
So far my investigations of the performance of the Efficiency (E) and Performance (P) cores in M1 chips have been confined to running multiple threads in a single app. In the real world, processors are more usually running multiple processes which contend for resources including CPU cores. This article looks at how contention works out depending on the Quality of Service (QoS) assigned to different threads.
Model and methods
Two different apps are used here to compete for CPU cores: my free Cormorant streams files to compress (and decompress) them using multithreaded lossless compression in Apple Archive; my AsmAttic test utility runs tight CPU-bound loops of assembly code, as I’ve explained before. Both apps run their threads in Grand Central Dispatch queues with Quality of Service values set by the user for each test. AsmAttic also sets the number of threads and the number of loops in each thread.
Tests were run on two M1 Macs in Monterey 12.2. One, referred to as M1 mini, is an M1 Mac mini 2020 with 16 GB memory, an internal 500 GB SSD and the original M1 chip with one cluster of 4 E cores and one of 4 P cores; the other, referred to as M1 Pro, is an M1 MacBook Pro 16-inch 2021 with 32 GB memory, an internal 2 TB SSD and the M1 Pro chip with one cluster of 2 E cores and two clusters of 4 P cores each. By all expectations, running either of the test apps would be expected to demonstrate better performance on the M1 Pro compared with the M1 mini.
Additional tools used to examine performance include the powermetrics command tool and Activity Monitor’s CPU History window.
Uncontended performance on E and P cores
Before looking at the effects of contention on performance, I first looked at the two tests I intended to use in contention, running at the highest and lowest QoS levels.
Time to compress a 10 GB test file at highest QoS (33) was shorter on the M1 Pro as expected. The task completed in 5.6 seconds on the M1 Pro, and 8.2 seconds on the M1 mini. At this QoS, each test resulted in all available cores being recruited at their maximum frequency, and 100% active residency, according to powermetrics.
When compression was performed at minimum QoS (9), the M1 mini consistently completed the test in a shorter time than the M1 Pro. While the M1 Pro took 55.1 seconds, the M1 mini accomplished the same task in only 37.3 seconds. I have previously reported that, when running tests on the M1 Pro’s two-core E cluster, cores are run at higher frequency than when running the same test on the M1 mini’s four-core E cluster, and that was seen here too. When the M1 Pro was running the compression test solely on its two E cores, their frequency was 2064 MHz, while the four E cores in the M1 mini ran at a frequency of only 972 MHz. Despite that difference in frequency, the M1 mini required just 68% of the time taken by the M1 Pro.
To confirm that this wasn’t the result of Cormorant being built for an older version of macOS (Big Sur), I built and notarized a new version using Xcode 13.2.1. Using that new version, times observed were unchanged, and the M1 mini remained significantly quicker at compressing on its E cores alone.
Results from the floating point test were consistent with my previous observations, that the two E cores in the M1 Pro are run at higher frequency to compensate for their number, resulting in better performance on the M1 Pro regardless of QoS. At the highest QoS, 10 threads completed on the M1 Pro in 3.6 seconds, while 8 threads took 4.0 seconds on the M1 mini. At the lowest QoS, 2 threads on the M1 Pro completed in 5.1 seconds, and on the M1 mini in 10.3 seconds, essentially the same time it completed 4 threads. High QoS resulted in E and P cores being run at their maximum frequencies, but at low QoS the two chips differed: the M1 Pro ran its two E cores at 2064 MHz, but the M1 mini ran its four E cores at 972 MHz.
Contention on E cores
When tested with contending processes and threads confined to the E cores by the lowest QoS, there were no surprises. With the difference in performance times of the two tests used, each run started with the compression task, then the floating point test was added to that and completed before the end of compression.
Adding only two floating point threads, the M1 mini completed compression in 42.4 seconds, with the floating point test taking 11.9 seconds within that; the M1 Pro completed compression in 63.2 seconds, and the floating point test took only 8.8 seconds. While the E cores of the M1 Pro were run at a frequency of 2064 MHz, even with both tests running concurrently the four E cores in the M1 mini remained at only 972 MHz.
Total elapsed time, within which both compression and floating point tests were completed, was shorter for the M1 mini with four floating point threads (47.9 s) than the M1 Pro running only the compression task (55.1 s).
Contention at intermediate QoS
Apple defines four QoS levels, numerically 9, 17, 25 and 33, of which only one (9) results in threads being constrained to one type of core. Threads at each of the three higher QoS can be run on either E or P cores, depending on allocation by macOS. When looking at the effects of different QoS it’s easy to conclude from uncontended testing that there’s little difference between those three levels. To get a better insight, I ran floating point tests at various QoS against compression at a QoS value fixed at 25, using just the M1 Pro.
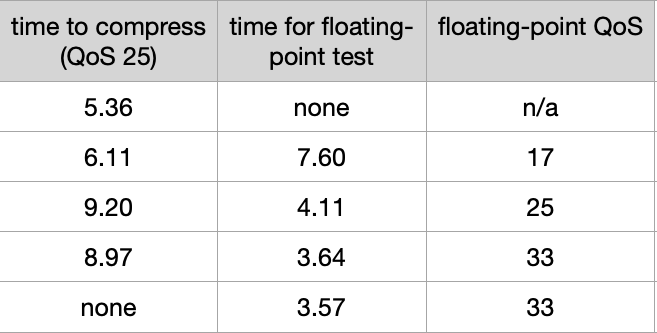
The table above gives, in the first column, the time in seconds for the compression task to complete. The second column gives the time in seconds for the concurrent floating-point test to complete, with its QoS given in the final column.
This shows the interaction between threads at different QoS levels. When the competing floating-point task has a lower QoS than the compression task, compression is only slowed slightly, and the time required for the floating-point task is more than doubled. When the floating-point task QoS exceeds that of compression, the former takes little longer than it does when run alone, and the compression task takes nearly twice as long.
While there are no surprises here, this demonstrates that allocating queues and threads an appropriate QoS is important even when using the three higher levels, which don’t constrain threads to E cores.
Conclusions
- Although processes and threads run on both E and P cores complete more quickly on the M1 Pro, when constrained to the E cores some are significantly quicker on the M1 mini. This occurs despite the difference in frequencies of the E cores when running threads at the lowest QoS.
- M1 mini and Pro chips run their E cores at different frequencies when running threads at the lowest QoS. The four cores in the M1 mini cluster are then constrained to 972 MHz, while the two cores in the M1 Pro cluster may be run at their maximum frequency of 2064 MHz. Code dependent on resources outside the cluster may still run more slowly on the M1 Pro despite that difference in frequency.
- Contending threads from different processes are run concurrently on the core types to which macOS allocates them. Those at the lowest QoS are never run on P cores, even when the E cores are already fully loaded but the P cores are idle.
- When run at any of the three higher QoS levels, macOS allocates priority to threads according to their QoS, so that those with higher QoS are given higher priority than those with lower QoS. Assigning an appropriate QoS to threads is therefore important in determining overall performance, particularly when threads are in contention with others. As a result, assessing performance without contention can be misleading.
- Understanding core allocation and the interaction of QoS levels under contention are essential to achieving optimal app performance on Apple Silicon Macs.
