
I’m delighted to release a new version of my free text analysis utility Nalaprop. The main change in version 1.1 is that you can now increase and decrease text size in all its three panels together. Nalaprop analyses text into different scripts and languages, and for those supported shows parts of speech. It also compiles a frequency list of words used according to their part of speech, which can valuable even when working in a single language.
Mojave and later versions of macOS include sophisticated features which analyse natural languages in several different ways. To start with, I’ll explain these using the multi-language sample file which is included with Nalaprop: nalapropMultiTest1.txt. Nalaprop opens plain text files directly, the text content of Rich Text files, or you can paste or type text for analysis into its left panel. To start this demonstration, simply open that sample file using the Open command.

When it opens a text file, the contents are automatically analysed and displayed in two of its panels. At the left is the original text, and in the middle is the same text with each word coloured according to its part of speech, such as noun and verb. The key to the colours used is at the right.
Scroll down through the centre panel and you’ll notice that this file consists of multiple languages, a total of 20. Some of them are shown in multiple colours, indicating that macOS has been able to recognise that language and parse it into parts of speech. There’s support for this in at least eight languages: English, French, Spanish, German, Italian, Portuguese, Russian, and Turkish. Language support may require that your Mac downloads additional data for macOS before that language can be parsed into parts of speech. One way to do this is to add the language to the list of Preferred languages in the General tab of the Language & Region pane.
To perform a wider range of analyses, click on the MultiParse button at the top of the window. After a short delay during which macOS analyses the text in more detail, the popup menu at the top of the middle panel is enabled, and the colours of the text in that panel change, as does the colour key at the right.
To see the sample text analysed for its script (alphabet), select Script in that popup menu. This displays each script in a different colour, which includes Latin, Russian, Arabic, and more. Even those languages which macOS is unable to parse into parts of speech are recognised and labelled.

Repeat this by switching the popup menu to Language, and you’ll see that macOS is excellent at recognising almost all of the languages, although some of the East Asian languages and Esperanto at the end of the samples make it struggle.
There are two entries in the popup menu for Types: the upper of the two uses colours different from the default, and the lower is the same as when you first opened the file.
The last of the options in the popup menu shows different text from the original, at the left: these are Lemmas, word roots without grammatical alteration (inflection). Instead of the verb was, it displays the verb root be, and so on. This can be very helpful if you’re looking at the frequency of words, or trying to translate them, for instance.
Nalaprop also performs word frequency analysis, and can do that either on the words used or on their lemmas. To test this out, you’ll need a fairly long plain text document: here I’ll use a copy of Charles Dickens’ novel A Christmas Carol. Open that using the Open command, which should automatically parse it into parts of speech. Then click on the List button at the top right of the window.

All the words found in the document are then summarised by part of speech, starting with verbs. For each word found, the number of occurrences is given in parentheses. Because this analysis is performed on unmodified words, you’ll see words from the same lemma, like afford and afforded, counted separately.
Nalaprop can be smarter than that: click on the MultiParse button, and wait while macOS works through the whole document again; this can take a few moments, and you may see the spinning beachball briefly, which indicates it’s busy and not hung. When that completes, click on the List button again.
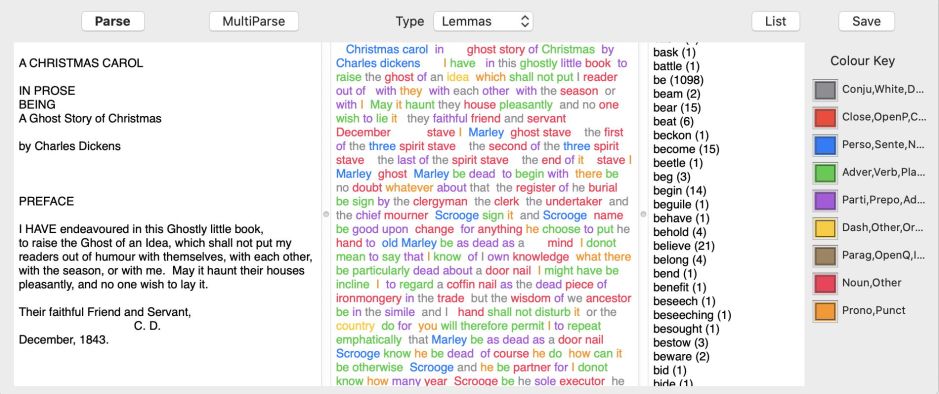
The contents of the view at the right now shows the frequency not of individual inflected words, but of their roots. In English, for example, you shouldn’t see the words am or was listed, but they’re now included in the lemmatised form be.
You can save the word frequency list (but neither of the other views) by clicking on the Save button.
Nalaprop has an extensive Help book available, also provided as a separate PDF, and two colour keys which help you see the colour palettes in detail. You can use its Find command to turn it into an interactive concordance, based on the word frequency list.
In case you’re wondering, Nalaprop correctly recognises there as a pronoun, their as a determiner, and they’re as a pronoun and verb, and even gives their lemmas respectively as there, they and they-be. Your Mac really is smarter than its spell-checker.
Nalaprop version 1.1 is available from here: nalaprop11
from Downloads above, from its Product Page, and through its auto-update mechanism.
Enjoy!
Thanks to Larry for twisting my arm to fix this.
