
I have made some bold claims about Unicode resulting in problems because of characters which we cannot tell apart, although they have different code points (encodings). These led me to call for Unicode to be reformed to address these issues.
I felt that the best way to demonstrate my case and these problems was to build them into an app which you can try out on your own Macs – Dystextia, available from Downloads above.
Dystextia will show you how it is simple to generate text containing the ‘wrong’ Unicode characters, which look identical to the normal Latin forms entered via the keyboard. But when you try to do anything like search for words, or build a concordance, the use of those ‘wrong’ characters creates a nightmare: you can see a word like and, but cannot find it.
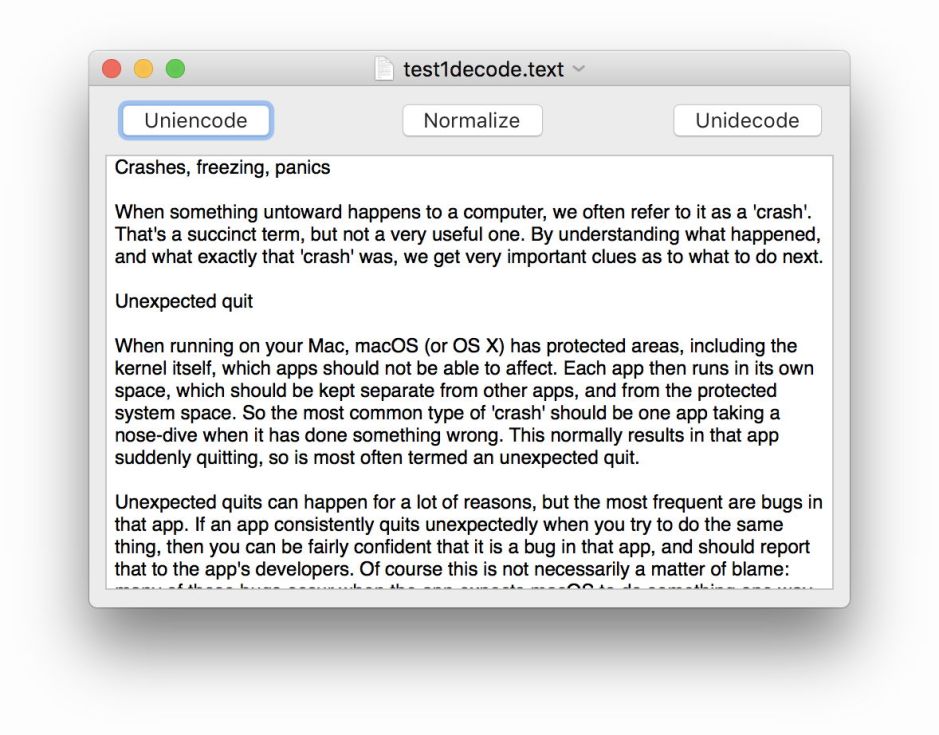
Dystextia opens plain text files with the file extensions .txt and .text, or you can paste or enter text into its window.
Clicking on the Uniencode button converts many of its characters to the ‘wrong’ forms. You can then even try to normalise them by clicking on the Normalize button. This applies Form KD normalisation, which is wider in scope that the Form D used by the Mac’s HFS+ file system. However, it has little if any effect on the converted text.
Clicking on the Unidecode button reverses the encoding, and should restore your original text.
Currently, Dystextia only changes unaccented Latin text; I have for the moment limited this demonstration to unaccented Latin characters, all of which were (unambiguously) in the old 7-bit ASCII character set. I am sure that someone more linguistically capable could do far more with other scripts as well.
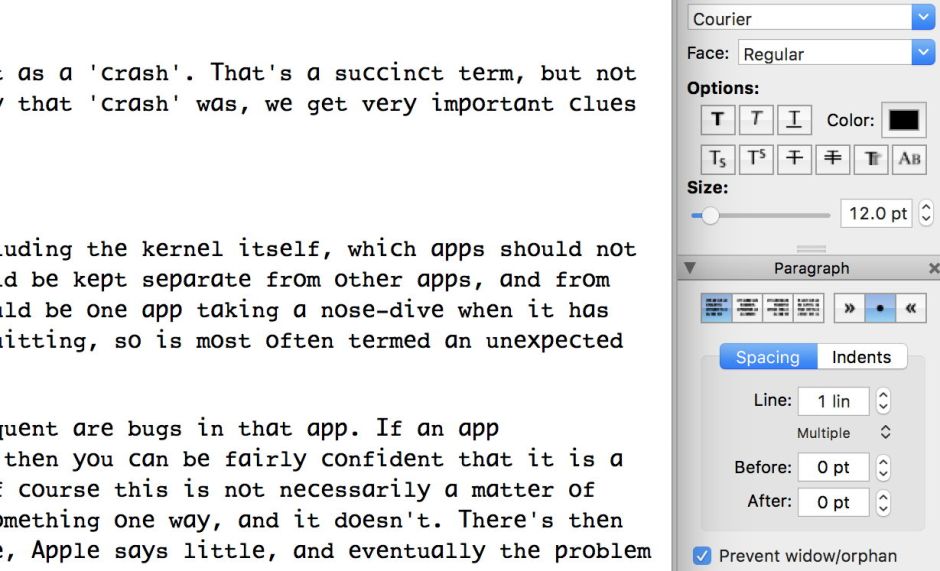
If you open saved, or copied, encoded text in a word processor and render it in different fonts, you will see that some of the encoded letters do appear different when viewed in certain fonts. The old version of Courier is quite effective at showing many of them, but does not reveal all.

Curiously the newer version of Courier does not help at all.

The great majority of screen and printer fonts show only small differences, or none at all.
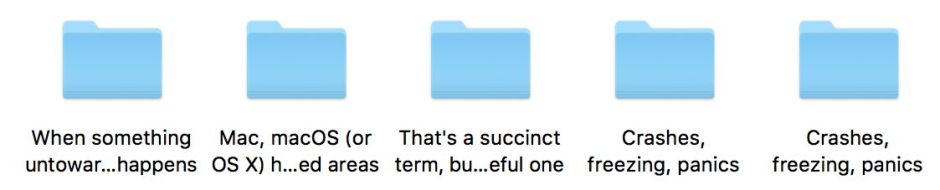
Once you have encoded text in Dystextia, you can copy and paste it into the names of files and folders, for example. Four of these five folders use ‘wrong’ forms, such that a folder using only the ‘right’ Unicode characters (at the far right) can happily co-exist, even though the two folders at the right appear to have the same name. Most fonts optimised for system use (as seen here) show no differences at all between ‘good’ and ‘bad’ characters.

Dystextia will also encode and decode URLs for experiments in ‘spoofing’. As shown here, only the domain is converted into Punycode when used in a URL. This shows how easy it would be to use deliberately malformed Unicode characters to spoof users to a covert page on a normally-named webserver: nothing abnormal would be seen in the browser at all.
The encoding demonstrated in Dystextia has some practical uses too. Although this encoding has no value in security, it effectively obfuscates text content from any form of mass surveillance. I have used it with Apple’s iMessage service (Messages app), and it can be used in emails, and transmitted documents. If a third party is scanning text content looking for keywords, for example, the encoding will block their discovery unless their string comparison algorithm goes far beyond regular normalisation.
As far as I am aware, this form of text encoding is the only scheme which currently prevents electronic text analysis, but which remains completely intelligible to the user, without being decoded. That is a potentially very interesting property.
To demonstrate this further, the paragraph below is a duplicate of one above, in encoded form. I expect that you will see differences in some characters, but it should remain perfectly understandable to a human:
<encoded>
Τhе еnсоdіng dеmоnstrаtеd іn Dуstехtіа hаs sоmе рrасtісаl usеs tоо. Αlthоugh thіs еnсоdіng hаs nо vаluе іn sесurіtу, іt еffесtіvеlу оbfusсаtеs tехt соntеnt frоm аnу fоrm оf mаss survеіllаnсе. Ι hаvе usеd іt wіth Αррlе’s іΜеssаgе sеrvісе (Μеssаgеs арр), аnd іt саn bе usеd іn еmаіls, аnd trаnsmіttеd dосumеnts. Ιf а thіrd раrtу іs sсаnnіng tехt соntеnt lооkіng fоr kеуwоrds, fоr ехаmрlе, thе еnсоdіng wіll blосk thеіr dіsсоvеrу unlеss thеіr strіng соmраrіsоn аlgоrіthm gоеs fаr bеуоnd rеgulаr nоrmаlіsаtіоn.
</encoded>
Enjoy.
