit SIMD V0 at the bottom.
Between those are the packed SIMD register variants, ranging from V0.8B which packs eight 8-bit lanes into 64 bits, up to V0.4S for four 32-bit floating-point values in 128 bits, and V0.2D for two 64-bit floating-point values in 128 bits. The part of the register name after the dot is formally termed the arrangement specifier.
Inside the cells are individual names for the packed values. The first (lowest) of the single-precision floating-point values in V0.4S can thus be referenced as V0.4S[0], and the last (highest) as V0.4S[3].
What should perhaps be obvious from this is that loading, moving and storing instructions are going to be crucial and complex, as they are. The SIMD instruction set has to make elaborate provisions to enable these packed registers to be set up and saved correctly. These not only cope with contiguous or sequential values, passed in an array, but those which are interleaved such as RGB values and matrices.
Simple load and store
One of the simplest cases is passing an eight-element array of single-precision floating point values by reference. In that case, in Swift you’d call the function as
myfunc(&myArray)
and load two 128-bit floating-point registers using
LDP Q2, Q3, [X0]
Nothing worries that, rather than being two 128-bit numbers, they are in fact eight 32-bit numbers, so you can then use the SIMD vector version of FMUL to multiply the corresponding pairs of values using
FMUL V1.4S, V2.4S, V3.4S
You can use STP to store a pair of registers to deliver the result. LDR and STR can be used likewise to fill and save single Q registers.
The LDn family
Full support for loading SIMD registers is provided using a family of operations LDn, which can be applied to single or multiple structures, and LDnR which includes replication. The value of n ranges from 1, for single-element structures, to 4, for four-element. In all, these represent 12 different instructions. For storing, there are matching STn instructions, but not STnR.
Taking the simplest LD1 and LD1R as a template:
- LD1 loads multiple single-element structures to 1-4 SIMD registers
- LD1 loads a single-element structure to the specified lane of an SIMD register without affecting the other lanes
- LD1R loads a single-element structure to all the lanes of an SIMD register.
LD1 { V0.4S, V1.4S }, [X0]
loads the eight single-precision floating-point numbers at [X0] into the lanes of first V0 then V1 in order. This can also be used with both register and immediate offsets.
LD1 { V0.S }[0], [X0]
loads one single-precision floating-point number at [X0] into the first of the four lanes of the V0 register, divided as 4S, or V0.4S[0]. This can also be used with both register and immediate offsets.
LD1R { V0.S }, [X0]
loads one single-precision floating-point number at [X0] into each of the four lanes of the V0 register as 4S. This can also be used with both register and immediate offsets.
LD1 and LD1R work with sequential data of the form x0, x1, x2, x3, …. The other three groups of operations work with interleaved structures:
- LD2 and LD2R de-interleave two-element structures x0, y0, x1, y1, x2, y2, … into one register containing x0, x1, x2, … and the other register with y0, y1, y2, ….
- LD3 and LD3R de-interleave three-element structures x0, y0, z0, x1, y1, z1, … into one register containing all the xes, a second containing all the ys, and a third containing all the zs.
- LD4 and LD4R de-interleave four-element structures x0, y0, z0, t0, x1, y1, z1, t1, … into four registers, the first containing all the x values, the second all the y values, the third all the z values, and the fourth all the t values.
LD2 { V0.S, V1.S }, [X0]
loads the interleaved series of values at [X0] into the two SIMD registers V0 and V1 so that the first value at [X0] goes into the first lane of V0, the second value into the first lane of V1, and so on alternately.
LD2 { V0.S, V1.S }[0], [X0]
loads a single pair of values at [X0] into V0.4S[0] and V1.4S[0].
LD2R { V0.S, V1.S }, [X0]
loads a single pair of values at [X0] and fills all the lanes in V0.4S with the first value, and all those in V1.4S with the second value.
LD4R { V0.S, V1.S, V2.S, V3.S }, [X0]
loads a single quad of values at [X0] and fills all the lanes in V0.4S with the first value, all those in V1.4S with the second value, all those in V2.4S with the third value, and all those in V3.4S with the fourth value.
In the next article in this series, I’ll look at STn store, moving, and related instructions, and provide a cheat sheet covering these.
Previous articles in this series:
1: Building an app to develop assembly routines, including an explanation of calling assembly language from Swift, with a complete Xcode project
2: Registers explained
3: Working with pointers
4: Controlling flow
5: Conditional loops
6: Flow, pipelines and performance
7: Moving data around
8: Integer arithmetic
9: Bit operations
10: Conditions without branches
11: Floating point registers and conversions
12: Rounding and arithmetic
13: Accelerating the M1 Mac: an introduction to SIMD
Downloads:
Register summary
Operand architecture
Conditions and conditional branching instructions
Control Flow
Conditional selection
Instructions for GP registers
Floating point conversions
Floating point arithmetic (scalar)
AsmAttic 2, a complete Xcode project (version 2)
AsmAttic, a complete Xcode project (version 1)
References
Procedure Call Standard for the Arm 64-bit Architecture (ARM) from Github
Writing ARM64 Code for Apple Platforms (Apple)
Larry D Pyeatt and William Ughetta (2020) ARM 64-Bit Assembly Language, Newnes, ISBN 978 0 12 819221 4 – the best account of SIMD instructions by far.
Stephen Smith (2020) Programming with 64-Bit ARM Assembly Language, Apress, ISBN 978 1 4842 5880 4.
Daniel Kusswurm (2020) Modern Arm Assembly Language Programming, Apress, ISBN 978 1 4842 6266 5.
ARM64 Instruction Set Reference (ARM).
