

The advice I’ve always given about saving archive copies of important documents is to keep at least two copies, one in the normal finished format, and another in a common exchange format such as PDF. It’s also very useful if you can keep individual components of compound documents, such as separate text and illustrations. That advice is based largely on maintaining accessibility in the future: app-specific formats come and go, and that strategy should give you or your descendants the greatest chance of being able to access that document in years to come.
What I haven’t examined objectively is which formats to choose, where there is choice. In some areas such as audio and video, there’s a bewildering variety of options which are best left to the expert. This article looks at the resilience to corruption of some more general formats, using my tool Vandal.
In each case, I have assessed the effects of adding low levels of corruption, from 2 bytes to 1 MB test files, up to 40 bytes.
Text, CSV, etc.
The most basic common format that can be used for a great many documents is plain text, which is now Unicode UTF-8 rather than ASCII of course. Although it’s possible for corruption to generate text which isn’t valid UTF-8, good text editors such as BBEdit can cope with pretty well anything you throw at them. So whatever happens by way of corruption, you should always be able to open plain text files. This applies to text-based formats such as CSV, which can be used to contain data from spreadsheets and databases.
The one snag with text-based formats is that corruption can be hard to spot. In a spreadsheet saved as CSV, cell contents may become changed as a result of corruption, and those changes may be impossible to detect. Wherever possible, use check totals for rows and columns to help identify any introduced errors before exporting to CSV.
More structured text such as XML and JSON is also relatively robust, but has to be parsed in order to import and do anything useful with it. Maybe at some time in the not-too-distant future someone will come up with more intelligent tools which successfully repair damage in structured formats such as these, but at least you can do so given some knowledge, time and patience.
Styled text – RTF
Rich Text Format is a 33 year-old text-based format with limited ability to contain images and other rich media, and markup which is terse, not intended to be edited by humans, but has simple syntax. Even with quite extensive curruption, up to 40 bytes across a 1 MB file, it could be opened, viewed and corrected using simple RTF editors like TextEdit and my own DelightEd. It thus appears as robust a format as plain text, particularly when packaged as RTFD.
In recent years, Apple has preferred to use file formats which consist of structured folders, or packages, pretending to be files. An early example (which some users hate) is its RTFD, which it designed to extend the rich media which can be embedded in Rich Text documents without violating compatibility. Styled text content is contained within a conventional RTF file, and media files are stored separately within the RTFD folder. This is particularly resilient to corruption, when compared with single file formats which embed rich media within styled text.
Archived styled text without significant images or other content is therefore a good choice, as is RTFD where the document includes images and other non-textual content.
Microsoft Office
One of the hopes when Microsoft moved away from proprietary binary file formats to more open ones using XML was that their contents would become more accessible. To a certain extent they have, but this hasn’t been reflected in any improvement in their resilience. Even low levels of corruption can cause Microsoft’s apps (and Apple’s Pages and Numbers) to report unrecoverable errors, and abandon all attempts to recover the damaged document. Sometimes repair does work, though.


In testing here, Excel was able to open documents with 2 corrupted bytes in 1 MB, but no more; Word failed on 2 bytes, but succeeded with one document corrupted in 4 bytes, but no more. Trying Text Recovery in Word was a futile exercise which consistently resulted in useless gibberish.

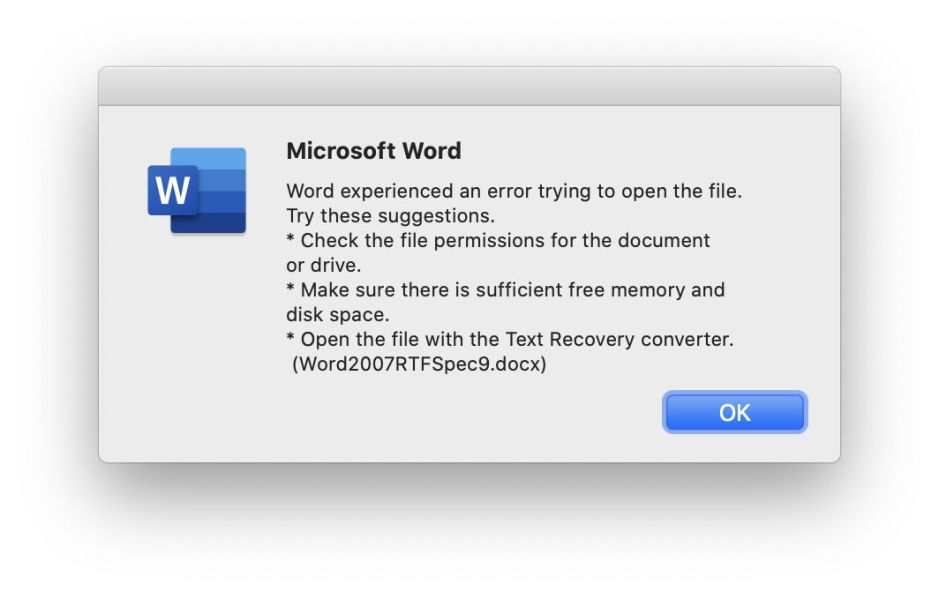
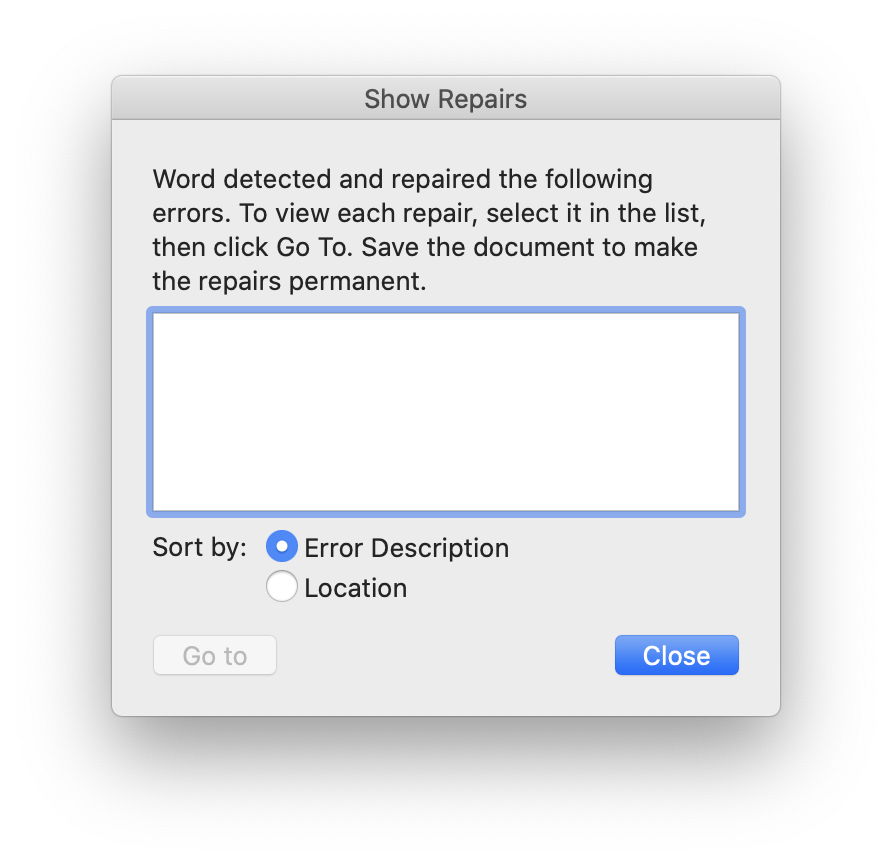
This is very frustrating, and makes .xlsx and .docx formats poor choices in the event of corruption.
My expectations for the resilience of PDF documents were low. When the format was first released, most of its internal objects were still commonly stored in plain text form, and I became well used to editing them to fix broken PDFs for magazine readers and others. Since then, almost all PDF objects have become compressed using ‘flate’, and manual repair requires tools not currently available for macOS. I expected those compressed objects to be vulnerable to the effects of single byte corruption, and to readily make whole documents unusable. I was wrong.
Because of their widespread use in archives, I tested five very different PDF documents, each of just over 1 MB size, at five different levels of corruption, from 2 bytes up to 40. I tried opening them with Preview (macOS 10.15.4) which isn’t noted for its performance, and three dedicated PDF apps, Adobe Acrobat ‘Pro’ DC, PDFpenPro, and PDF Expert.
Only one of the five test documents failed to open reliably with 2 corrupt bytes. With 4 corrupt bytes, another started to lose content but could still be opened. At 20 bytes, one document was badly mutilated with much of its content lost, and one failed completely, and at 40 bytes all five of the documents had obvious problems.
One notable success was the resilience of PDF documents made from Keynote presentations, consisting of just a series of slides. Although some of the images became scrambled at higher levels of corruption, slideshows remained relatively unscathed.

The big problem with a damaged PDF is the lack of tools to attempt repair. For the cost of Acrobat ‘Pro’, it’s shocking that it has no real tools for repair of corrupt PDFs, and just complained of their damage.
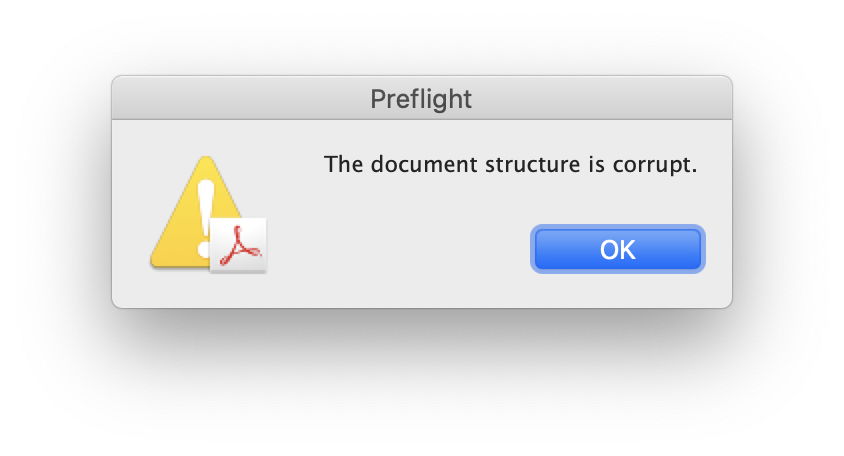
Recovering content from damaged PDFs isn’t a good plan, but they do appear significantly more resilient than Microsoft Word’s .docx format, for example. Provided they are accompanied by separate text and graphics, they do appear a good choice for archiving documents. Perhaps we should also start encouraging our grandchildren to learn how to repair them too, as I’m sure there are going to be plenty of jobs for skilled repairers of PDF in the future.
Conclusions
Controlled corruption of a range of test documents in different formats didn’t bring any great surprises: basic formats using UTF-8 plain text remain good choices where they can be useful. RTF and RTFD should also be considered, as they appear to be relatively resilient. PDF isn’t as bad as I had feared, and is probably still the best choice for maintaining archive copies of formatted and laid out documents, provided that text, image and other content are also held separately.
