

The world is full of fakes, and always has been. From the day that someone first noticed how similar iron pyrites (“fool’s gold”) is to gold, there have been people palming it off. It’s not just news and luxury goods, either: a little fake Adobe Flash updater can bring a payload of pain to a computer user.
Your eye may be sufficiently trained to tell iron pyrites from the real stuff, but when it comes to words, the sharpest-eyed expert can easily be fooled. Even in these days of AI, AR, and VR, character strings remain crucial on our computers: in particular, we use them to identify websites, folders, files, as well as holding content.
Internally, it matters not whether these words are handled as IP addresses, hash codes, or whatever. When we look at the identifiers of most (virtual) objects, we see them as strings of characters. And we trust what we think we see.
I have already explained and demonstrated how easy it is to fool people with crafted characters, whether in file and folder names, or in URLs. The problem boils down to the fact that Unicode represents many visually-identical characters (or forms) using different encodings.
Although there is clear strength in the case for human languages being provided with full character sets, Unicode has been profligate. For example, K is a capital letter k and encoded as UTF-8 48, and K is the KELVIN SIGN, defined in standards as a capital letter k, with the UTF-8 encoding of E2 84 AA. There’s also a Greek Κ, GREEK CAPITAL LETTER KAPPA which is CE 9A. There are separate number forms of Ⅼ, Ⅽ, Ⅾ, Ⅿ, and their lower-case forms, which are encoded quite differently from their regular ‘Latin’ equivalents. There’s a Greek Ϲ, a Cyrillic С, a mathematical 𝖢, and possibly a few more. Then there are accents…
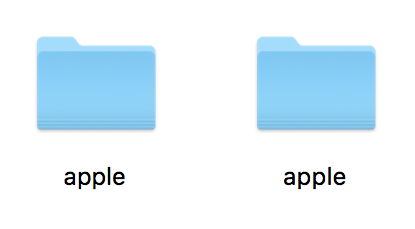

The process of normalisation is intended to address that, but is incomplete and inefficient. Several have questioned my claim that it is incomplete: the screenshots showing visually-duplicated names of folders shown in this article were all made using macOS Sierra 10.12 with its normalising file system, HFS+, and Apple’s specially-designed system font. Can you tell the fake characters from the ‘real’ ones?
Of the three Ks cited above, KKΚ, only the first two normalise, leaving the Greek capital kappa encoded differently after normalisation. Of the five Cs, CⅭϹС𝖢, none normalises (under Forms C or D) and all five retain different encodings, unless you use the rare KC or KD forms.
Modern file systems, like Apple’s APFS, are trying to avoid performing any normalisation in their bid to improve performance. It does seem crazy that a file system should be burdened with performing lengthy look-up tasks on each folder and file name to check whether it could or should be normalised to something else.
The problems extend far beyond file systems and URLs. Software does a great deal with strings, and they often end up being compared, searched, or sorted, operations which are heavily-dependant on the way in which strings are encoded. Whenever there are strings which can appear to a normal human being to be the same, but which are encoded differently, there will be scope for confusion, error, and exploitation.

Unicode is one of the foundations of digital culture. Without it, the loss of world languages would have accelerated greatly, and humankind would have become the poorer. But if the effect of Unicode is to turn a tower of Babel into a confusion of encodings, it has surely failed to provide a sound encoding system for language.
Neither is normalisation an answer. To perform normalisation sufficient to ensure that users are extremely unlikely to confuse any characters with different codes, a great many string operations would need to go through an even more laborious normalisation process than is performed patchily at present.
Pretending that the problem isn’t significant, or will just quietly go away, is also not an answer, unless you work in a purely English linguistic environment. With increasing use of Unicode around the world, and increasing global use of electronic devices like computers, these problems can only grow in scale. I’m not aware of any exploitation of Unicode encoding in malware, but if we leave it until there is an established security problem before even considering how to address the issue, then the vulnerability will remain open for a long time to come.
Having grown the Unicode standard from just over seven thousand characters in twenty-four scripts, in Unicode 1.0.0 of 1991, to more than an eighth of a million characters in 135 scripts now (Unicode 9.0), it is time for the Unicode Consortium to map indistiguishable characters to the same encodings, so that each visually distinguishable character is represented by one, and only one, encoding.
That is a stark challenge, and one that I am sure will never even be started. But until we do, today’s minor running sores will only fester and grow.
