

Things stopped being hyper many years ago. Now Google’s top searches on that prefix read like your worry list: hyperbole, hypertension, hyperloop, hyperthyroidism, and hyperlipidemia. Like HyperCard, hypertext was so full of promise, then went to hide and hasn’t been seen since. Instead we’ve made do with hyperlinks and hypertext markup language (HTML), which are really plain links and flat webpages. Hyper had been abbreviated to hype.
Then last week it all came flooding back, when Eastgate Systems released its free Storyspace Reader app for OS X.
The problem with what we’ve been fobbed off with until now is that it’s so linear and flat. You can, if prepared to invest the time and effort, craft websites which do more, but they’re the exception and not the rule. HTML pages have no inherent controls, or guards, on their links, let alone dynamic ones. Unless someone has put smart scripts there, every link is active on every visit by every browser. That consistency brings inflexibility: you can’t readily tailor the page to the reader or the reading.
We aspired to much greater back in the 1980s, when hyper was the prefix of the day. Ordinary Mac users wrote interactive HyperCard stacks in which the reader modified the narrative as they read. Non-fiction hypertext let you explore (rather than just passively browse) the life and writings of Alfred, Lord Tennyson, and his Victorian environment.

As the web gathered momentum, some of these were, like round pegs, driven into its square holes. The In Memoriam Web, best read using Eastgate’s Storyspace hypertext authoring environment, became the equally vast but sadly static The Victorian Web.
Late last year, Eastgate released Storyspace 3 for OS X, and in the last nine months or so has progressively enhanced this unique authoring environment. I have written copiously here about its features and capabilities, and how regular Mac users can transform their content in ways which regular webpages cannot approach.

Storyspace supports different types of link, notably those which are only active when specified conditions are met, as shown in its Map view.


The Map view is also ideal for interactive, content-rich maps and charts, created without any of the complexities of JavaScript or HTML5.
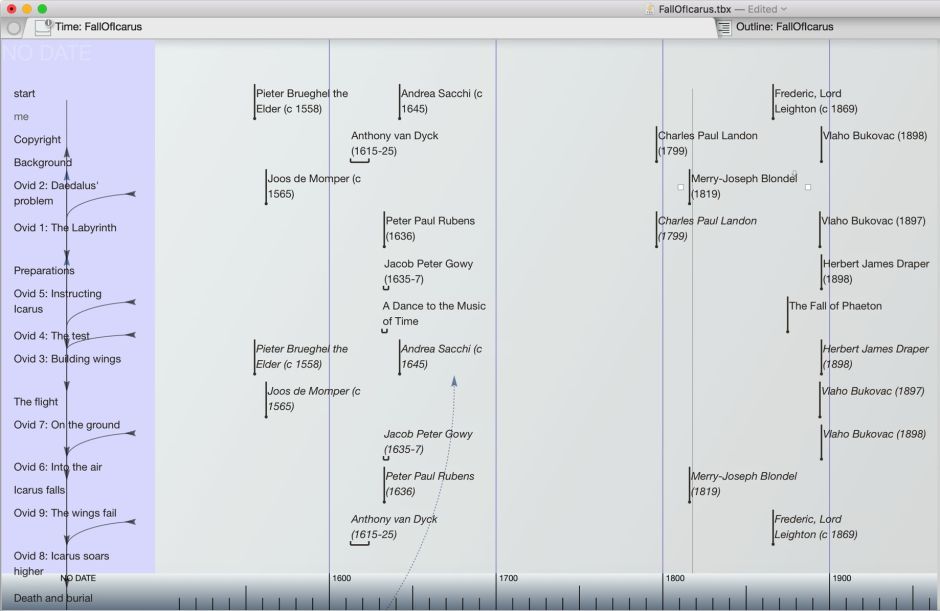
Storyspace includes its own Timeline view, which is almost effortless to use, and more sophisticated than many dedicated apps.
But until last week, its documents have remained accessible only to those prepared to purchase the full-blown authoring app. It’s true that anyone could access and use them with just a free, unregistered demo version, but that was inherently kludgy, and hardly popular.
Now Eastgate has provided the first in what I hope will be a series of reader apps, opening access to real, unfettered, inherently interactive and dynamic hypertext to the tens of millions who are running OS X Yosemite or El Capitan. The marketplace for Storyspace fiction and non-fiction has, with that single step, grown by orders of magnitude.
The sceptical will point to the fact that Storyspace books still enjoy only a fraction of the markets open to Apple’s iBooks or Amazon’s Kindle, whose reader apps dominate on tablets and phones. Hopefully, once the folk at Eastgate have paused for breath, they will be transferring their efforts to the iOS implementation of the Storyspace Reader. That should fully realise the dreams of Michael Joyce, George P Landow, Mark Bernstein, and other visionaries.
Fault-tolerant documents
Storyspace, and its note-centred sibling Tinderbox, in common with many other leading apps, store their documents in XML format. A really big Storyspace/Tinderbox document can readily exceed 5 MB, which is an awful lot of XML, and hefty Microsoft Word .docx documents readily grow into megabytes. With XML well-established as the most universal document architecture, we are starting to learn some of its vulnerabilities.
Given XML’s rigid structure, one of its least endearing attributes is vulnerability to error. Just a single incorrect character in your 5 MB document can blow the whole thing apart, and render it unusable. In theory, you can do what I used to with damaged PDF files: take a text editor to the content, work out what is wrong, and fix it. But that is far easier said than done, particularly when dealing with such huge files.
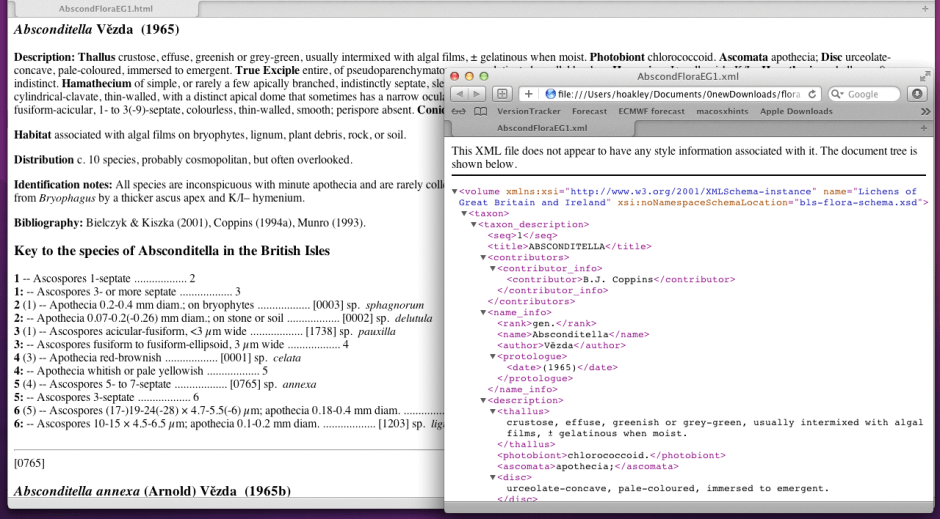
There are a few tools starting to appear which try to recover what they can from damaged .docx files (Corrupt DOCX Salvager and Savvy DOCX Recovery are two on Sourceforge), and some online services (OfficeRecovery, for example) to do so. But we are a long way from any form of fault-tolerance for XML files and the code which parses them.
Being so regular and well-defined, it should not be that difficult for an app to work out where a damaged XML file has gone astray, and suggest some tentative repairs which might make its content accessible again. With the current vogue for throwing artificial intelligence (AI) at much more computationally-challenging problems, it shouldn’t be too tough for a repair tool to arrive at a shortlist of good suggestions.
Another potential solution is to augment XML formats with error-checking and even self-repairing features. Sectional checksums, which could be inserted as comment lines, could go a good way towards that goal.
Instead, standards and practice always assume that every last character is intentional and correct. That is a bit like assuming that all software is completely free of bugs, and flies in the face of long and bitter experience.
