
At WWDC 2018, Apple promoted two major applications of Machine Learning: image classification and recognition, and natural language processing (NLP). Although many of us already use face recognition when unlocking our iPhones and processing images in Photos, I haven’t yet come across any apps other than my own Nalaprop which use Mojave’s NLP.
If you write – particularly for money – NLP has a great deal to offer you. Until now, tools for helping you improve your writing, and to solve problems in it, have been very crude. If you really want to get to grips with a problem sentence, you’ve had to do it by hand, just as you probably did at school. And that’s invariably too much time and effort.
If you ever work with more than your mother language, NLP can be even more valuable. Perhaps you’re not sure which is the verb, or you can’t identify its root form. Have you just got garbage back from Google Translate, and need to work out what that sentence really says? A little help identifying the parts of speech in the text, and supplying that verb root, could go a long way.
This article looks at the capabilities and performance of Mojave’s NLP features as of macOS 10.14.
macOS can – given a little programming magic – parse text and determine any of the following:
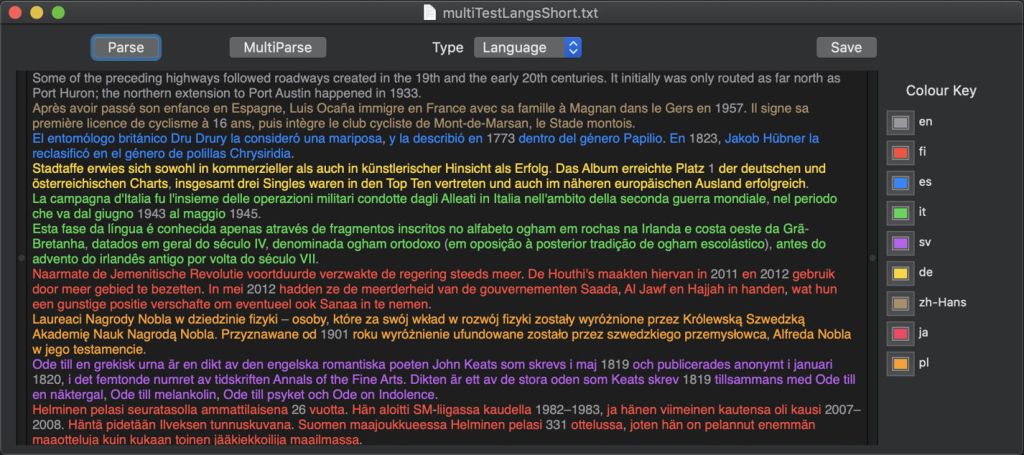
- its script, such as Latin, Arabic, Greek, Cyrillic,
- its language, such as French, German, Japanese,
- lexical classes, or parts of speech, of its words, such as noun, verb,
- name classes, for all its ‘proper’ nouns, such as person, location,
- lemmas, or common word bases of words which are inflected, such as be for is, are, was.
Curiously, the interface to macOS Natural Language only appears to support access to one set of tags at a time. At present, if an app wants to know both the language and lexical class of each word in some text, it has to iterate twice through the tagged text, once for each of the two tag schemes, despite having asked for the tagger to handle both.
Script support and recognition
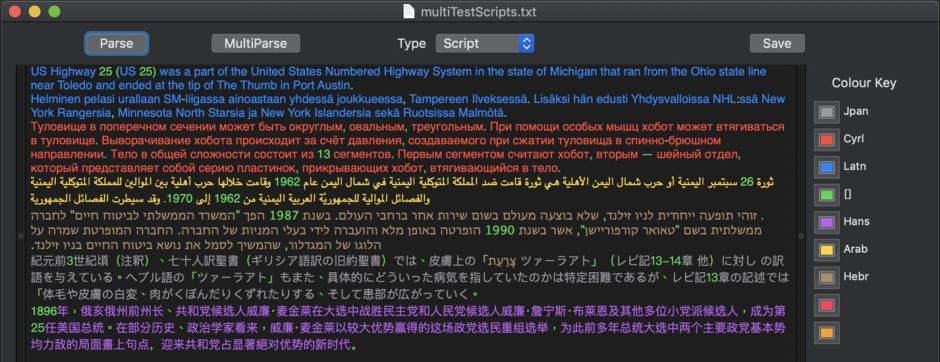
Script tags appear to be assigned on the basis of underlying Unicode code point usage, thus should cover all scripts included in Unicode. Non-linguistic items such as numerals are not assigned a script. Performance, even on very brief excerpts of text, appears perfect, as would be expected.
Language support and recognition
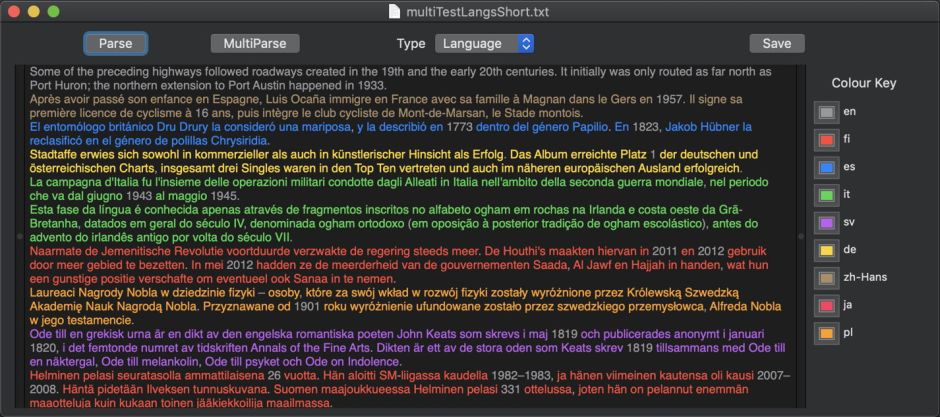
macOS 10.14 is able to recognise many more languages than it can currently parse into lexical classes. When aided by change in script and/or separation into paragraphs, recognition of even brief (two sentences) sections is perfect across 16 different languages used in testing. Recognition worsens markedly when similar languages using the same script are rolled together into the same paragraph. In one test, using two-sentence samples delivered in the same paragraph, only 5 of 16 languages were correctly recognised.
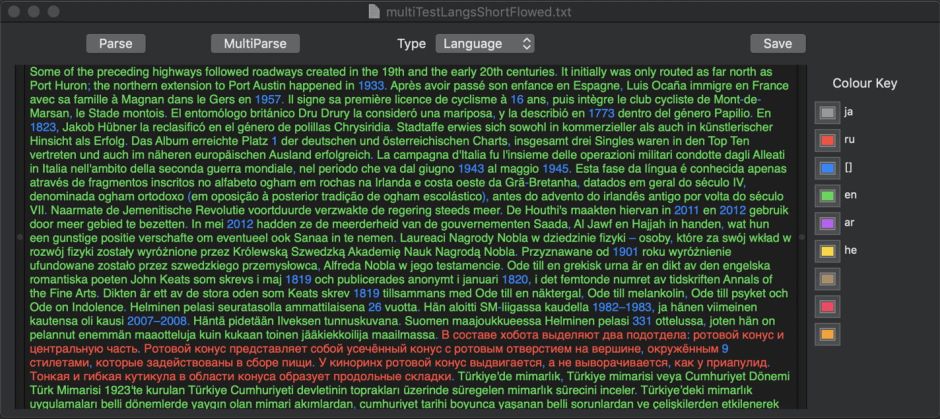
If you want macOS to be able to recognise multiple languages accurately – an important step if it is going to tag words by lexical class, for instance – then it is advisable that, wherever possible, languages are segregated into different paragraphs.
Lexical and name class support and recognition
This is currently only available for English, French, Spanish, German, Italian, Portuguese, Russian and Turkish. More languages are expected to be added in coming months.
Lexical classes supported are: noun, verb, adjective, adverb, pronoun, determiner, particle, preposition, number, conjunction, interjection, classifier, idiom, and ‘other word’. Punctuation is also tagged into 9 classes, and there is a single whitespace tag. Where requested, name classes are personal, place and organisation.
I have examined the accuracy of lexical classification in a 19th century British English text consisting mainly of reported speech, amounting to over 15,000 words in over 400 paragraphs.
macOS was able to find and classify 15,051 of 15,369 words, which included 380 different names. Its performance was in many cases perfect: it found and classified all 863 instances of I correctly, and where there were differences between the macOS classification and word counts, they were small. For example, there were 43 instances of took, of which macOS found and correctly classified 42.
Anomalies were few and far between: for example, macOS classified one occurrence of 5th as a noun, the others as adjectives. O’clock, now a rarity in written or spoken English, occurred quite frequently, and was classified in 11 instances as an adverb, and in 25 as a noun. Apps posed another problem, and was classified as a verb!
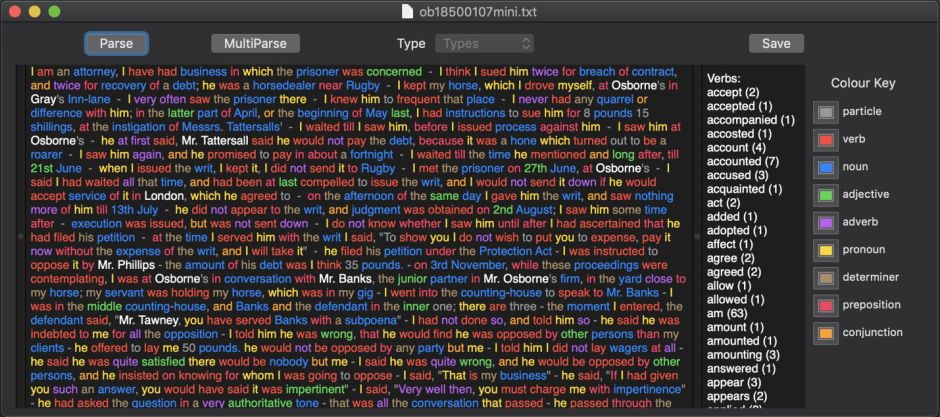
Overall, macOS performance at lexical classification was very impressive, with forms like ‘ll in that’ll being correctly classified every time.
Lemmatisation support and recognition
Lemmatisation is provision of the base form of an inflected word. For example, became, become and becomes are all represented by the lemma become. Although English has limited inflection, lemmatisation also converts from irregular forms of verbs such as be, and has many practical applications. In the sample text, there were 25 occurrences of the verb be in that form; with lemmatisation, the occurrence of the lemma be was 177.
Lemmatisation is currently only available for English, French, Spanish, German, Italian and Portuguese; there appears to be more limited support in Russian and Turkish.
In the sample English text, 5,080 different word forms were reduced to 4,739 different lemmas, which is probably as good as users will need. In its current implementation, macOS Natural Language doesn’t perform any further analysis of words; for example, German compound words are not broken into their constituent parts, and affixes are not separated from roots.
Lemmatisation also extends to the most commonly-encountered names, such as Peter and Mac, but not Mojave.
Words for which macOS is unable to assign a lemma are assigned an empty string instead. This means that replacing the original text with its lemmatised version would replace many words with empty strings. Parsing a lemmatised version of a text will also result in a change in lexical class for many words, so programmers must be cautious when working with lemmas in text.
Is it ready to use yet?
Judged on its performance on English, NLP in macOS already works very well, and can be used now. If you have assessed it on another language in which you are fluent, I would be very interested to know of your results. Inevitably, with the most extensive training corpora, it should perform best on English, although more regular features in other languages such as Spanish may help them perform as well or even better.
You must bear in mind that language is complex, and even native speakers make errors and differ in their opinions about their mother tongue. NLP is never as good as an expert human, but it can be more accessible, cheaper, and quicker.
If you’re interested in looking at alternatives, here’s a commercial system which supports more languages, and does a little bit more than macOS does at present. Basis Technology doesn’t quote any prices, which suggests that they’re after serious money – for what comes free now in macOS.
