
Here’s a new version of Nalaprop which starts to do more useful things with language in Mojave: it will now generate word usage lists for the major lexical classes, such as noun, verb, and name. Since its release, Mojave’s language support has also been updated to fully support English, French, Spanish, German, Italian, Portuguese, Russian, and Turkish.
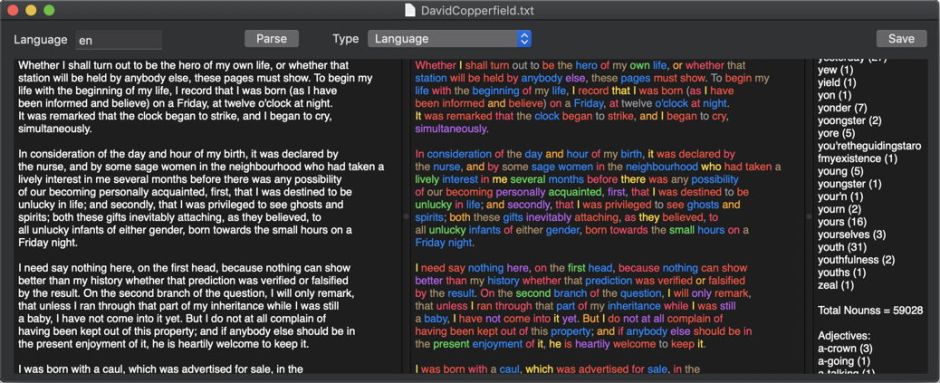
Open a book such as Charles Dickens’ novel David Copperfield, click on the Parse button, and not only will you see the text marked up in colour according to each word’s lexical class, but there is now an alphabetical listing of words by class, at the right. Here, for example, you can see that in the nearly sixty thousand nouns used by Dickens, youth appears 31 times.
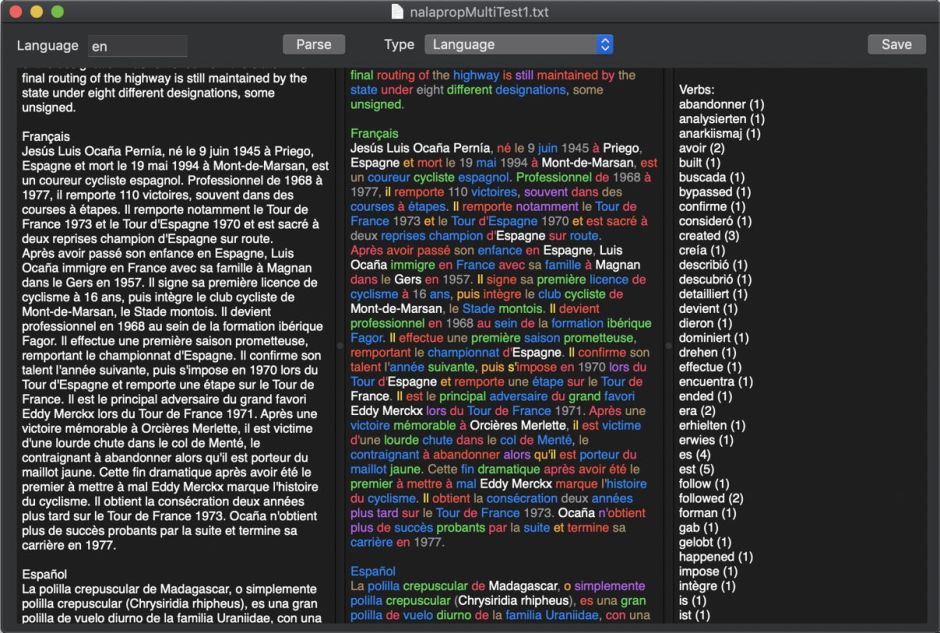
This also works across all the different languages supported by Mojave, although at the moment words are pooled in common lexical classes irrespective of their language.
If you needed, for example, to discover all the names (‘proper’ nouns) used in a text in order to compile an index, Nalaprop can now provide an alphabetically-sorted listing of those names alone.
In this current version, the Find command can’t yet be used to locate words in the original or parsed text: that is a feature which I expect to add very shortly.
Nalaprop version 1.0b5 for Mojave is now available from here: nalaprop10b5
and from Downloads above.
