

The world is full of laws which no one has to enforce, because that’s just the way things happen. Some, like Sod’s Law (or Murphy’s Law if you prefer), ensure that cock-ups occur consistently. Others, like Newton’s Law of Universal Gravitation, keep our feet on the ground. In most cases, explaining why the laws of life work is far more complex, and many seem even less rational or explicable than the laws of humans.
One of the stranger laws is that ascribed to George Kingsley Zipf. Published by him in a book entitled The Psychobiology of Language back in 1935, and further detailed in his later book on ‘human ecology’ (1949), he never claimed to have invented it himself.
Zipf’s (basic) law states that, across a corpus of natural language, the frequency of any word in that corpus is inversely proportional to its rank in the frequency table.
So the most frequent word, ranking first in the frequency table, sets the frequency for all the other, less frequent words. The second most frequent word is half (1/2) as common as that, the third is one-third (1/3) as common, and so on. This is readily seen in the two graphs, the first of which uses normal linear scale in its axes, and the second uses logarithmic scales, which transforms the curve into a straight line.
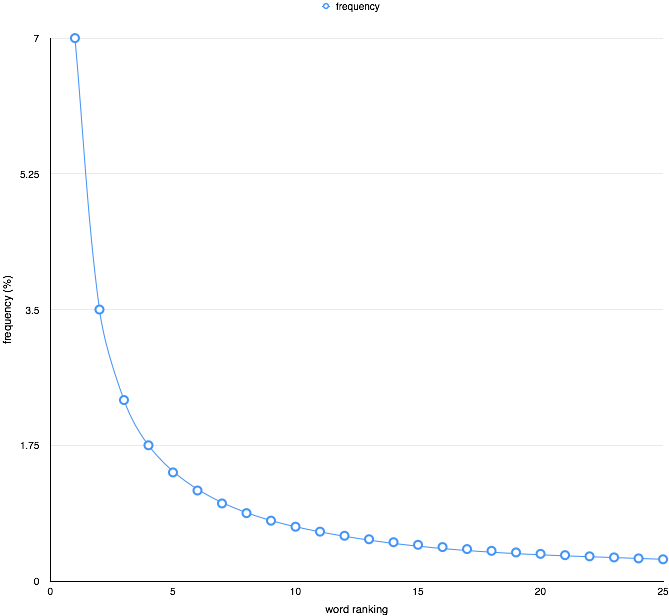

The most generic form of Zipf’s law makes one small change to this basic version: instead of using the raw rank in the frequency table, it uses a power of that. For the basic form, the power is 1, and allowing that to change slightly allows better fit in an even wider range of cases. This is readily seen when the line of best fit in the log-log graph has a different gradient.
This is odd, because natural language is generally so irregular and has so few universally-applicable laws, but seems to comply with that of Zipf remarkably well. Things turn decidedly spooky when you see how many unrelated phenomena also seem to follow the same law: population ranks of cities, sizes of businesses, income rankings, and so on.
There have been many and varied attempts to explain how this law comes about, but so far no explanation has stood up to careful scrutiny. Because it is so pervasive and applies to data without deep structure, it is tempting to suggest that it is merely a statistical phenomenon and does not have any deeper significance. However it seems so ingrained in language that it appears systematic rather than stochastic.
A recent paper (PDF version) by Álvaro Corral and others in Barcelona, Spain, published in the open access online journal PLoS ONE has taken Zipf further than mere words. Using ten of the longest novels written in four very different languages, English, French, Spanish, and Finnish, Corral et al. found that the law works for linguistically-massaged versions of texts too, in particular for lemmas of words (roughly, word roots) too.
The languages that they chose are in stark contrast to one another: Finnish is a highly inflected language in which cases do much of the work that is, in English, accomplished by prepositions and other common little words. Spanish and French do not inflect as much as Finnish, but do so more than English.
Converting each text into these lemmas has a major effect. The authors give the example of the words based on house in James Joyce’s Ulysses (itself a very unusual and long piece of English prose). The word houses appears just 26 times in the whole text, but its lemma (root) house, which includes occurrences such as house, houses, housed, and so on, appears 198 times.
In a highly inflected language such as Finnish, lemmatisation would map every inflection, including to the house, at the house, and so on, thus work very differently from its effects in an uninflected language like English. This is illustrated by the fact that one Finnish lemma, olla, maps to more than 100 different words, and even in Spanish verb paradigms can map to almost 50 words.
There is a lot of fascinating detail in the paper by Corral et al. which you can discover for yourself, if so interested. But the bottom line is that the words and their lemmas (roots) in each of these ten different novels, across four contrasting types of language, come very close indeed to fitting Zipf’s law.
So Zipf’s law seems very deeply embedded in language, and pervades many utterly non-linguistic data. We still do not understand why.
