
At the end of last year I promised to concentrate my attention on analysing disk performance data collected by my free benchmarking app Stibium. I’m delighted to say that my new version of that app has moved on a great deal, and now produces results which you can use without lengthy analysis in other apps such as Numbers. I have also improved randomisation of write tests, and added true random write tests.

Testing
Early versions of Stibium ran write tests in a fixed order. This can have great effect on the results, and when repeated can add order effects to every test cycle. This new version now randomises the order of each group of write tests within a test cycle, and should thus be considered as a random write test regime. So if you set the repeats box to 10, each of those repeated tests will be conducted in a different order.
Select the new Random Sizes checkbox and Stibium will write files of random sizes between 2 MB and 2 GB, the range which previous testing has shown is most reliable and relevant to real-world disk use. The length box sets the number of random file sizes in each write cycle, and is limited to the range 5-100. If you want to write more random sizes beyond 100, use the repeats setting in the line above as a multiplier: for example, to write 210 test files of random sizes, set length to 70 and repeats to 3.
Read tests are effectively performed in random order in any case, as that’s determined by the file system, which varies each time the files in a folder are read. Checking the Random Sizes checkbox has no effect on read tests.
In that way, Stibium now offers random-order fixed-size write tests, completely random write tests, and random read tests.
One earlier problem with read tests has been that small hidden files in a folder could get included in test results. Although Stibium still reads files of all sizes, those smaller than 10 KB aren’t passed for analysis, and their results are discarded.
Analysis
Stibium now performs two additional types of analysis on all the results it collects during each read or write test.
The first is to gather all results for each file size, and calculate the median of each group. This has little value when the Random Sizes checkbox is ticked, as it’s unlikely that any two test files will have the same size. Neither does it help when repeats is set to 1 for write testing, or when reading just one cycle of write tests. This is primarily intended when running tests with multiple write repeats.
When you set repeats to a number greater than 1 and then run a write test, Stibium writes one file of each of the fixed sizes (2 MB to 2 GB) in random order, then repeats the same group of write sizes as many times as you have specified repeats. Similarly, when Stibium reads multiple files of the same size, or repeats its tests more than once, it gets more than one measurement for each file size.
In this median analysis, Stibium now gives the median transfer rate for each file size it has tested. For a number of statistical reasons, medians are preferable to averages in this situation.
Stibium continues to provide overall average transfer rates, the overall median and their range. However, these need careful interpretation, as the distribution of file sizes between 2 MB and 2 GB isn’t even when using fixed file sizes, and will only become even for random writes when a large number is used in the length box. This is one of the reasons why you’ll see differences between the overall figures given for transfer rate. It can also be a confounding factor in other benchmarking methods, something to bear in mind when looking at their results.
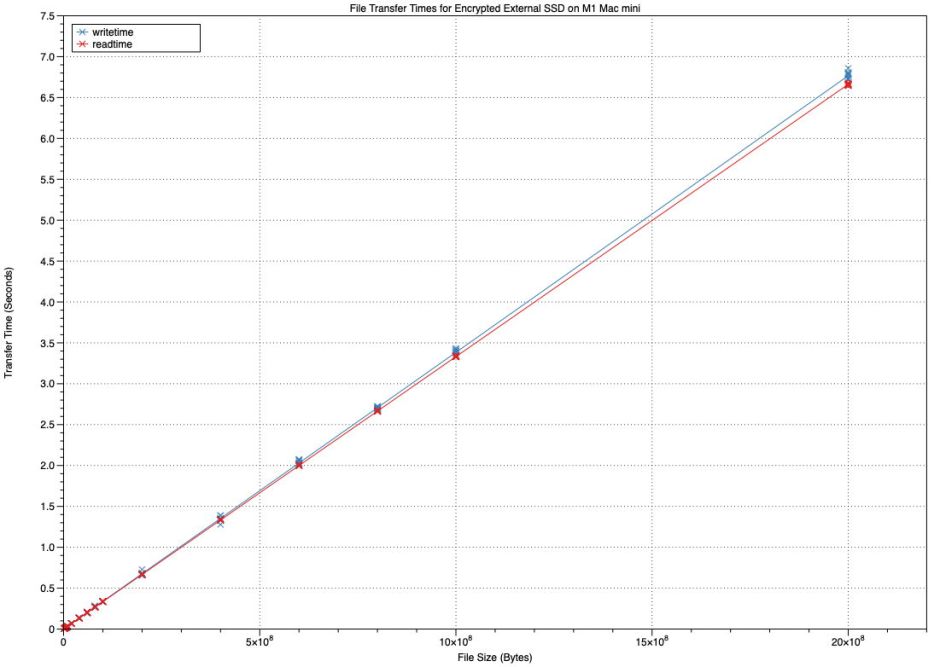
Because of that, Stibium now performs linear regression of test times against file size to calculate the ‘regressed’ transfer rate, as I performed manually using data from previous tests such as that above. At present, while I continue my research into more robust methods, this uses standard non-robust linear regression. It’s therefore susceptible to influence by outliers and other distorting effects. I will replace the current method with something more robust as soon as I’m happy that I’ve identified an appropriate method.
Results
Although Stibium still doesn’t have a built-in feature for charting results, the report which it writes now contains a lot more information. This includes:
- all individual test results in CSV format, when the Verbose option is enabled;
- average, median and range of transfer rates for the whole test;
- a table of median transfer rates grouped by file size, in CSV format;
- the overall transfer rate calculated using linear regression;
- the overall average transfer rate for the whole group of tests;
- details of the folder path used for tests, which also gives the volume name;
- details of the Mac used and its physical memory;
- macOS version, and that of Stibium;
- start and end date and time of the tests.
More will come in the future, including the FileVault/encryption status of the volume tested, I hope.
As before, you can select and copy any of those results from that scrolling view. You can also now export the whole contents in a text file, using the Save Report… command in the File menu.
To make results more comprehensible, transfer rates are now given in standard units such as MB/s and GB/s.
Finally, when each test is completed, the regressed transfer rate, as best estimator of overall performance, is now shown in a box. That is given separately for write and read tests, so if you run each test, the two boxes will display the most recent of those results.
Next steps
There’s now a lot to Stibium and its tests, and my priority in addition to fixing bugs is to document it thoroughly, as well as improving on the current method of linear regression. I expect to release that next version, proably as a first full release. I will then add charting for the second release. As Stibium also now takes part in my auto-update system, you should be able to download future releases more easily.
If there are any features which you want me to include in the next version, please put your case now.
Stibium version 1.0b6 is available from here: stibium10b6
Enjoy!
