

Meaningful and natural speech remains a uniquely human attribute. Each major release of OS X has boasted improvements in text to speech, and speech to text, but do they yet match the abilities of a human?
Viewed primarily as ‘assistive’ technologies that can facilitate computer use by those with physical impairments, Macs can work with speech in both directions, either to convert written text into spoken words, or to transcribe your speech into written text.
These are generally known as text to speech (TTS) and natural language speech recognition (NLSR), respectively. At various times the subject of wild claims about huge and revolutionary advances, both are currently viewed as niche applications, and are often omitted when considering mainstream input and output techniques.
It is perhaps salutory to look back around 35 years to the Texas Instruments 99/4, one of the first home computers, whose Speech Synthesiser was far more advanced and capable of more natural speech output that today’s general-purpose computers. By comparison many of the current crop of TTS products seem as robotic as the voice of Star Wars’ R2-D2.
Apple’s own speech products were launched with the very first Mac, in the form of MacinTalk, a software-based speech synthesis system which could perform fairly crude TTS. When later Motorola 68K-powered Macs became available with digital signal processing (DSP) hardware, MacinTalk became far more usable and less of a comical novelty.
NLSR also allowed Mac users to control their computers using voice commands, but not dictate text to assemble documents. IBM had been a pioneer of NLSR dictation products, with its VoiceType and subsequent ViaVoice systems primarily for PCs, but it was MacSpeech iListen that fired enthusiasm among Mac users. In the last fifteen years a succession of products including ViaVoice, Dragon NaturallySpeaking, and MacSpeech Dictate, have been promoted, but none has enjoyed the success that their developers envisaged.
TTS
TTS is generally accepted as being the easier task, is accomplished more successfully, but is considerably less exotic with more restricted appeal. There are several different strategies available to generate speech, most of which depend on analysing the text to be spoken in terms of its constituent sound fragments or ‘phonemes’.
The traditional speech synthesis engine bundled with OS X, descended from MacinTalk, not only does this but gives programmers direct access using phoneme codes, which can be employed to improve pronunciation. You can explore this in AppleScript, using the embedded [inpt PHON] command as described in the Say it with AppleTalk section below.
Speech synthesis based entirely on phonemes sounds slightly fragmented and unnatural, so recent versions of OS X also offer a more sophisticated engine. Speech is also both language- and region-specific: you might have noticed that Snow Leopard’s built-in voices had a distinct American twang, and sounded nothing like any of the regional variants that we are used to in the UK. Feed them French or German, and their efforts were more comic than comprehensible.
 Since then OS X has extended language support in its bundled voices and speech synthesis engine to cover 43 tongues, including British and Australian English, French, and German, but these can no longer be enhanced by downloading better quality voices from Apple. You can still purchase additional voices from third-parties such as Cepstral (up to OS X 10.8), CereProc, and Acapela via AssistiveWare. These include more regional variations of the English language, such as Scottish and Irish.
Since then OS X has extended language support in its bundled voices and speech synthesis engine to cover 43 tongues, including British and Australian English, French, and German, but these can no longer be enhanced by downloading better quality voices from Apple. You can still purchase additional voices from third-parties such as Cepstral (up to OS X 10.8), CereProc, and Acapela via AssistiveWare. These include more regional variations of the English language, such as Scottish and Irish.
Unfortunately these third-party voices usually employ their own speech synthesis engines which behave differently from Apple’s. For instance, most do not support MacinTalk-style phoneme input, and may support emotional simulation using commands such as <voice emotion=“cross”>. For a substantial fee, you can commission firms like CereProc to turn your voice into software, but this is not yet a task that can be performed by the user, like turning your own handwriting into a custom font.
The biggest problem in realistic TTS is modulating speech output so that it complements the meaning of what is being spoken, such as rising pitch in the final phonemes of a question. To achieve that, the speech synthesis engine needs to build some semantic and syntactic gloss over what is being spoken, to place appropriate emphasis, pauses, and the like. This is even more language-dependent, and currently a research question rather than an implemented feature.
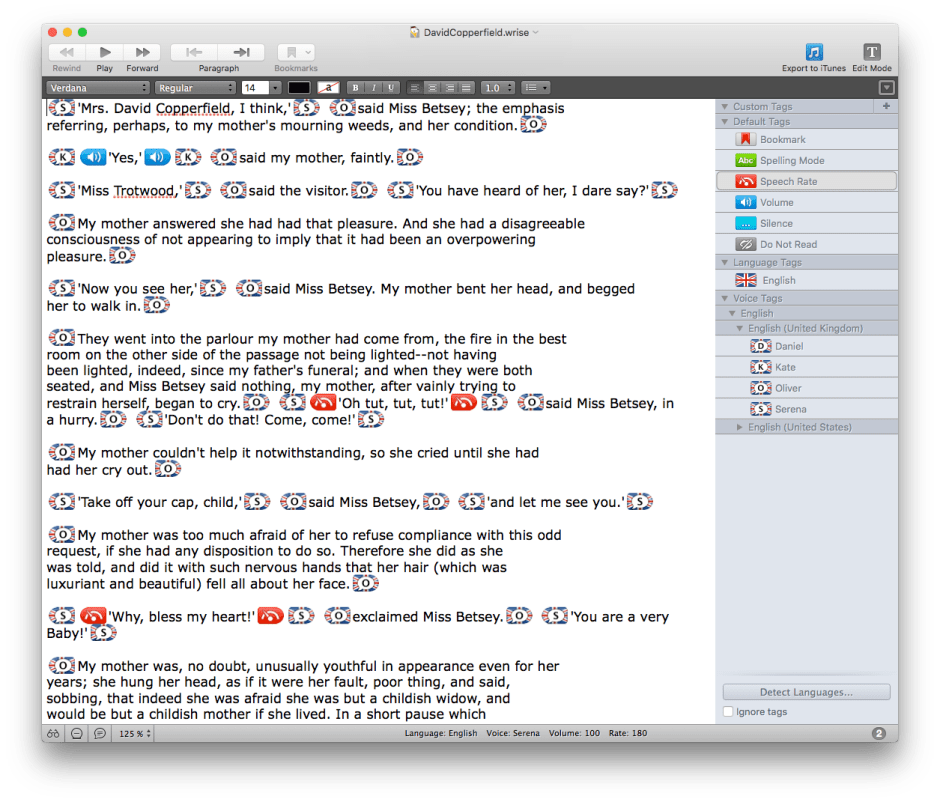 So for the moment TTS is most widely used as an assistive technology, where it is of particular value to those with visual impairment – hence its use in VoiceOver. It is also one of the unique features of the Wrise word processor. In the longer term, it holds promise for the more efficient delivery of talking books, blogs, and much more, but this has yet to go mainstream.
So for the moment TTS is most widely used as an assistive technology, where it is of particular value to those with visual impairment – hence its use in VoiceOver. It is also one of the unique features of the Wrise word processor. In the longer term, it holds promise for the more efficient delivery of talking books, blogs, and much more, but this has yet to go mainstream.
NLSR
NLSR has also long struggled to break free from the research lab into the mass market. Early systems were speaker-dependent, in that they had to be trained for each user. Sometimes these could take an hour or more before you had completed first a standard vocabulary, and then corrected specimen dictation tests. Vendors such as Philips and Nuance invested heavily to develop speaker-independent systems that required little or no training or configuration, and Speech Recognition in OS X is derived from those efforts.
 The snag is that, like optical character recognition (OCR, text from print), most users can get quite good results, but they are sufficiently far from perfect to make NLSR dictation systems an option only when conventional keyboard input is difficult or impossible. Again this tends to relegate it to being an assistive technology, ironically in this case of greatest appeal to those who have developed repetitive strain injury (RSI) or similar conditions, often from excessive keyboard use. Further details are here.
The snag is that, like optical character recognition (OCR, text from print), most users can get quite good results, but they are sufficiently far from perfect to make NLSR dictation systems an option only when conventional keyboard input is difficult or impossible. Again this tends to relegate it to being an assistive technology, ironically in this case of greatest appeal to those who have developed repetitive strain injury (RSI) or similar conditions, often from excessive keyboard use. Further details are here.
The most recent wide-scale application of NLSR is in call-centre systems that allow you to select options, give your customer details, and specify payments using your voice over the phone. Once again these have proven vulnerable to the wide variations in accent, articulation, and intonation between individuals. If you have not yet been driven to infuriation by an uncomprehending or miscomprehending voice recognition system, then you have been fortunate indeed.
Voice control is available to all OS X applications, and by limiting the range of words that need to be recognised it is much less likely to make errors than a full-blown dictation system.
The performance of dictation systems can be improved if the recogniser can narrow the range of possibilities according to the context of the word that it is trying to identify. This becomes feasible when the system is limited to specific types of content, such as medical or legal, rather than having to cope with everything from lyric poetry to enumeration of retail stock. Unfortunately this in turn makes it less likely that the average Mac user will find NLSR dictation a worthwhile proposition.
For the time being, computer voice processing – either converting text to speech or transcribing the spoken word into text – works best for those with disabilities or other problems in using the normal keyboard, mouse/tablet, and display. Although they have been successful in some vertical markets, what you get in El Capitan is about as good as they get in general use.
Tools: Say it with AppleTalk
Although you can experiment with OS X TTS using applications with suitable support, the best for exerimentation is the Script Editor, through its AppleScript say command. Type a line such as
say "MacUser spoke volumes" using "Oliver"
and then click on the Run tool to hear the enhanced (non-phonemic) Oliver voice, for instance.
Newer voices no longer use the same phoneme-based synthesis mechanism, but you can still access the older voice synthesiser with older voices. For example
say "[[inpt PHON]] _m1AEk1y1UWzAE [[inpt TEXT]]" using "Vicki"
will produce a slightly different pronunciation of ‘MacUser’ as it specifies the individual phonemes to be used, rather than relying on the TTS engine to translate the word into phonemes before passing it to the speech synthesiser. For instance, AE is used to generate the phoneme for the vowel sound in bat, whilst AA is used for that in cart.
Phoneme support and output vary according to the voice used, and third-party voices are unlikely to support direct phoneme input in this way. You could also set the voice to spell out the string submitted as a series of letters using [char LTRL], to set context using [ctxt WSKP] and related commands, such as
"The word [[ctxt WSKP]] GPS provides [[ctxt WORD]] coordinates [[ctxt NORM]]"
which ensured that coordinates was recognised as the noun and not the verb, but that no longer seems to work in El Capitan.
[emph +] and [emph -] were used to increase and decrease emphasis, respectively, whilst pbas, pmod, rate, and volm commands controlled baseline pitch, modulation, speech rate, and volume. For very sophisticated changes to output, you could supply complex pitch contours using a special TUNE format instead of phonemes.
For further information you will need to consult Apple’s account of speech synthesis in the developer documentation, either through Xcode’s online reference, or here. However, that was last revised in 2006, and does not give details of the latest voices. Third-party speech synthesis engines are less well documented, unfortunately.
Updated from the original, which was first published in MacUser volume 27 issue 17, 2011.
