

Marc had quite a good-quality scan of a book written in French, which had undergone Optical Character Recognition (OCR) to turn its contents into accessible text. But something had gone badly wrong: anything which tried to access that text failed dismally. Why was that, and how could he access that text content?
The PDF he provided was quite compact at 14.5 MB for 161 pages, and claimed to have been written using an old version of the Debenu Quick PDF Library, now owned by FoxIt, and encoded using the current release of PDFKit and its Quartz 2D engine. But when I tried to open it in Podofyllin to inspect its source, it took an age. Clearly something wasn’t right with the PDF within the document.
Sure enough, when it finally opened there wasn’t a single character of text to be seen. Looking at the source, the PDF had been written incrementally too, with the bulk of it being created in a first pass, and a second set of modifications performed afterwards but not incorporated into changes in the original, instead being tacked on at the end.
It was time to look at what Adobe Acrobat Pro made of it.

As in Podofyllin, the PDF looked beautifully accurate, but any attempt at retrieving text content from it was doomed to fail. When I tried to export it to Rich Text from Adobe’s flagship PDF editor, all I got was utter gibberish, with barely a word being intelligible. In the entire 161 pages.

As the page images looked good, but the OCR appeared to have been badly mangled, the best way ahead was to pass it through a better OCR app. My current choice is between FineReader OCR Pro and its predecessor ABBYY FineReader Express, both purchased through the App Store. Although the first is the more recent, its interface isn’t as straightforward. However, you can use either in this case.
For FineReader OCR Pro, this process is initiated by importing images to a new document, and it’s important, knowing that the text is in French, to set that as the document language. ABBYY FineReader Express is rather simpler to use, but much slower, and being 32-bit isn’t going to last much longer with Catalina coming at us fast.
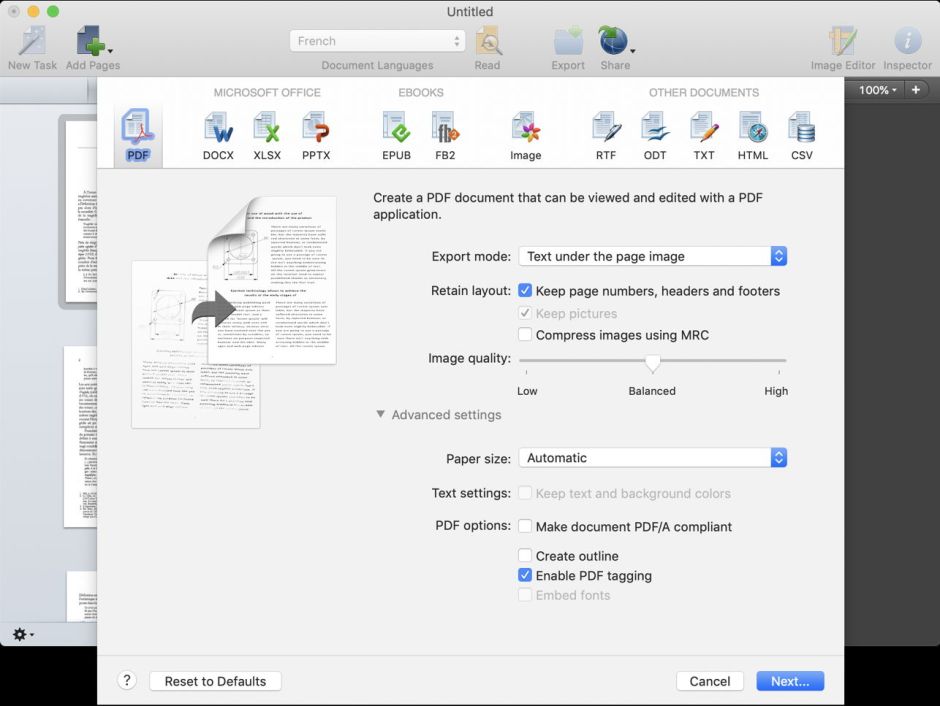
Once this second pass of OCR was done, I saved the document again as a PDF.
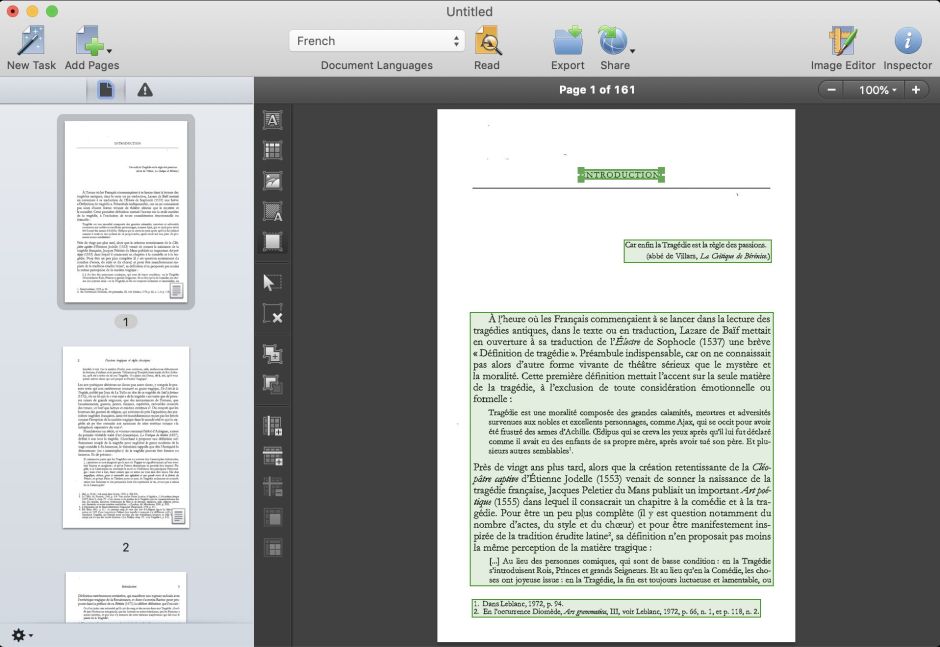
There’s a major disparity between the two versions of FineReader here: the older version wrote a file which was almost 90 MB in size, whereas the current version managed to squeeze the whole lot into only 6 MB.

Opening that PDF in Podofyllin is now very much quicker, and its contents have been rendered fully accessible, with nearly 80,000 words recognised and fully searchable.
I have no idea what went wrong with the OCR in the first instance, but suspect that it was expecting English not French, so it became horribly confused. If the scanned images of pages are of reasonable quality but text recognition has failed this badly, hand it to a dedicated multi-lingual OCR app and try that.
