
Text and numbers were the first types of data to be widely used by computers, and no matter whether your Mac is your graphic design tool, your image or movie editor, or your main musical instrument, you cannot but help working with text.
This series of articles explores how your Mac handles text, how you can get the best out of that, and how you can fix any problems that arise with text. This first article tackles the format that all text in OS X uses: Unicode.
Why Unicode? What was wrong with ASCII?
The first universal standard for encoding and storing text on computers was 7-bit ASCII, over 50 years old now. In using just 7 of the 8 bits in each byte, it was very compact and worked everywhere, even where old parts of the Internet could not handle the full 8 bits of each byte. It coped with just 128 different characters, supporting the Roman alphabet of English quite well with the full upper and lower case sets, digits, punctuation marks, and a set of control characters needed for dumb terminals and the like.
It didn’t work for most of the languages of the world which were based on non-Roman script systems, some of which (like Chinese and Japanese) were very complex and very widely used, and could not handle anything beyond the basics in English. So if your software needed to encode ligatures, such as the special ‘fi’ combined glyph used in typesetting, individual apps had to find a way round that.
Various kludges were devised to handle these non-Roman scripts, typography, and so on, but they were inevitably non-standard and that caused huge problems. For example, if you wanted to process documents in Japanese, you had to buy special Japanese localised versions of apps such as Microsoft Word, each of which would encode different characters in different ways. To open a Word-JP document you really had to use the Japanese version of Word, as another word processor might be unable to cope with the encoding, and all you would then see was gibberish.
You may still come across such old text, whose encoding is based on a ‘codepage’ which defined the binary codes used for each of the characters available. For example, Cyrillic (including Russian) text might be encoded using the KOI8 codepage, just one of several widely used. However if you try opening it using a codepage known as MIK, the content will be rendered as unintelligible garbage. Because this was a common problem in Japanese, it has become known by its Japanese term as ‘mojibake’.
Problem: You open an old document only to discover its has ‘mojibake’. How can you open it properly?
Solution: Establish its likely origin, and if possible the codepage that it uses. Old binary formats may require you to go back to the original app which created them (virtualisation can be helpful here!). Old text formats should be easier to handle, once you work out the codepage. Even current HTML and PDF documents may still not use Unicode; in those cases you may need to open the document and export as text, then try converting the codepage.
Tools: Text Encoding Converter, Encoding Master or Peep to convert between codepages. TextSoap to clean up ligatures and other mess.

How does Unicode encode text?
A cross-platform standard launched in 1991 and currently in version 7.0.0 (revised 16 June 2014), Unicode offers a lot of flexibility in the encoding of text, with a choice of 1, 2, or 4 byte (8, 16, or 32 bit) encoding schemes. These are known as UTF-8, UTF-16. and UTF-32 respectively.
UTF-8 is potentially the most compact and efficient, as it maps the old ASCII Roman character set into single byte codes. However where the text calls for characters outside that, it may require up to 4 bytes to represent them. It is also in many cases slightly slower to handle that the other formats, because of the more elaborate software algorithms required to encode and decode.
UTF-16 is something of a compromise format between the 8-bit and 32-bit schemes. UTF-32 is the least efficient in terms of required storage, as every character requires the full 4 bytes, but is normally the quickest to process. In fact Unicode currently does not require all 32 bits of the full encoding, and only uses 21 bits, up to its highest code of 10FFFF in hexadecimal. This is useful, as you should see every fourth byte in UTF-32 set to 00, making it easy to recognise and correct for errors.
There is one final twist with Unicode: whether it is ‘little-ended’ or ‘big-ended’. Different processor architectures order bytes in one of two ways, little- or big-ended, depending on whether the most significant (largest) byte comes first. Therefore UTF-16 and UTF-32 come in different variants according to whether they are arranged in little- or big-ended byte ordering. If you are sure that some text is Unicode and are struggling to get any sense from it, you could try swapping between BE and LE variants to see if that helps.

So one of the traditional ASCII characters, the small case letter ‘a’, is 61 in UTF-8, 0061 in UTF-16, and 00000061 in UTF-32. The Greek small case letter ‘α’ is CEB1 in UTF-8, 03B1 in UTF-16, and 000003B1 in UTF-32. The Georgian small case letter ‘ა’ is E18390 in UTF-8, 10D0 in UTF-16, and 000010D0 in UTF-32. The Phoenician letter ‘𐤀’ is F090A480 in UTF-8, D802DD00 in UTF-16, and 00010900 in UTF-32. (Note that the characters shown here will only render properly in your browser if you have a suitable font enabled to support them.)
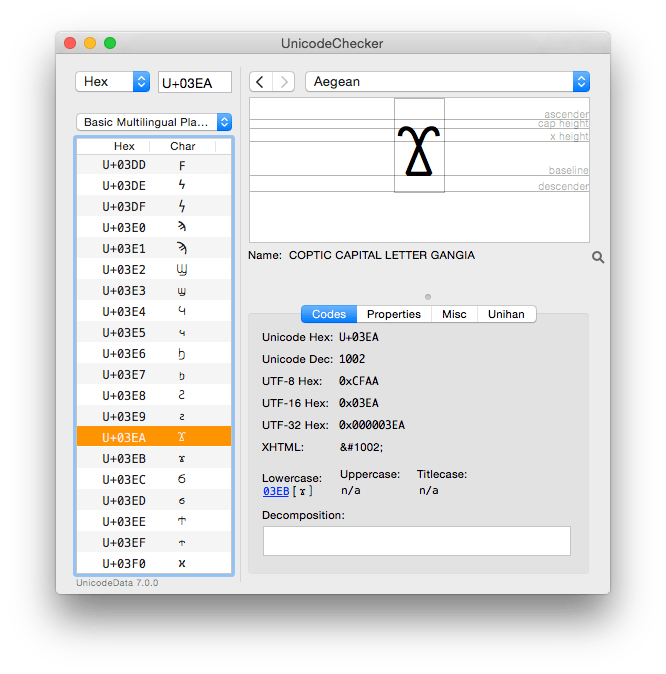
You can explore Unicode encoding and related information using UnicodeChecker.

Why are there still problems with text encoding?
Despite Unicode having been around for so long, and being supported by OS X and Windows for many years, not all apps and formats have moved with the times. The two major offenders now are HTML and PDF.
Many older websites still use 8-bit text, and a few still use old codepages to handle non-Roman scripts. Although these are fading away, if you do stumble across one, you can only try the tools listed to make the best sense possible. Switching fonts in your browser could also help render the content properly, but you are largely going to have to work by guesswork. If the site is that important, try downloading it as raw HTML and work on that offline.
When you are writing HTML, directly or using a more friendly editor, you must ensure that its headers assign the coding scheme explicitly, or in meta tags. As a minimum, cast your content in UTF-8 even if it could all be contained in the original 7-bit ASCII character set. Remember that your readers may be working in a completely different script system and language, so their browser needs to be told properly how to render your words.
PDF can be much more tricky. Most documents still being written to PDF files adhere to older versions of the PDF standard which may not cross encoding schemes intact. Although you can try fiddling with the codepage and character set, it is usually simpler to export the contents as text and work on those using codepage and text tools. Ultimately you may have to obtain a freshly-generated PDF using more modern settings and proper encoding.
When creating your own PDFs, opt if you can for the most recent version of PDF, and for Unicode encoding, when you have such controls. Archival work should comply with PDF/A-1a or /A-2u at the least, to ensure that every character stored must have a Unicode equivalent.
Sometimes the problem lies not so much with the text encoding, but in the lack of suitable fonts to support that text. If you are struggling to find the right font, try DejaVu which has almost universal cover of Unicode characters.
Some of the worst problems remain with documents created in Eastern Bloc countries, which often used unique codepages tied to certain fonts produced by local foundries. To get those to render correctly, you may need to install the original font. Sometimes it is simpler just to scan in a printed copy of the document and use OCR, or cheaper to get the document retyped straight into Unicode.
What is the best text editor to use for this?
There are probably more text editors available than any other class of app. Apple’s bundled TextEdit will work with plain text and RTF, but is neither particularly powerful nor designed as a serious text tool.
The most professional tool for working with plain text remains BBEdit, or if you are really not prepared to pay, its free sibling TextWrangler. The former can do almost anything possible with text of whatever format you care to throw at it, and you can script and customise it to your heart’s content.
Additional resources
Wikipedia on ASCII, Unicode, codepages (with extensive listings of codepage designations).
Alan Wood’s Unicode resources.
The Multilingual Mac Blog.
