
Unicode is an epitome of human achievement: a brilliant idea that has grown out of control to the point where no human can grok it all any more. I sometimes wonder how many of its 149,813 ‘characters’ any one human is likely to use, and suspect for most that’s in the low hundreds or less. All those ‘characters’ enable deliberate misuse, where visual similarities are exploited to spoof people over identity or worse. Let me explain how you can get Unicode revenge without harming a soul.
We still do a great deal in life using text that can be searched rapidly and readily. Sometimes it pays to obfuscate that so that only humans reading it will understand what it says. Whether it’s an eavesdropper bulk-scanning emails, or someone’s AI crawler building your words into its next Large Language Model (LLM), you can make their task inconveniently difficult by recasting its Unicode. For example, the following obfuscated version of a paragraph from one of my recent articles reads clearly to the human eye:
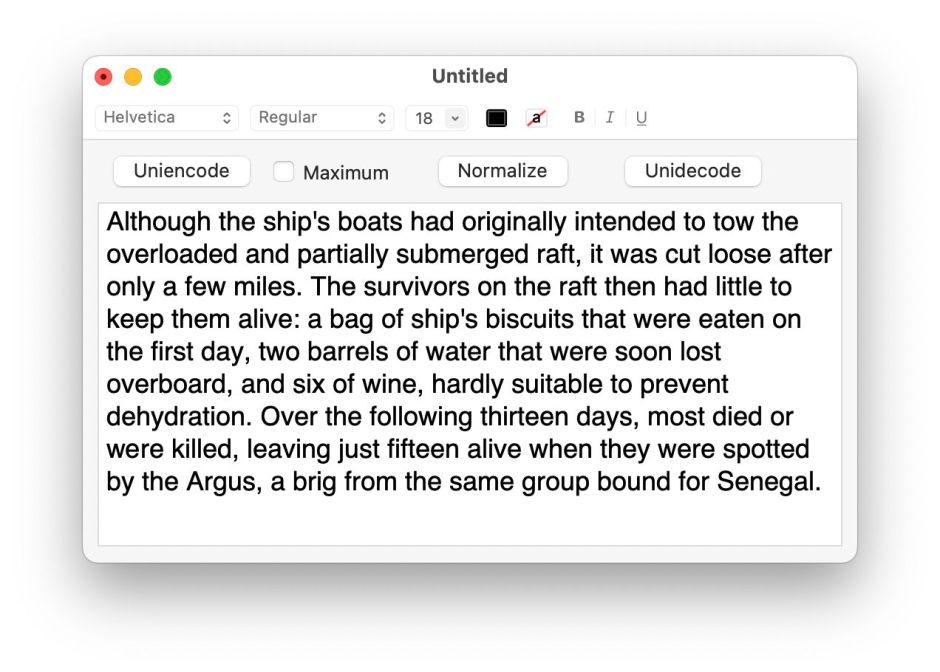
But look more closely at those characters, like
Αlthоugh thе shір's bоаts hаd оrіgіnаllу іntеndеd tо tоw thе оvеrlоаdеd аnd раrtіаllу submеrgеd rаft
Those aren’t what they seem, and on ordinary text searches will draw a blank.
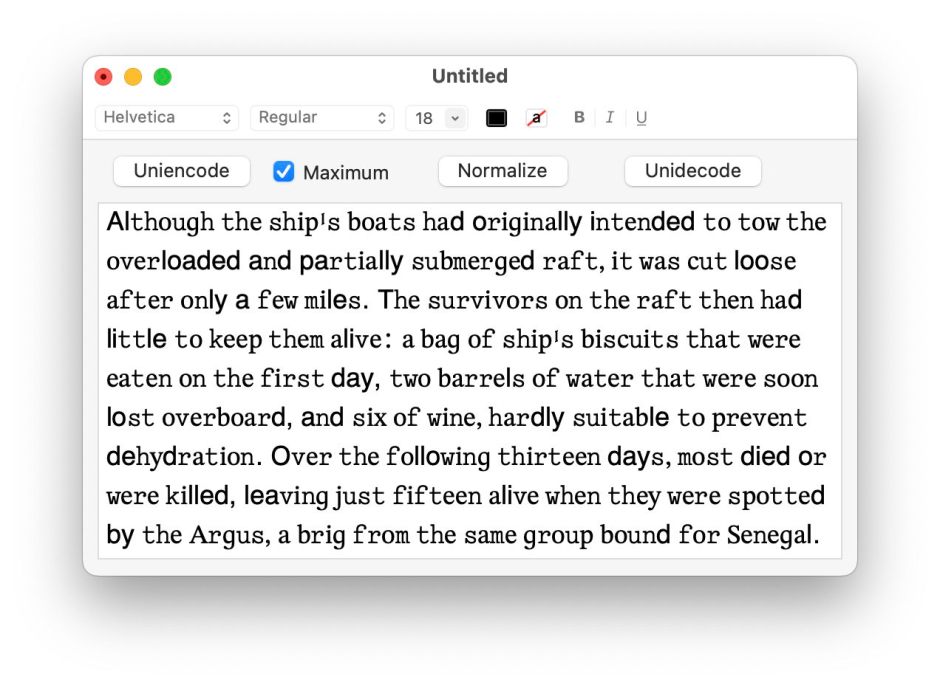
Apparently, some searches now make allowance for that degree of light obfuscation. To make things far harder for them, try the more extreme
Αⅼ𝚝𝚑о𝚞ɡ𝚑 𝚝𝚑е 𝚜𝚑ірᛌ𝚜 bоа𝚝𝚜 𝚑аⅾ о𝚛іɡі𝚗аⅼⅼу і𝚗𝚝е𝚗ⅾеⅾ 𝚝о 𝚝о𝚠 𝚝𝚑е о𝚟е𝚛ⅼоаⅾеⅾ а𝚗ⅾ ра𝚛𝚝іаⅼⅼу 𝚜𝚞b𝚖е𝚛ɡеⅾ 𝚛а𝚏𝚝
which remains thoroughly understandable to humans, but makes most machines give up in confusion.
There are now ways around this obfuscation. Apple’s Live Text does an excellent job of recognition on both those screenshots, but that extra mile of converting all your obfuscated text into images, then using text recognition on them isn’t something that many will try, and it imposes a significant computational burden on the eavesdropper or crawler.
Obfuscation is of course no substitute for encryption: if the text contains secrets that you don’t want others to see at all, then you must encrypt it using a robust method. But for holding off those who are just going to use normal text searching, it should be effective.
Almost seven years ago, I wrote a little utility for obfuscating Latin text at the two levels shown above. Dystextia is fairly basic, but runs a treat in macOS from Sierra to Sonoma. You can also use it to obfuscate shorter sections of text. While Internet domains that include non-standard characters are converted into ‘Punycode’ that makes them difficult to spoof, the rest of the URL is left in its original Unicode, thus preserving any obfuscation.
Perhaps it’s time to see whether you can use Unicode’s code points to conceal other text in steganography.
