
We all like wishlists, and we like most of all when they come true. The snag is that my wishlists are not the same as yours, and when it comes to Macs, there is little in the way of consensus.
Following Apple’s unusually frank discussions about the way ahead for Mac hardware, the last week has seen several significant articles about what pro users of various persuasions would like to see in the new Mac Pro, now expected for release in 2018. What has surprised me is the limited wishing which has been articulated for the new iMac, due sometime in the next six months or so.
Much as I think next year’s Mac Pro is important, this year’s iMac is an order of magnitude or more greater in significance.
When external buses were slow, and high-performance peripherals like drives were limited and expensive, expandible systems like the old and new Mac Pros had wide appeal. Most of us preferred a large external high-resolution display, and we were happy to sacrifice desk or floor space to a tower, display, and all the other bits and pieces that we needed. Most serious audio and video work required internally-mounted expansion cards. iMacs were low-to-middle spec systems which had nothing like the features that any serious – let alone pro – user required.
Hardware has moved on since then. With USB-3 and Thunderbolt, it makes far more sense to house your stack of drives separately, and those expansion cards have become unnecessary or have been replaced. The current iMac 5K display is superb, and occupies little more frontage or volume than a 5K display alone.
No matter how alluring the specifications of a 2018 Mac Pro, most of those to whom it might appeal are already using iMacs, and are more likely to buy a good new iMac this year – should Apple offer one – than to hang on in the hope that next year’s Mac Pro might be even better. And for every potential Mac Pro customer, there must be fifty or a hundred who will buy a good new iMac.
With the advent of Apple’s new file system later this year, high-end options for the new iMac should include more affordable SSD-only internal storage, such as dual 1 TB units.
To accompany the new iMac, many expect a new keyboard with its own Touch Bar. That could be an interesting challenge, because of its power requirements. Many users would not be happy switching back to a wired keyboard, but even with a Watch-class processor, battery endurance is likely to be a major consideration.
One possible solution, which also overcomes the physical constraints of the Touch Bar in the MacBook Pro, would be to merge the Magic Trackpad 2 with a Touch Pad: a rectangular touch-sensitive LED panel and trackpad in one. If Apple is going to respond appropriately to touch screens with novel input devices which are more usable, this is the sort of product that they need to bring to market sooner rather than later.
The other significant news last week was Xudong Zheng’s demonstration of Unicode spoofing with web addresses, which I discussed here.
This raises an important issue which Unicode does not adequately address: the consequences of its many near-identical characters. Humans use characters, from plain old ASCII to Unicode, to make distinctive labels. On computer systems, those labels are used to identify files and folders, and much else. Any character encoding system which allows multiple codes to be assigned to characters which are visually indistinguishable is steering us into danger.
It is not hard to come up with potential problems. All the following characters appear very similar, and most people would consider most of them to be functionally identical:
aa𝐚𝖺𝗮𝚊а
yet in Unicode, those seven characters are each encoded completely differently.
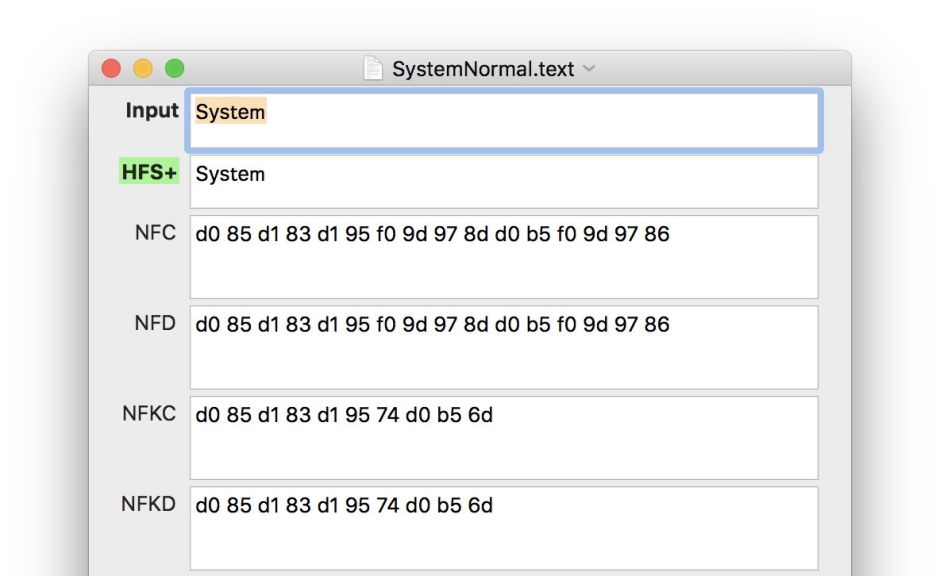
Unicode’s normalisation forms address this issue in a patchy and highly incomplete way. They recognise the problem, but do not deal with it effectively. The words Ѕуѕ𝗍е𝗆 and System are difficult to distinguish; in some widely-used fonts they are indistinguishable. Yet their encodings couldn’t be much more different: in UTF-8 hexadecimal, the first is d0 85 d1 83 d1 95 f0 9d 97 8d d0 b5 f0 9d 97 86, and the second merely 53 79 73 74 65 6d.
As shown above, the first version is unaffected by Normalisation Forms C and D. This means that even though we cannot see much (or any) difference, Linux and Mac HFS+ file systems will see those words as being different, and allow them to co-exist for different files or folders. Oddly, the KC and KD normalisations bring them closer together, but they retain distinctive encodings.

So you can apparently have three folders all with what appears to be the same name, side by side in one folder.

Sort them in alphabetical order in the Finder, and they appear jumbled. This is because compare, search and sort routines treat them as being different too.
This is precisely the sort of chaos that normalisation was intended to avoid. But because normalisation does not recognise that these characters are visually so similar, it is ineffective here.
There are no easy solutions to this problem. If we abandon the idea of normalisation altogether, then problems will occur. If we continue to rely on current flawed normalisation routines, then it is only a matter of time before other exploits are discovered which take advantage of this flaw. The best solution would be to extend and deepen normalisation to cover the whole of the Unicode character set, which is a daunting task.
The issue could, of course, have been avoided if the Unicode standard had not assigned multiple codes to visually indistinguishable characters, but I suspect that it is now far too late to consider fixing that.
