
Last week I continued trying to work around the problems I have lately been experiencing with Time Machine and making backups, which drew a lot of attention here and elsewhere, making the headlines on sites such as Hacker News. My accounts of these issues have generally drawn two types of comment: first that this isn’t a bug but a different problem, such as a disk error, and second that this is the way Time Machine always is when making first full backups. This article reviews the evidence that I now have.
What happens in ‘bad’ full backups
Time Machine in Catalina writes many helpful messages to the unified log to record each stage of the progress of its backups, and I have now studied more than half a dozen which have run into trouble when backing up in 10.15.3. Once Time Machine has decided what to back up, it records its progress in copying files from the source to the backup in log entries, typically made every five minutes, which look like
Copied 169 GB of 171.51 GB, 300113 of 302716 items (~162.07 MB/s, 145.42 items/s). Last path seen: /Volumes/ThunderBay2HFS/Backups.backupdb/Howard’s iMac Pro/2020-02-12-122530.inProgress/55743950-4FD0-467C-AA23-9EEC158E9685/External1/Documents/0newDownloads/4blog/metamorphoses/old/Charles_de_La_Fosse_-_Le_sacrifice_d'Iphigénie_-_Google_Art_Project.jpg
These report:
- the total size and number of items copied so far, out of the totals which require backup;
- the rate of transfer, in MB/s and the number of items per second;
- the full path to the last item in the ‘in progress’ backup which was written.
Once transfers are complete, Time Machine reports that too, for example as
Copied 302475 items (173.7 GB) from volume External1. Linked 0. Moved 0
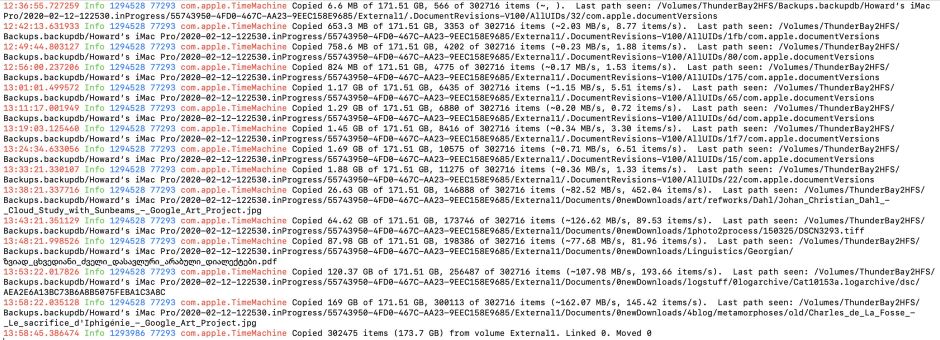
Using the datestamps of those log entries and the reported transfer rates, I have now looked at several of my problematic backups, and analysed those figures using Numbers. Here I give results from three of them for which my log records are complete. In the first, which I cancelled after 86 minutes because of lack of progress, the average transfer rate reported was 0.4 MB/s, with the highest being 1.29 MB/s. You can understand why I cancelled that, perhaps.
Transfer rates are even more revealing in two first backups which did complete successfully, taking 105 and 82 minutes to transfer files. I show those rates below, where the Y axis is the reported transfer rate in MB/s, and the X axis in time in minutes since copying started.


There’s one very clear pattern seen in those progress reports: when low transfer rates were reported, the Last path seen was always, without exception, in the .DocumentRevisions-V100 of that volume in the in-progress backup. Similarly, high transfer rates were never reported when the Last path seen was in that directory. However, when transfer rates were very low, the Last path seen didn’t remain static, but always changed to another sub-path in that directory. The backup copying wasn’t choking on one file, but a succession of different items within .DocumentRevisions-V100.
Looking with Activity Monitor when these low transfer rates were occurring, there’s no process taking significant CPU time, and much of the time backupd and related processes are taking 0% CPU.
Is this a disk error or another unrelated problem?
It’s seldom possible to completely rule out that this problem could be related to a disk or file system error on either the source or destination volumes. However, such errors are normally well-reported in the unified log, and careful scrutiny of several full log extracts over the period prior to and during slow transfers has not revealed any such error messages. Indeed, low transfer rates are associated with low rates of log entries from Time Machine and supporting systems.
I have also reproduced the same problem when backing up from two different SSDs, and to several different destination volumes, including a RAID level 0, all using brand new and checked SSDs, and yes, the backup destination has invariably been formatted in HFS+. The chances of this being a covert disk or file system error are about the same as it being the result of cosmic rays.
Furthermore, even if it were to be such an error, it would still represent a bug in Time Machine. As a backup system, Time Machine is all about reading and writing files. If it fails to handle errors incurred in that process without collapsing into a glacial heap, then it’s not fit for purpose. Furthermore, I know from extensive experience in the past that Time Machine has handled such problems correctly, reported errors when they occur, and got on with its job. That isn’t happening here.
Isn’t this just normal for Time Machine?
I’ve been using Time Machine since it was introduced in October 2007. Although I’ve never had a Time Capsule, nor have I tried backing up to networked storage, I’ve used Time Machine to a wide range of locally attached hard disks, RAID systems, and SSDs from many different Macs over that period. I have performed many first full backups like this, and most recently performed first full backups from the same source volumes in macOS 10.15.2 at the end of 2019. At that time, the whole backup took 61 minutes, and that was to a hard drive RAID system which delivered similar transfer rates to a single SATA SSD over Thunderbolt 3, of around 500 MB/s write and read.
Like most of those who use Time Machine regularly, I keep an eye on its performance, particularly during very large backups. I’ve even written an app, T2M2, which is the only utility that I know of which can diagnose problems in Time Machine in recent versions of macOS. I read logs of backups frequently, as that app relies on parsing those log entries to perform its checks and detect any problems.
I’ve also been writing Q&A sections for Mac magazines since around 1989. A great many of the questions asked of me over the last twelve of those years have concerned Time Machine, and quite a few its performance. One of the common complaints has been backups, particularly first full backups, which never complete. However, with all that experience behind me, I have never seen any first full backup made in similar circumstances behave the way that these have, with transfer rates shooting between less than 1 MB/s and more than 150 MB/s, nor with such characteristic log entries. If you have records of this occurring before, please show them. I’m more than happy to share log extracts with anyone who has earier records of this problem occurring when backing up to local storage.
Is there anything a user can do about this?
Yes, I believe there is, but its solution depends on accurate diagnosis. Tomorrow (Monday) morning I will publish here a proposed method of dealing with this, which you can use to work round what I think you’ll now agree is a bug which is new – at least at this level of severity – to Catalina 10.15.3.
