
In my quest to make meaningful comparisons between different chips in Apple’s M1 series, I have made the case that conventional benchmark testing may not fully load cores, and that macOS manages the loading of cores differently on the original 4P+4E M1 and the latest 8P+2E M1 Pro/Max chips, making comparison difficult. This article describes a method which can work around those complications, and gives initial results which I hope you’ll find interesting.
P and E cores
The original M1, which first appeared just over a year ago, has four Firestorm (P) and four Icestorm (E) cores, each of which has its own L1 caches, but share L2 caches. There’s a single 12 MB L2 cache for the four P cores, and one 4 MB cache for the four E cores. Painstaking work by Dougall Johnson and others has enabled him to propose a core structure making an E core pretty well exactly half a P core in terms of Dispatch Queues, Schedulers, and execution Units.
The latter are divided into six integer arithmetic-logic units (ALU), four load and store units, and four floating-point and NEON (SIMD) units, in each P core. Those numbers are halved in an E core, giving just two floating-point/NEON units, for example.
Cores also run at different clock speeds, with P cores maxing out at 3.2 GHz, and E cores at just under 2.1 GHz. When combined with the units available, this brings the expectation that, all other things being equal, maximum performance attained by an E core is almost exactly a third that of a P core.
The newer M1 Pro/Max chips are thought to contain the same P and E cores, with the same structure and clock speeds, but there are eight P and two E cores. The P cores again share L2 cache within a cluster of four cores, so those P cores are divided into two functional clusters, with the E cores forming a third cluster. Although I don’t recall seeing it demonstrated anywhere, I suspect that all the cores in a cluster run at the same clock speed.
As I showed in my last article, macOS recruits cores differently in the original M1 and the M1 Pro/Max chips. In the M1, P and E cores are often recruited individually, which means that one P core can be running at 100% while the other three are idle. In the M1 Pro/Max, recruitment tends to occur by cluster, with the second cluster of P cores being loaded when the first is at 100%. Setting the Quality of Service (QoS) for a process also determines which cores are used: while the highest QoS will progressively load all the cores, P first, the lowest confines that load to the E cores.
Testing
One way to gain insight into the performance capacity of these two chip designs is to load each with multiple processes and measure the time taken to complete those. Careful code design can be used to assess the ALU and floating-point/NEON units separately, using tight code loops which control other factors such as instruction re-ordering and caches. I’ve used the following tests:
- ALU-only: a 64-bit integer dot product calculation involving multiplication and addition, compiled from Swift.
- Floating-point: four 64-bit floating-point operations, one of which is a fused multiply-add, written in assembly language and using only registers.
- NEON: four 32-bit NEON (SIMD) vector operations written in assembly language and using only registers.
- Accelerate: calling the
simd_dot()function on small vectors, using Swift. - Mixed: compiled from linguistically elegant Swift source, but generating inefficient if not tortured code for both the ALU and floating-point units.
Source code is given in the Appendix at the end.
To ensure accurate timing, large numbers of loops (typically more than a million) were used to ensure each test took several seconds, and times were obtained from the high-resolution Mach system clock. AsmAttic was used as the test harness, to create an OperationQueue with a maximum number of concurrent processes set by the user, then adding an Operation for each of that number of processes using OperationQueue.addOperation. Each of those processes is simple: it obtains the Mach absolute time at the start, runs the test for a set number of loops, then obtains a second time when the test is complete. In addition to per-process performance time, overall test performance is calculated from the start time of the first process to the end time of the last to complete.
For this series, all tests were run at maximum QoS, with the number of processes ranging from 1-12, on an M1 Mac mini 2020 and an M1 Pro MacBook Pro 2021. Each test consisted of two phases: in the first, an appropriate number of loops was chosen, and the different process numbers were checked using the CPU History window of Activity Monitor, to verify the load and its distribution on the cores. Results were then obtained on separate runs, with other processes quiescent and Activity Monitor closed.
Results
The first four tests resulted in essentially identical patterns, exemplified by these results I showed in the last article. Results from the Mixed test were different, though.
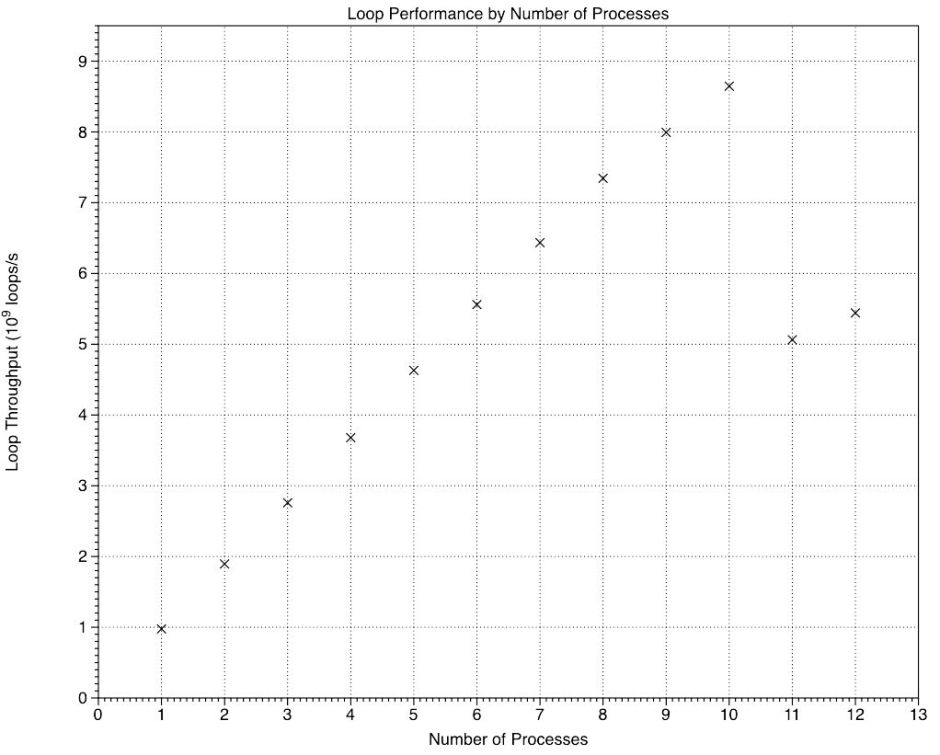
Looked at in terms of the number of loops performed per second, those rose linearly with the number of processes until the E cores were recruited, following which the increments accomplished by the E cores were smaller than those of the P cores, then there was a step reduction for 11 and 12 processes. Plotting those increments shows remarkably consistent patterns.
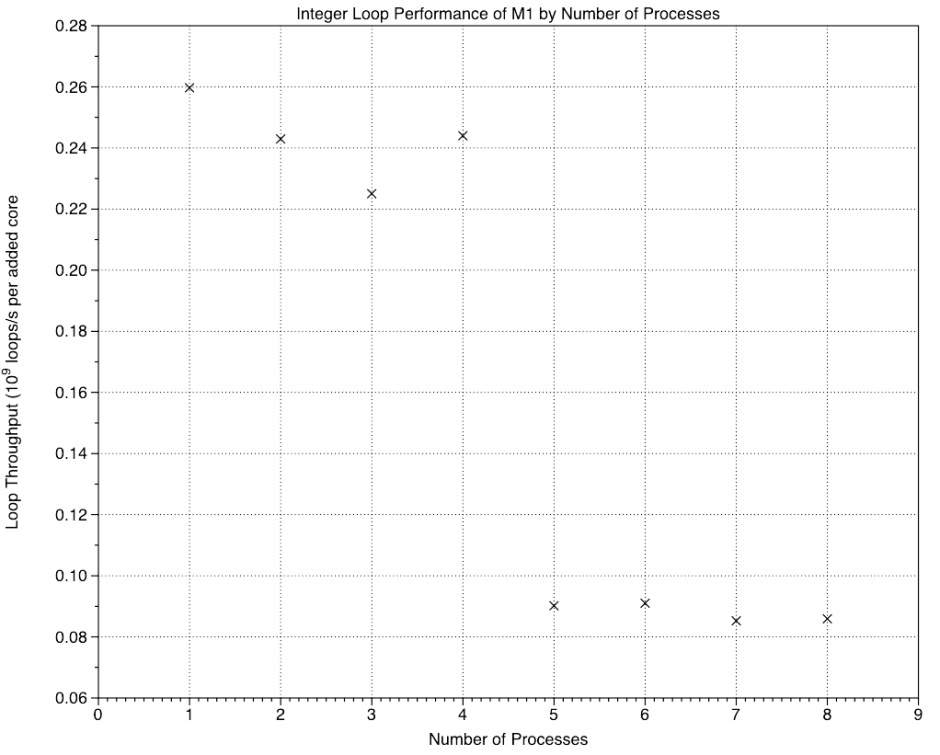
For the Integer test on the original M1, the increment for the four P cores is high, while for the E cores it’s about a third of that.
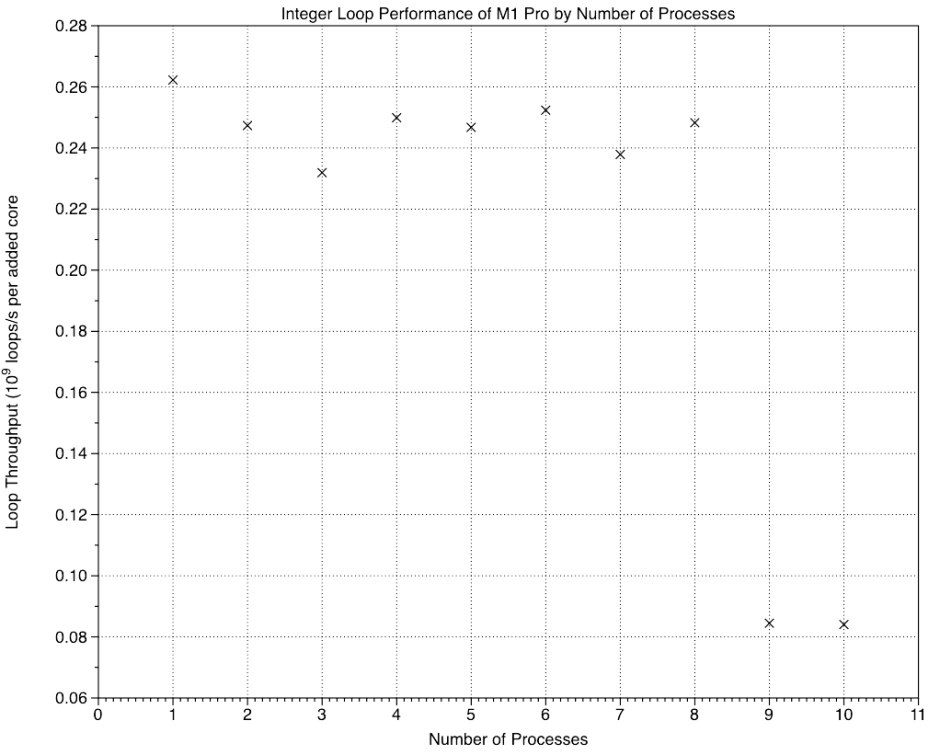
Very similar values are seen on the M1 Pro, across its eight P and two E cores.
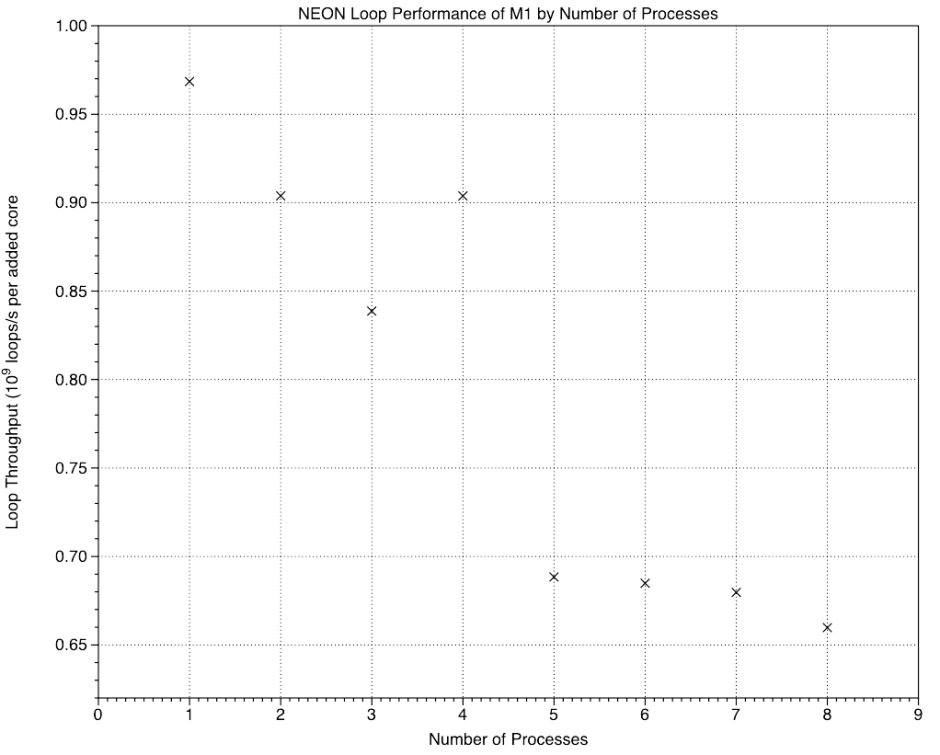
Although the pattern is similar for the NEON test, the reduction on the E cores is far less on the M1.
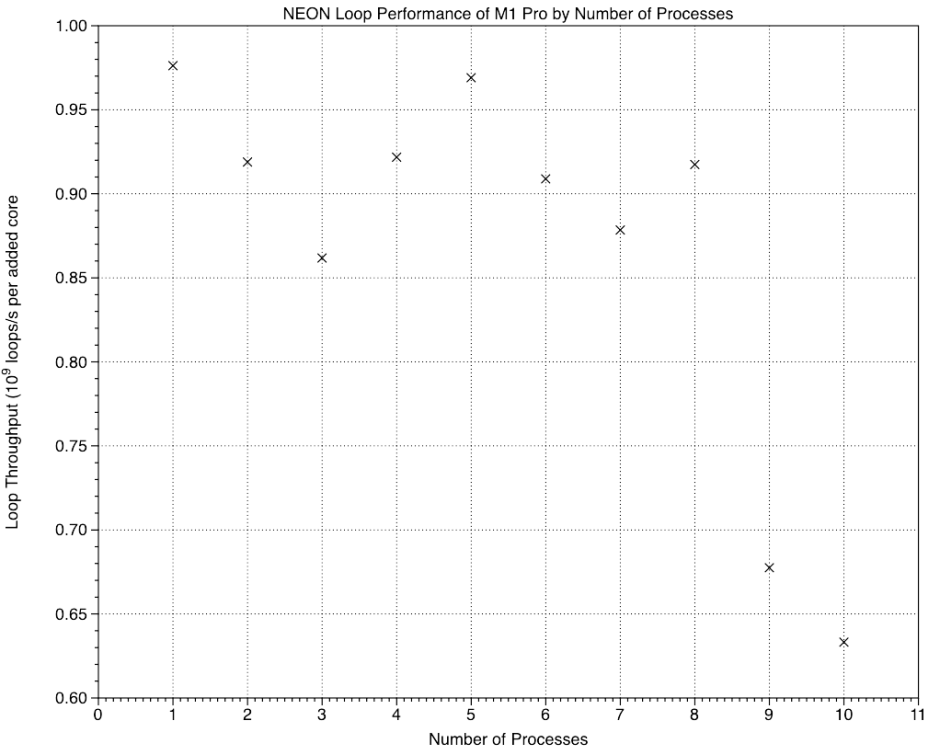
That holds good on the M1 Pro.
One way of estimating the single-core performance, thus of the difference in performance between P and E cores, is to calculate the average of those increments, according to the type of core.
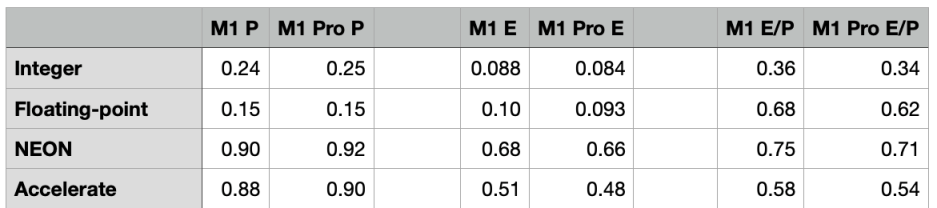
Results for those are shown in the table above, given as (loops x 10^9) per second per process.
The Integer (ALU) test returns almost exactly the result expected from the proposed composition of the cores and their maximum clock speeds, but all three tests which rely on floating-point/NEON units are far better than would be expected of the E cores.
Results from the Mixed test aren’t as consistent with this pattern though. On the original M1, each cluster of four cores returned consistent results, with an average for the P cores of 0.0065, and for the E cores 0.0024, giving an E/P ratio of 0.37, as would be expected for the ALU. On the M1 Pro, although the first five processes returned consistent results averaging 0.0067, results were more erratic with higher numbers of processes, including those for the E cores. This may reflect the fact that other factors are coming into play, given the inefficient code involved.
Other than those results for the Mixed test, these appear reproducible. When repeated on a different day, on the same M1 Pro, NEON tests returned E/P ratios of 0.7094 and 0.7130.
Conclusions
When tested using tight code loops which rely on registers rather than memory access, it’s possible to fully load individual cores, and derive an estimate of their individual performance. Results from those tests confirm that there’s no discernible difference in the performance of the cores of the original M1 and M1 Pro chips.
When running relatively few processes at high QoS, performance gain with core recruitment falls when the number of processes exceeds 4 on an M1, and 8 on an M1 Pro, as additional processes are then run more slowly on the E cores. Once they are fully loaded (8 processes on an M1, 10 on an M1 Pro), there’s another significant reduction in per-process performance, as additional processes are added to already loaded P cores. For apps which run 4-20 processes concurrently, this is likely to result in significant differences in overall performance between M1 and M1 Pro/Max systems.
Code running primarily on ALUs is likely to run at about one-third of the speed on an E core, compared with a P core. However, this reduction appears considerably less with code running primarily on the floating-point/NEON unit, which may attain two-thirds of P performance. Although this appears consistent across different tests, its explanation is elusive. More work is needed.
Appendix: Source code of the tests discussed above
Integer
func runSwiftTest3(theA: Float, theB: Float, theReps: Int) -> Float {
var tempA: Int = Int(theA)
let tempB: Int = Int(theB)
var vA = [tempA, tempA, tempA, tempA]
let vB = [tempB, tempB, tempB, tempB]
let intC: Int = tempA * 2
let vC = [intC, intC, intC, intC]
for _ in 1...theReps {
tempA = 0
for i in 0...3 {
tempA += vA[i] * vB[i] }
for i in 0...3 {
vA[i] = vA[i] + vC[i] } }
return Float(tempA) }
Floating point
_testadd2:
STR LR, [SP, #-16]!
MOV X4, X0
ADD X4, X4, #1
FMOV D4, D0
LDR D5, B_DOUBLE
LDR D6, C_DOUBLE
LDR D7, INC_DOUBLE
while_loop:
SUBS X4, X4, #1
B.EQ while_done
FMADD D0, D4, D5, D6
FSUB D0, D0, D6
FDIV D4, D0, D5
FADD D4, D4, D7
B while_loop
while_done:
FMOV D0, D4
LDR LR, [SP], #16
RET
INC_DOUBLE: .double 1.000000
B_DOUBLE: .double 0.123456
C_DOUBLE: .double 0.234567
NEON test
_dotprod:
STR LR, [SP, #-16]!
LDP Q2, Q3, [X0]
FADD V4.4S, V2.4S, V2.4S
MOV X4, X1
ADD X4, X4, #1
dp_while_loop:
SUBS X4, X4, #1
B.EQ dp_while_done
FMUL V1.4S, V2.4S, V3.4S
FADDP V0.4S, V1.4S, V1.4S
FADDP V0.4S, V0.4S, V0.4S
FADD V2.4S, V2.4S, V4.4S
B dp_while_loop
dp_while_done:
LDR LR, [SP], #16
RET
Accelerate
func runAccTest(theA: Float, theB: Float, theReps: Int) -> Float {
var tempA: Float = theA
var vA = simd_float4(theA, theA, theA, theA)
let vB = simd_float4(theB, theB, theB, theB)
let vC = vA + vA
for _ in 1...theReps {
tempA += simd_dot(vA, vB)
vA = vA + vC }
return tempA }
Mixed
func runSwiftTest(theA: Float, theB: Float, theReps: Int) -> Float {
var tempA: Float = theA
var vA = [theA, theA, theA, theA]
let vB = [theB, theB, theB, theB]
let vC = vA.map { $0 * 2.0 }
for _ in 1...theReps {
tempA = zip(vA, vB).map(*).reduce(0, +)
for (index, value) in vA.enumerated() {
vA[index] = value + vC[index] } }
return tempA }
