
One of the most valuable features of virtualisation of macOS guests on an Apple silicon host is near-native performance. I have previously reported measurements of integer and floating-point core performance in VMs that were close to those of the host. This article reports fuller comparisons on both M1 Max and M3 Pro hosts over a much wider range of in-core tests.
Testing
Native tests were run on a Mac Studio M1 Max (8P+2E) and a MacBook Pro M3 Pro (6P+6E), both running Sonoma 14.2.1. Virtual machines were created in Sonoma 14.2.1 using Viable, and run in Viable with 6 virtual cores and 16 GB of memory. Tests and times were measured using the same app AsmAttic, built for ARM64 architecture only. Each test was run with a single thread, and with 4 simultaneous threads, although times used for analysis are those for the single thread, thus representing a total of 100% active residency on a Performance core on the host. Although QoS was set high (33) for every test, that only has effect when running on the host, as VMs don’t make any distinction between core types.
Tests used were:
- empty loop, only incrementing an integer loop counter (assembly)
- integer arithmetic (assembly)
- floating-point arithmetic using multiply-add (assembly)
- NEON vector unit calculating a dot-product on two vectors of four 32-bit floating-point numbers (assembly)
- simd_dot, calculating a dot-product on two vectors of four 32-bit floating-point numbers (SIMD library)
- CPU matrix multiplication of two 16 x 16 matrices of 32-bit floating-point numbers (Swift)
- vDSP_mmul matrix multiplication of two 16 x 16 matrices of 32-bit floating-point numbers (Accelerate library)
- SparseMultiply, multiplication of dense and sparse matrices of 32-bit floating-point numbers (Sparse Solvers, Accelerate library)
- BNNSMatMul matrix multiplication of 32-bit floating-point numbers (Accelerate library).
Source code has been appended to previous articles (see links at the end).
Results are expressed throughout as percentages relative to host performance, thus those for the VM run on an M3 Pro are given relative to the M3 Pro host, with higher percentages meaning faster, and lower slower, than the host.
Results
In general, tests performed in VMs ran only slightly slower than when run in the host. These are summarised in the chart below.
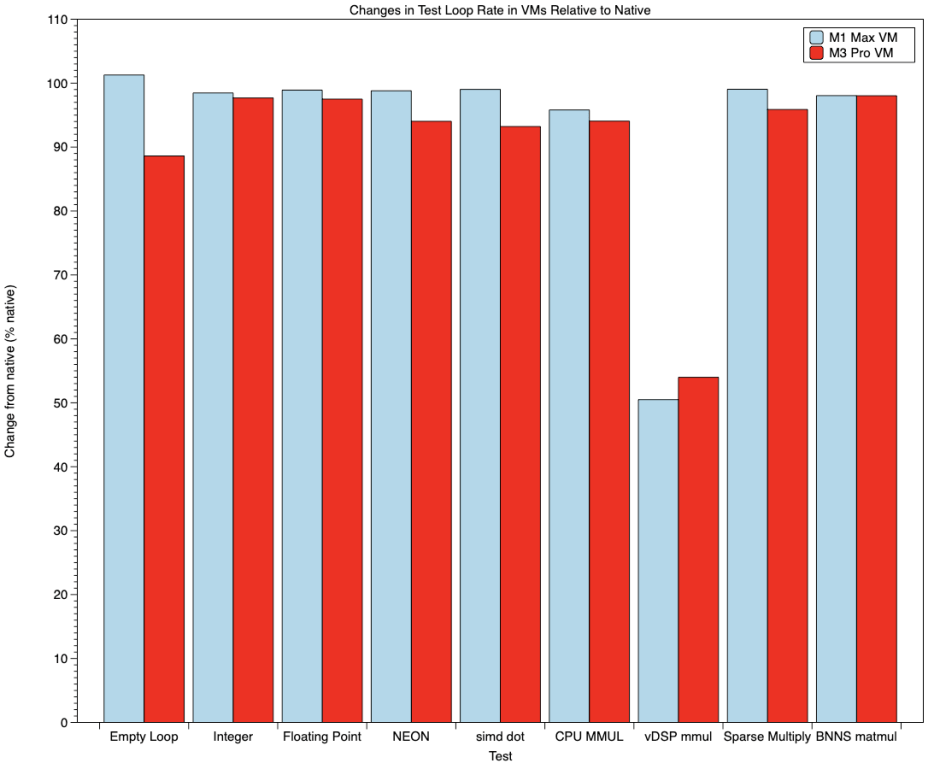
Bars in pale blue show results for the M1 Max, and those in red are for the M3 Pro. With some minor exceptions, and those for vDSP_mmul, VMs ran tests only slightly slower than the host. The empty loop ran slightly faster on the M1 VM, but ran rather slower on the M3 VM. Otherwise VMs ran at 93-99% of native speed, regardless of whether the test used integer, floating-point or NEON units in the core.
The most obvious and greatest exception to that were the results of vDSP_mmul matrix multiplication, which showed a marked reduction in performance to about 50% when virtualised on both chips. This was seen in both single thread tests and when running 4 threads at a time.
The second chart shows performance for tests run in a VM on the M3 Pro relative to results from the M1 Max running native, again with higher percentages being faster.
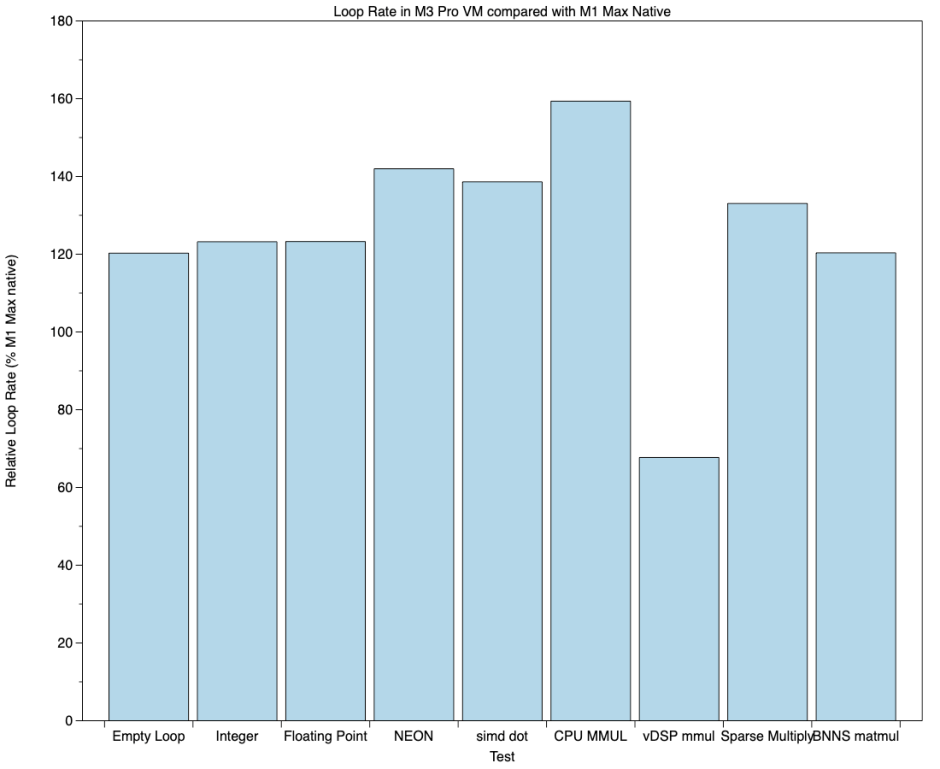
With the sole exception of vDSP_mmul, all tests ran significantly faster in a VM on the M3 than they did natively on an M1. Speed in the VM was 120-160% of native M1.
Explanation
These results are consistent with the claim that virtualisation of macOS on Apple silicon Macs using Apple’s API delivers near-native CPU performance, at least as far as processing units within CPU cores are concerned. Assembly language routines that access integer, floating-point and NEON arithmetic functions do run almost as fast when virtualised, as do most in the Accelerate and related libraries. All other factors, such as memory and GPU access, being equal, this should deliver near-native performance to apps running virtualised.
The marked difference in vDSP_mmul matrix multiplication demonstrates that not all functions in the Accelerate library fare as well, though. As Apple provides no information on which hardware that function can run on, we can only speculate why it performs so poorly when run in virtualisation.
This suggests that, when run native on both M1 and M3 chips, the Accelerate library uses hardware that isn’t available to it when virtualised. That’s almost certainly going to be a processing unit that is outside CPU cores, of which the favourite must be the AMX matrix co-processor. Previous results from powermetrics measurements during tests have shown that there’s no recorded power consumption from the ANE neural engine, making that most unlikely.
On the M1 Max, core allocation when running vDSP_mmul tests has also been shown to be very different from that of other tests used, and again implies that the Accelerate library is accessing hardware outside the CPU core.
I’m not aware of any studies made of AMX use from VMs, but it here appears most likely that, when running native, the Accelerate function uses the AMX, but that’s not available to virtualised code, which then runs a non-AMX substitute that is half the speed.
Conclusions
- In-core performance tests demonstrate that most CPU code run in a macOS VM on Apple silicon does so at near-native speed.
- In-core performance of virtualised code runs significantly faster on M3 cores than native code on M1 cores. Thus, all other factors being equal, a VM running on an M3 chip is likely to perform better than when run natively on an M1.
- One Accelerate library function, vDSP_mmul, is an exception to this, and runs at half the speed when virtualised.
- That’s most likely the result of vDSP_mmul using the AMX matrix co-processor, which implies that the AMX can’t be used from a VM.
Previous articles
Evaluating M3 Pro CPU cores: 1 General performance
Evaluating M3 Pro CPU cores: 2 Power and energy
Evaluating M3 Pro CPU cores: 3 Special CPU modes
Evaluating M3 Pro CPU cores: 4 Vector processing in NEON
Evaluating M3 Pro CPU cores: 5 Quest for the AMX
Evaluating the M3 Pro: Summary
Finding and evaluating AMX co-processors in Apple silicon chips
Comparing Accelerate performance on Apple silicon and Intel cores
Can a different core allocation strategy work on Apple silicon?
M3 CPU cores have become more versatile
