
Searches too often return nothing of use, or too many irrelevant results. When we have partial information about our target, one valuable way to refine a search is to use a regular expression, or regex. Say you’re looking for a name in a huge file containing tens of thousands. You know the name starts with Chap or chap, and ends with the letter n, but can’t recall whether it’s Chaplin, Chapman, or something similar.
Regex support
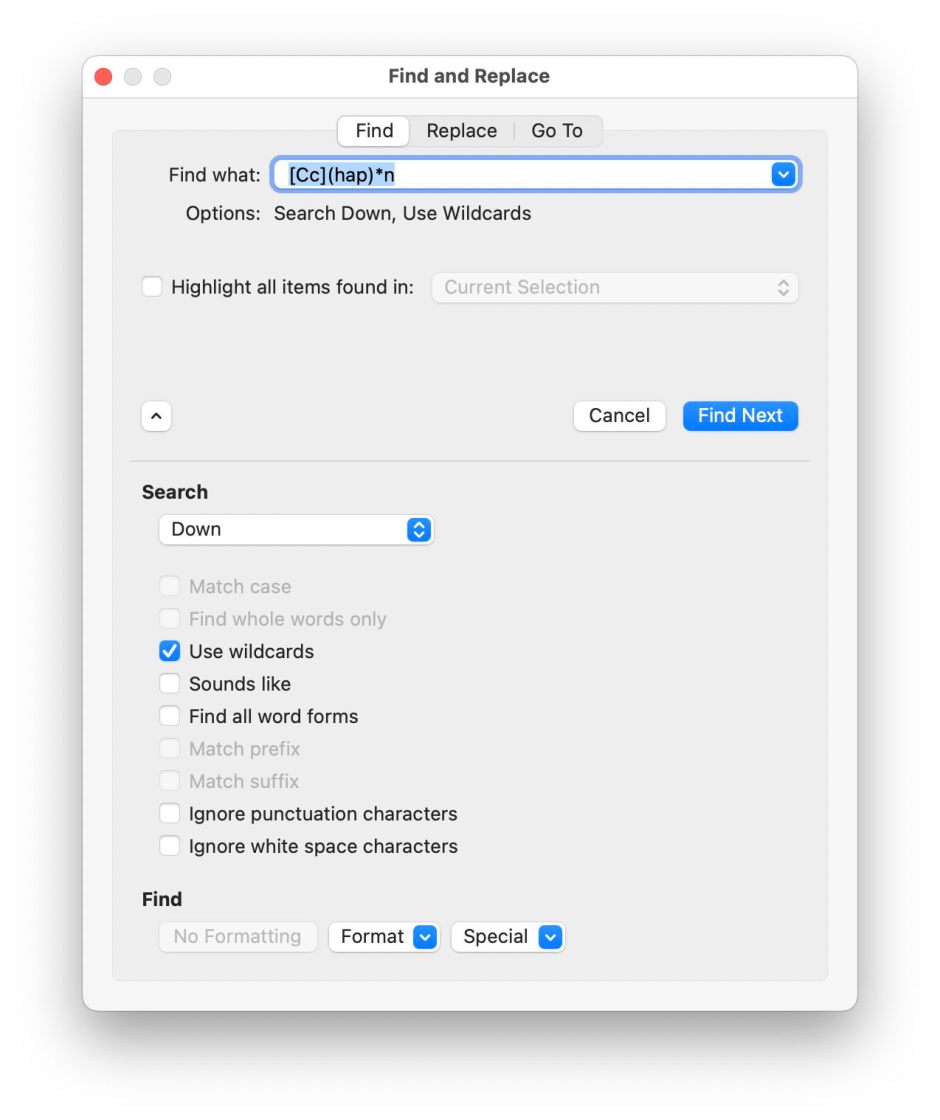
In Microsoft Word, use the Edit menu, Find item and select the Advanced Find and Replace… command to display the Find and Replace dialog. Open its extended options by clicking on the disclose button at the lower left of that dialog, and check the Use wildcards option to engage its limited and idiosyncratic regex mode. Enter <[Cc](hap)*n> and that should find the name.
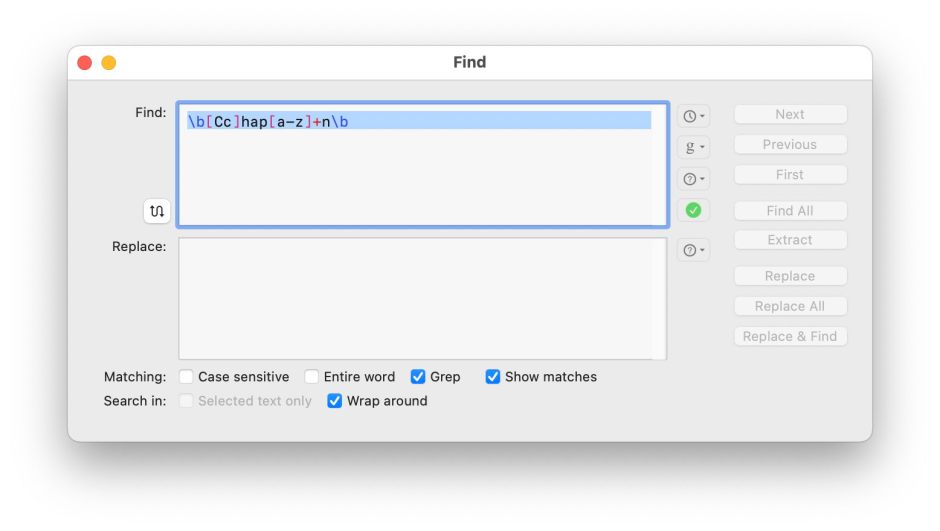
In BBEdit, a whole menu is devoted to Search: use its first command, Find…, and in the Find dialog, ensure the option for Grep is checked. BBEdit goes even further now, with a whole Pattern Playground for you to fine-tune your search patterns too. It also supports more regular regex, with \b[Cc]hap[a-z]+n\b to find the name here.
You should find similar support in every self-respecting text editor. Nisus word processors have always included sophisticated search and replace functions with good support for regex. To some degree or other, it’s also available in most scripting languages, including PHP, Perl, Python, Tcl, Ruby, and Java, and some command line tools such as grep.
Basic expressions
Core terms used in regular expressions aren’t hard to learn or use.
Single characters can be matched in several ways:
- you can give an explicit character,
- a dot
.to denote any character at all, - a character class specified in square brackets, such as
[a-z]for the lower case alphabet, - or a special character prefaced by the escape character
\, such as\*for a literal asterisk. Characters which must be quoted in this way to be treated as those characters include* ? + [ ( ) { } ^ $ | . /
Those single characters can be multiplied using quantifiers:
?for 0 or 1,*being any number including 0,+meaning 1 or more,- or if you wish to be more precise about numbers, you can specify a number or a range inside curly brackets, such as
{3}or{2,5}.
The other major class of core terms provides positional specification:
- a caret
^matches positions at the start of lines, - a dollar
$at the end, \<at the start of a word,- and
\>at the end; - a common alternative to the latter is to employ
\bto denote work breaks; - when enclosed in square brackets, a caret has a different meaning, that of negating the character class: for instance
[^a-z]means any character except those in the lower case alphabet.
There are also some miscellaneous terms that are both important and in wide use:
- the vertical bar
|means ‘or’, and allows matching to either of the regular expressions that it separates, - normal parentheses
(and)are used to limit the scope of expressions, for example each side of|, - and you may be able to refer back to text matched within the first or subsequent set of parentheses using escaped references such as
\1,\2, and so on.
Escape characters are used widely in different programming languages and systems, and are fairly standard:
\tis a tab,\nnewline,\rcarriage return,\sany whitespace character including space, tab, and newline,\wis any alphanumeric character or[a-zA-Z0-9_],\Wis anything not\wor[^a-zA-Z0-9_],\dis any digit, or[0-9].
Dave Child provides an excellent printable cheat sheet to regular expressions here that summarise those and others. The definitive reference to ‘standard’ ICU regex, that built into macOS, is here.
Phrases and more
Just as in natural language, as you use regular expressions you’ll discover and develop phrases that are effectively idioms. RegExLib.com has now collected more than four thousand different idioms, drawn from a wide range of applications.
These can be as simple as ^.+@[^\.].*\.[a-z]{2,}$ (by Thor Larholm), or as complex as ^([\w\-\.]+)@((\[([0-9]{1,3}\.){3}[0-9]{1,3}\])|(([\w\-]+\.)+)([a-zA-Z]{2,4}))$ (by David Lott), both of which match email addresses with differing degrees of specificity. Long and complex regular expressions can be daunting at first, but are worth parsing out on paper, term by term, breaking them down into smaller parts so that you can see how they are assembled into the working whole.
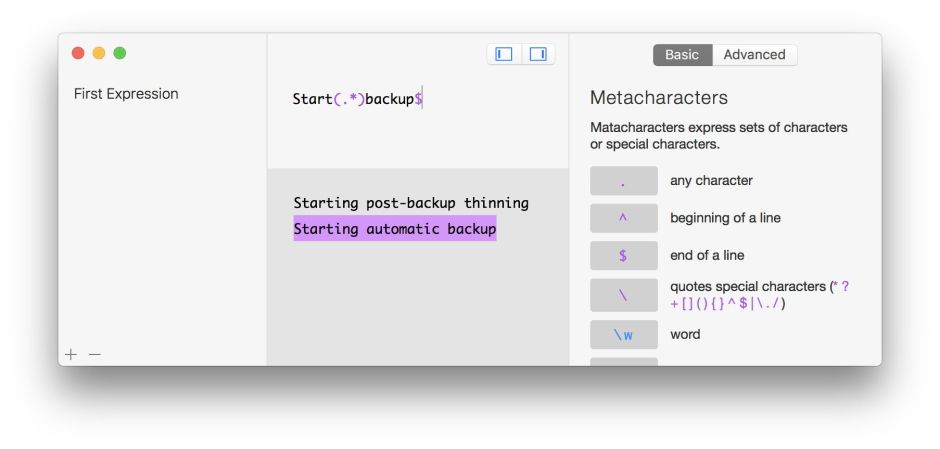
Terse languages that aren’t easy to understand are best developed interactively, using an environment that allows you to assemble, test, and debug its code. In addition to BBEdit’s playground, there’s no shortage in the App Store, ranging in cost from free to over $/€/£10. My current favourite is Expressions featuring a pleasant interface and the full ICU reference.
Regular expressions tend to be more ephemeral than more formal programming languages, in that you often deploy them in one-off circumstances, perhaps when looking for a particular file. Despite that, they’re worth investing time and care over, perhaps using a testing tool to get it right, and then to record your regex in your own idiom library. If novel and of more general use, submit it to RegExLib.com for others to discuss, rate, and deploy.
The outright winner when it comes to unusual applications of regex must have been Le Decroiseur, sadly now discontinued, a crossword tool that let you search English and foreign language dictionaries using regular expressions, to aid in setting or solving crosswords, playing Scrabble, and other word games.
Dialects
You also need to know which terms and conventions are available in the particular implementation of regular expressions that you’re using. Extensive information and tutorials are available at Regular-Expressions.info. Occasional users may find these helpful to solve specific problems that they may come across: if they seem a bit geeky, remember that regex is a form of programming language, and there are plenty of people who spend of lot of their working days developing and using them.
By now, you should be happier making your searches and scripts more powerful using regex, and less scared of these advanced search features. Use these thoughtfully to refine searches: it’s better to invest a few minutes thinking out how to refine a search to make it more effective. That small investment of time will be repaid handsomely in the time that it saves you trudging through pages of dross that would result from something less focussed.
