
PDF is an ancient document format, introduced in 1993, when computers were far less capable, had much smaller storage and memory, and neither security nor privacy were particular concerns. This article demonstrates features in current PDF documents which make them vulnerable to various problems, in particular the unintentional release of private data – something which happens all too often.
Because these weaknesses are features built into the PDF file format, they affect all software which can edit PDFs, even apps like Preview which can’t alter document contents but only give access to annotations.
A basic PDF file consists of four main sections:
- a brief header which declares the PDF version used,
- the body, which is a succession of objects, which form the content of the document,
- a cross-reference table, which lists the locations of all objects in the body,
- a trailer, containing among other things the object identity of the Root object in the body.
PDF documents which have been written once, and neither been edited nor had annotations attached later, should normally follow that simple structure, but once changes have been made – just adding a single note – the structure becomes more complex as further sections are added incrementally. Those can include additions to the body, adding further objects, further sections of cross-references, and updated trailers.
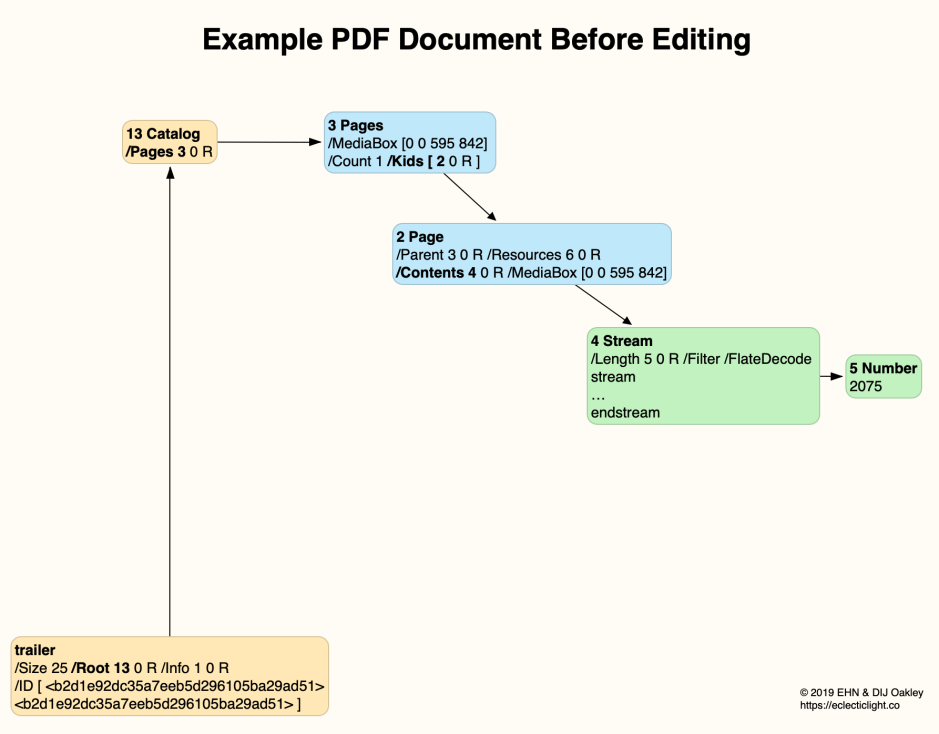
This diagram shows a very simple PDF document structure, with a lot of detail omitted for the sake of clarity. The trailer identifies the number of the Root object, here 13, which is the Catalog. That in turn identifies the Pages object as number 3, which gives object number 2 as the single Page, and that in turn references its Contents as object number 4.
Object number 4 is a stream of binary data which has been compressed, and rather than give its length direct, that is given in object number 5.
If we then open that document and delete all the text from that page, our PDF editor can do one of two things. It can rewrite the entire file with a modified version of object 4, or the file can be updated incrementally – which is the most common choice, if not universal among PDF editors.
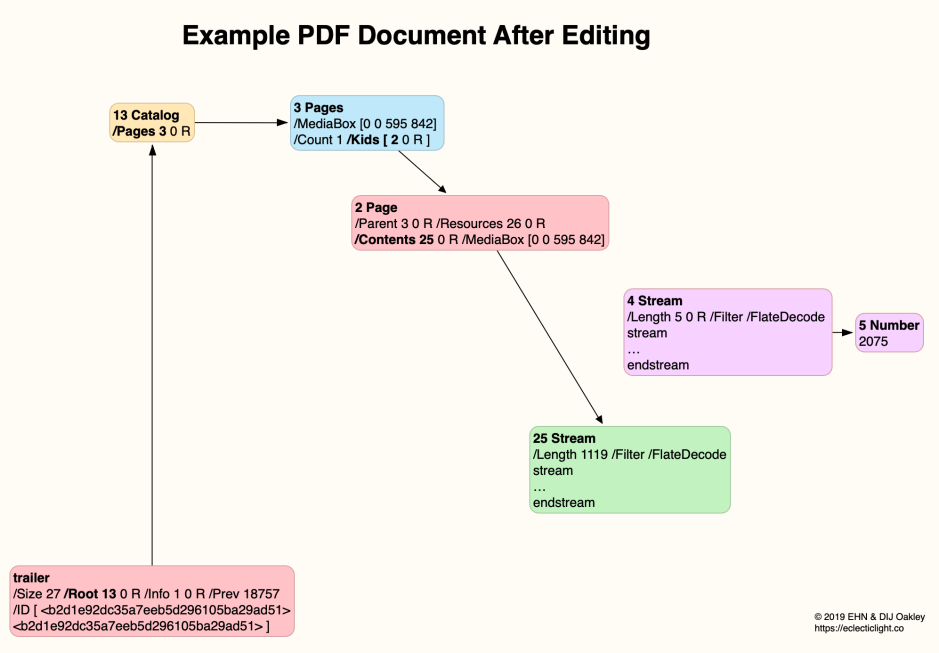
When updated incrementally, a new trailer is written out, which still points to the Root Catalog in object 13, which refers to the list of Pages in object 3. However, the single page in object 2 is now changed to use Contents in a new object, number 25. This is another compressed binary stream, which is significantly smaller than the original.
Because this is an incremental update to the file, the original content in object 4 is left in the file, together with its linked size object number 5.
That wouldn’t necessarily be a problem, except that all software which accesses that document does so using its Root object, the Catalog, which no longer knows anything about the old content in object 4. That old content vanishes from the displayed version of the document, and is inaccessible to apps which access the file in the normal way, through its Catalog. But use an app which can access objects directly, and the contents of the orphaned object can be recovered.
In that example, because the object involved is compressed binary, it’s hard to see just how serious this is. Here’s another example involving a deleted note which should make this clearer.
This test file consists of a single character, the German letter ß, on which I placed a note reading This is a test note.
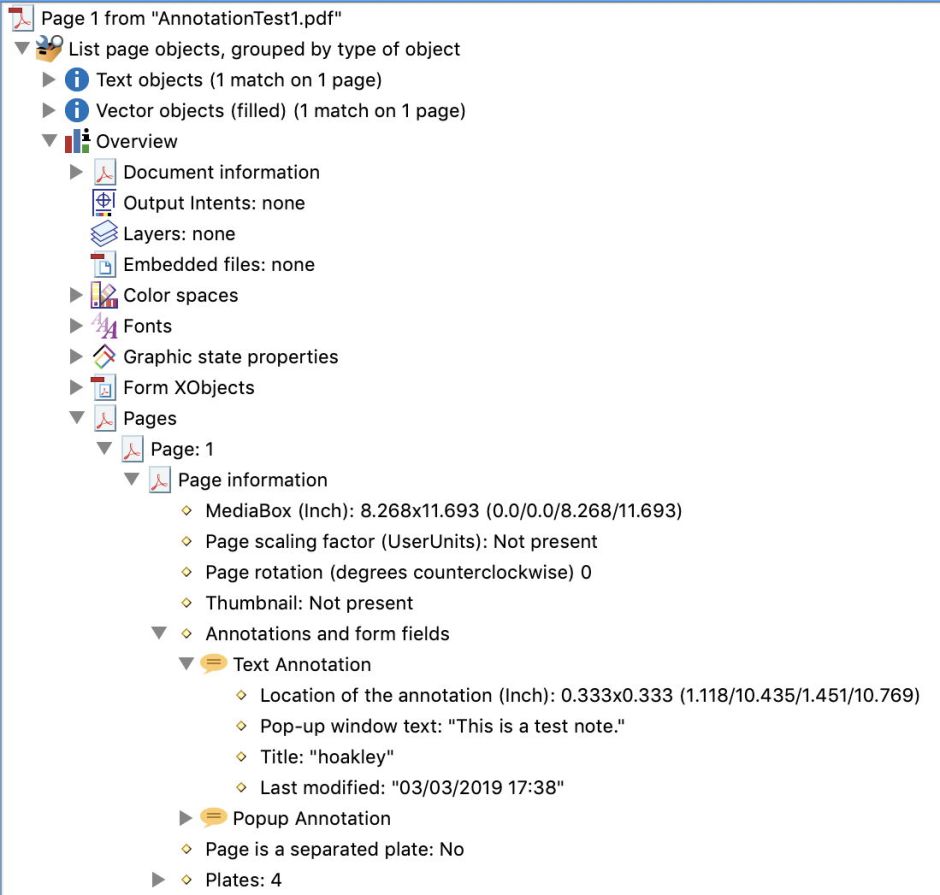
Seen in Adobe Acrobat (Pro) DC’s structure browser, this annotation is detailed as being attached to Page 1. Following deletion of the note, Acrobat claims that it has been removed from the page, as shown below.

Open that edited PDF using BBEdit, though, and object number 26 containing that annotation is still present and reveals its content and author.

Because the body of a PDF file can contain objects which aren’t linked back to the Catalog, accessing the document’s content through its Catalog ensures that orphaned objects remain invisible, even to the extensive features provided in Adobe Acrobat Pro. Such orphaned objects can include content which leaks secrets, or malicious code or material.
So far, all PDF software which I have examined, including PDFKit and Quartz PDF support (CGPDF) in Mojave, Adobe Acrobat (Pro) DC, and other apps on macOS, access PDF content through the Catalog, and don’t scan files for orphaned objects. That means discovering and examining orphaned objects isn’t easy, and requires forensic tools such as peepdf. It also means that it is almost impossible to check whether using Save As or ‘flattening’ a PDF has successfully stripped orphaned content.
More modern file formats, such as those using XML, shouldn’t be susceptible to the orphaning of content objects, as they are structured into dictionaries and arrays, in which all branches and leaves remain accessible from the document root. That doesn’t in itself guarantee unintentional leakage of content, but makes it much easier to check documents thoroughly. Perhaps the time has come to look for a successor to PDF which has similar strengths.
