

There’s an excellent demonstration of a Unicode spoof going round at the moment. Click on a link which looks like it’s https://аррӏе.com and you’ll not end up seeing a page from Apple, but your eyes and your browser will have been diverted to a completely different site, which just looks the same in Unicode.
Visit that site and all the better browsers point out what has happened: instead of the address showing up as apple.com, it is displayed as https://www.xn--80ak6aa92e.com. Its security certificate is valid, so although it might come as a bit of a surprise, you should know that you’re safe after all.
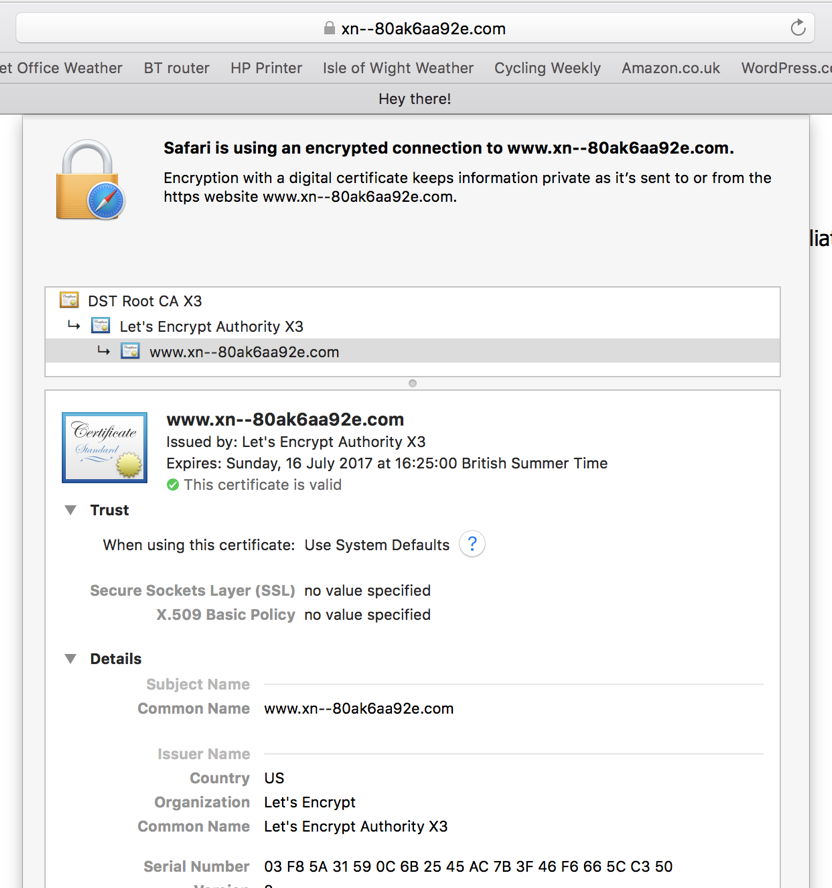
Xudong Zheng’s brilliant demonstration of a security vulnerability makes an excellent point to every computer and device user: even if a link looks to be safe, it could still be cunningly engineered to look right, but in fact whisk you off to something wholly unexpected.
It’s very hard to know what to suggest, then. Browsers don’t unscramble such spoofed addresses until you have finished editing the address, which is when you press Return and connect to them. Although you might notice the slight disparities in characters when using certain fonts, or you might notice the address change into its unscrambled form, when you’re pressed for time you could easily stumble straight into a trap.
As Xudong Zheng points out, there is no reliable way that a browser can detect whether an address is a Unicode spoof, or a genuine address which happens to use those Unicode characters.
One method which should in theory be able to detect such problems involves the use of Unicode normalised forms. I have already discussed these in relation to file and folder names in file systems such as APFS, and have provided the free utility Apfelstrudel (from Downloads above) to remove any doubt as to which Unicode characters are being used, and to show the effects of normalisation on them.
Normalisation aims to overcome confusion which can arise when using Unicode characters which have different encodings, but which appear almost identical to the eye. My stock example is the pair café and café. These differ in the characters used to form the final e-acute: in the first form, it consists of UTF-8 c3 and a9, in the second 65, cc, and 81.
Most file systems will not allow two files or folders bearing those names in the same location, as they recognise that they are visually almost identical, and deem them to be the same. They do this using a table of normalisations, which map between such visually indistiguishable characters.

The snag, as shown in Apfelstrudel’s assessment of Xudong Zheng’s spoof, is that normalisation doesn’t detect this and many other spoofs. If browsers were to use the same technique as file systems, they would still recognise аррӏе and apple as being completely different words. To confirm that, the screenshot below shows two folders side by side on my Mac which appear – at first glance, at least – to have identical names. Because they do not normalise to one another, the Mac Extended File System sees nothing wrong with that.
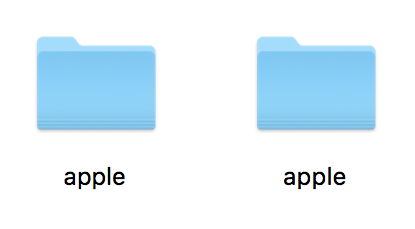
So this is not just a demonstration of a security vulnerability which we are going to have to learn to live with, but a shortcoming in current handling of Unicode characters. Just as we could end up being hijacked to a malicious website, so too we could end up losing files and folders because they are in the wrong apple folder. Normalisation has let us down.
The trend in file systems such as ZFS and APFS is to use normalisation as little as is essential. Although unlikely to be used on Macs, iOS 10.3 and later devices running APFS already use a variant which does not normalise, and considers that café and café are different. The variant which will most probably come to macOS 10.13 this autumn may not permit that pair, but it will certainly allow аррӏе and apple to coexist, which is not in the best interest of users.
I hope that Xudong Zheng’s demonstration not only wakes us up to the security issues, but drives a reconsideration of the whole issue of normalisation. Otherwise Unicode will serve to make clear communication harder, and more confusing.
