
If you use an Apple silicon Mac, you’ll be aware that it uses its Efficiency (E) and Performance (P) cores differently, and you may have seen how identical tasks running exclusively on its E cores generally take longer than those running mostly on its P cores. For over a year I’ve been trying to get a better understanding of what underlies this, and how macOS decides which core type to run threads on.
While it’s easy to become overwhelmed with detail, the broad rules appear based on the Quality of Service (QoS) assigned by apps to the threads they create:
- Threads with the lowest QoS, ‘background’ or 9, or lower, are normally run exclusively on the E cores.
- Threads with higher QoS, which range up to ‘user interactive’ at 33, can be run on either core type, but are normally run on P cores when they’re available.
The QoS set by an app is moderated by macOS, whose internal QoS metrics are more subtle and flexible.
This is supported by the following comment in the source code of sched_amp_common.c in the Darwin kernel:
“The default AMP scheduler policy is to run utility and by [that should I think be ‘bg’ for ‘background’] threads on E-Cores only. Run-time policy adjustment unlocks ability of utility and bg to threads to be scheduled based on run-time conditions.”
Neither the developer nor user appears to have access to any facility to adjust run-time policy, though, and force background threads to be run on P cores to any significant extent.
Methods
Investigating this isn’t easy. I have relied primarily on measuring the performance of test threads, with the support of sampling measurements using powermetrics. For visualisation, I have shown CPU History windows from Activity Monitor, while documenting the shortcomings and misrepresentations they contain.
This article extends those to look specifically at differences seen between E and P cores, and how this changes in lightweight virtualisation.
My test threads are coded in assembly language, and consist of tight loops that only access registers. Although those used here consist of floating-point calculations, I’ve shown that they behave the same as others using only integer instructions, others including NEON instructions, and using Accelerate calls.
These aren’t intended to simulate normal working threads, but to estimate a core’s maximum instruction throughput with instructions that don’t rely on memory or disk access, or other out-of-core features that could constrain execution. Before we can start to study more complex threads, we need to understand what happens in simpler cases.
For these tests, I show results obtained from running:
- Tight floating-point loops in my app AsmAttic,
- native in macOS 13.0.1 on a Mac Studio M1 Max,
- and in a four-core macOS 13.0.1 virtual machine using my virtualiser Viable.
- Test compressions and decompressions of a 1 GB file using my app Cormorant, native and in a VM.
For AsmAttic tests, I ran 1-4 threads each running the same number of loops of test code, measuring total time taken using the Mach clock. These were run at a background QoS, and at the maximum ‘userInteractive’ setting.
Results
As shown previously, there’s a strong linear relationship between the number of threads (T) and the rate of loop execution (R, loops/s) on the host at high QoS, which was essentially identical to that in the VM. However, in the VM the relationship was almost identical at low QoS too. Regression equations obtained were:
- Host QoS 33: R = (1.411 x 10^7) + (1.4784 x 10^8).T
- VM QoS 33: R = (1.3628 x 10^7) + (1.4717 x 10^8).T
- VM QoS 9: R = (1.2246 x 10^7) + (1.4696 x 10^8).T
Thus, in those three conditions, each thread was executed at approximately 15 x 10^7 loops/s. These are shown in the graph below, where the upper solid line represents the first of those three regressions, and the three sets of points are very closely clustered along that.
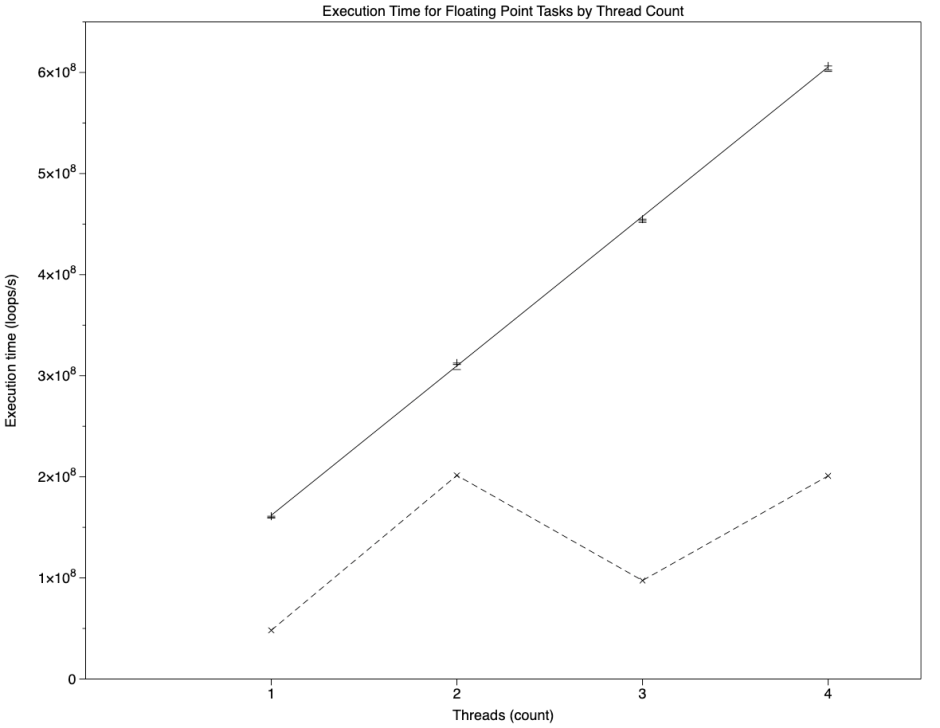
The lower broken line shows matching results when running the same test natively on the host at a QoS of 9, which could hardly be more different. That series shows the following:
- a single thread ran at 4.8 x 10^7 loops/s, one third of the rate of a single thread at high QoS, completing in 20.8 s;
- two threads ran at 20 x 10^7 loops/s, just over four times the rate of a single thread at low QoS, completing in 9.9 s;
- three threads completed in 30.8 s, close to the sum of a single and two threads, 30.7 s;
- four threads completed in 19.9 s, close to twice that of two threads, 19.8 s.
Separate measurements using powermetrics demonstrate that, when running a single thread in this test, the two E cores ran at a total of 100% active residency and a frequency of 972 MHz, but running two threads (at double the total active residency) their frequency is 2064 MHz, 2.1 times the lower frequency.
Explanation
When run natively on the host at high QoS, test threads were run exclusively on the P cores, as they were when run in the VM regardless of the QoS, at roughly three times the speed of a single thread on the E cores. Because threads with high QoS can still be run on E cores, that doesn’t mean that high QoS threads will only be run on P cores, though: I have previously shown how, with increasing numbers of high QoS threads, some will be run on E cores, and macOS can migrate threads from P to E cores as it sees fit.
When run natively on the host at low QoS, test threads were run exclusively on the E cores. However, the frequency of E cores is adjusted according to the number of threads being run on them. When a single low QoS thread is being run on the two E cores in an M1 Pro or Max chip, both E cores run at a frequency of 972 MHz. When two low QoS threads are being run, frequency is increased to maximum, 2064 MHz. This enables the E cores to complete test threads in half the time.
When more than two threads of low QoS are run on two E cores, they are despatched so that two threads are run concurrently at 2064 MHz. When the number of threads running on the two E cores falls to one, core frequency is reduced to 972 MHz again to complete that single remaining thread.
More complex threads
For tests using core-bound code, the above appears to hold good when extraneous tasks are light and don’t affect the availability of cores. The situation also becomes more complex for code in which out-of-core resources may limit performance. This is illustrated by results from test compression and decompression using Apple Archive, called in the API from Swift.
Time required to compress and decompress a test 1 GB file when running native on the host Mac was greatly influenced by QoS:
- At a QoS of 33, compression took 0.56 s, and decompression 0.27 s.
- At a QoS of 9, compression took 4.4 s, and decompression 0.72 s.
Thus compression took nearly 8 times longer at low QoS, and decompression only 2.7 times as long.
When run in a VM, both compression and decompression took 1.3-1.5 seconds regardless of QoS. That was significantly faster than native compression at low QoS, but slower than native decompression at low QoS, and slower than both at high QoS. Uniformity of time taken in the VM suggests that rate was limited by another factor, in this case almost certainly the speed of writing the output file to the VM’s virtual disk.
Summary of conclusions
- When running natively on Apple silicon chips, macOS allocates threads assigned QoS of ‘background’ (9) and below to be run on the E cores. While macOS may be able to adjust that at run-time, neither the developer nor user appears able to change that.
- Threads assigned higher QoS can be run on either core type, but when available P cores are normally preferred.
- Threads containing the vCPUs of a lightweight macOS Virtual Machine are normally run at higher QoS, and are therefore normally preferentially run on P cores when available. Each vCPU is normally run as a single thread on the host.
- When run in a VM, QoS in the guest isn’t used to determine core type allocation, which is subsumed to that of the higher QoS used by the host.
- Thus core-intensive threads normally run at low QoS can see significant performance improvements when run in a VM. However, threads whose performance is constrained by out-of-core factors, such as disk writes, may not show improvement in performance when run in a VM.
- Substantial differences in performance resulting from QoS settings are likely to vanish when run in a VM. This can result in anomalous behaviour in VMs, where threads with low QoS may run as if they had high QoS.
- You can game the core type allocation system by running tasks in a VM.
- Despite the substantial differences in performance of the E cores depending on the number of threads they’re running, trying to game their frequency behaviour is unlikely to prove successful.
I’m very grateful to Saagar Jha for his criticism and pointers, even though I’m sure he still considers this to be grossly oversimplified.
