
I think it started with commercial weather forecasters using modern numerical forecasting models, but it all goes back to the slide rule.
Before the general availability of calculators, there were two ways of performing day-to-day engineering and scientific calculations: using a slide rule, or log tables. The latter were printed in thin books of mathematical tables, found in many a pocket, and at every desk. The underlying maths is moderately complicated, and long defunct, but involved adding logarithms as an elegantly simple arithmetical route to determine the results of multiplication.
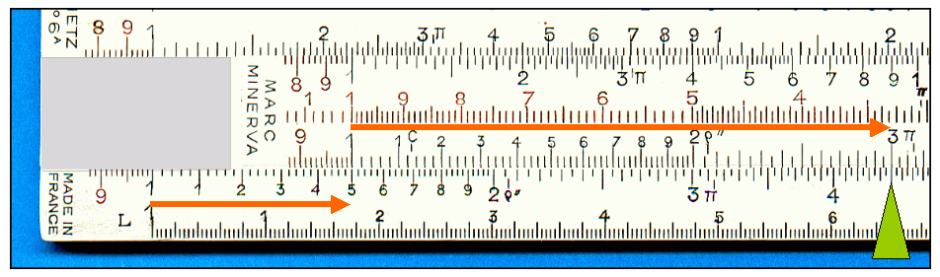
Slide rules were even more cabalistic. Armed with a hybrid sandwich of specially calibrated rulers, the adept user could set one scale against another (by sliding the middle section of the rule), and read off the product of two numbers. Until calculators found their way into the pockets of engineers and scientists, in the early 1970s, it was the white magic wand of the slide rule which set them apart as members of a priestly cult.
Log tables and slide rules had inherent imprecision, so those who calculated learned how to present their results with an appropriate precision. If the result of a calculation was, say, 4.136, then it might be expressed at “just over four”. If it was critical whether it was closer to 4.1 than 4.2, then we might have said “about 4.1”. We knew that the last couple of digits were in doubt because of the error of our approximate method of computation.
Digital computers changed that, in people’s minds at least. For most users, particularly of spreadsheets, the results shown are completely accurate and perfectly precise. When by chance the result is shown as 3.999 instead of 4.0, users complain that the spreadsheet isn’t accurate, and confusion starts to take hold.
Little do they realise that many floating point numbers cannot be represented exactly in binary form, and the small approximations which result can accumulate, causing this sort of effect. Digital isn’t really as precise as we might think, although software engineers like to conceal those small lapses in superficial perfection as much as possible.
So it is with the weather. We all know, from long and bitter experience, that a 64% chance of rain means that we could get sunburned or soaked. Yet none of us seems to question whether there is any meaningful difference between a 64% chance and one of 62%, or why it would not be better just to say 60%, in round figures. The computer said 64%, so that is what is expressed.
We have also lost common expressions which no longer sound so precise: why say “100% chance” when we mean a certainty, “50%” when we mean half, and so on? The influence of digital precision has run deep into our turns of phrase.
So when, this afternoon, a weather forecasting app said that in 10 minutes it would rain for 10 minutes, but at the same time there was a 43% chance of rain over the next hour, the numerical conflicts should have been better resolved. In reality, what it should have said was that there was a roughly even chance of it drizzling in the next hour or so.
It all comes back to being honest about our statistical confidence. The good meteorologist has a pretty good idea of the confidence that they place in a forecast. But they are not allowed to temper their expressed over-precision: it seems we expect the impossibly precise, and then blame them when it does not happen like that.
This reaches the heights of absurdity when we discuss the results of opinion polls. Typically they are conducted on minuscule samples, then extended over huge populations. Good statisticians know well their confidence limits, which are usually much wider than the small trends which commentators single out, and debate to exhaustion.
We cannot, and should not try to, wind the clock back to the heyday of the slide rule in the 1950s and 60s. But we do need to be much more appreciative of uncertainty, and ensure that our precision is appropriate to likely error. Anyone for a swift 50.2% down the pub, then?
