

For those who want to generate viral events, perhaps to promote products or opinion, and those wanting to control then, models are essential tools, the key to success.
In the first article in this series, I gave a broad overview of viral phenomena, and why there is such interest in them. The second article examined what we know about real intensely viral events, which appears very limited. I now move on to look at models in more detail.
Network models
Although large-scale analysis of tweets has so far proved overwhelming, there have been many studies which have performed much smaller-scale network analysis and modelling.
Watts & Dodds (2007) give a readable account of classical models of public opinion formation based in opinion leaders or ‘influentials’ within a communicating network. Nahon & Hemsley (2013) discuss these and related issues, particularly individuals who control the flow of information or messages, who they term ‘gatekeepers’. Unfortunately they appear to use this term quite loosely, using it to describe those who originate messages which could go viral, those who may or may not pass the message on to large numbers of others (equivalent to influentials), and admit that everyone in a network plays the role of gatekeeper to some degree.
Others have reported similar effects using different modelling techniques. For example, Ni et al. (2014) used conventional epidemiological analysis of the Ice Bucket Challenge to show that it was more likely to be spread by richer celebrities, and suggested that this may reflect, in part, their greater social influence.
Hu et al. (2012) considered that opinion leaders on Twitter fell into three groups: individuals affiliated with the media played an important part in breaking news, mass media spread news to wider groups, and celebrities helped spread news too.
More recent work, notably that of Bora et al. (2015), suggests that network ‘conductance’ is the major determinant of growth in popularity. ‘Conductance’ is increased when individuals have followers who are outside their immediate group, and can thus be seen in terms of those with influence beyond their close group. This supports the paradox, discussed by Nahon & Hemsley, that those of greatest influence on an individual in a network are those closest to them, but that flows outside someone’s closest circle (i.e. those of greatest influence to them) are most important in viral events.
Taken together, these findings and models are largely in accord with what you would expect, but cast little light on why, in viral events, network behaviour changes, so that more distant individuals have greater influence than they normally would.
The sigmoid curve
The sigmoid curve remains the only full-scale model which has received much attention in the literature, as far as I can see.
Although it is a superficially attractive approach, as I pointed out in my last article, it has very limited value as a model. In fact the situation is rather worse than that.
Sigmoid curves are extremely common in the real world, when many datasets are viewed cumulatively. The simple model of the Urbahn Twitter event (from the previous article) is reproduced below. If you take many observed phenomena which tend to occur in a peak, as in the lower graph, then plotting the cumulative total will result in a roughly sigmoidal curve.

Similar pairs of peak and sigmoidal curves occur very widely in statistics, in the normal and many other distributions. One way of viewing these curves in this context is as the distribution of time intervals between the initiation of the event and the transmission of each message. Because the greatest number of messages occurs during the steep section of the sigmoid curve, that is the average, median, and modal time interval. Messages sent earlier and later than that average then form the spread, in a distribution which could resemble the normal distribution, so popular in statistics.
As we know from statistics, such curves are commonplace and convenient for certain types of analysis. Depending on their precise shape, they imply some form of random or pure chance process, rather than an underlying mechanism amenable to model-building. Furthermore they are most useful for estimating the central peak (the steepest part of the cumulative version, the sigmoid curve), and the further that you move from that centre, the thinner the data, and the less information available.
Because peak and sigmoidal curves of fairly similar form are so common across many different underlying models, selecting the right model normally requires prior knowledge of the system, and/or extensive observational data. In the case of viral events we have neither. I therefore think that the sigmoidal curve has neither explanatory nor predictive value as a model.
Catastrophes
In the first article in this series, I mentioned Catastrophe Theory, as introduced by René Thom (1923-2002). In this sense, a catastrophe is a sudden change in state which occurs in a system. An example of how this could work is in the ‘cusp catastrophe’, illustrated in the figure below. The two horizonal axes represent two control variables which determine how the system behaves. As these variables change, the state of the system is represented by a point on the folded surface.
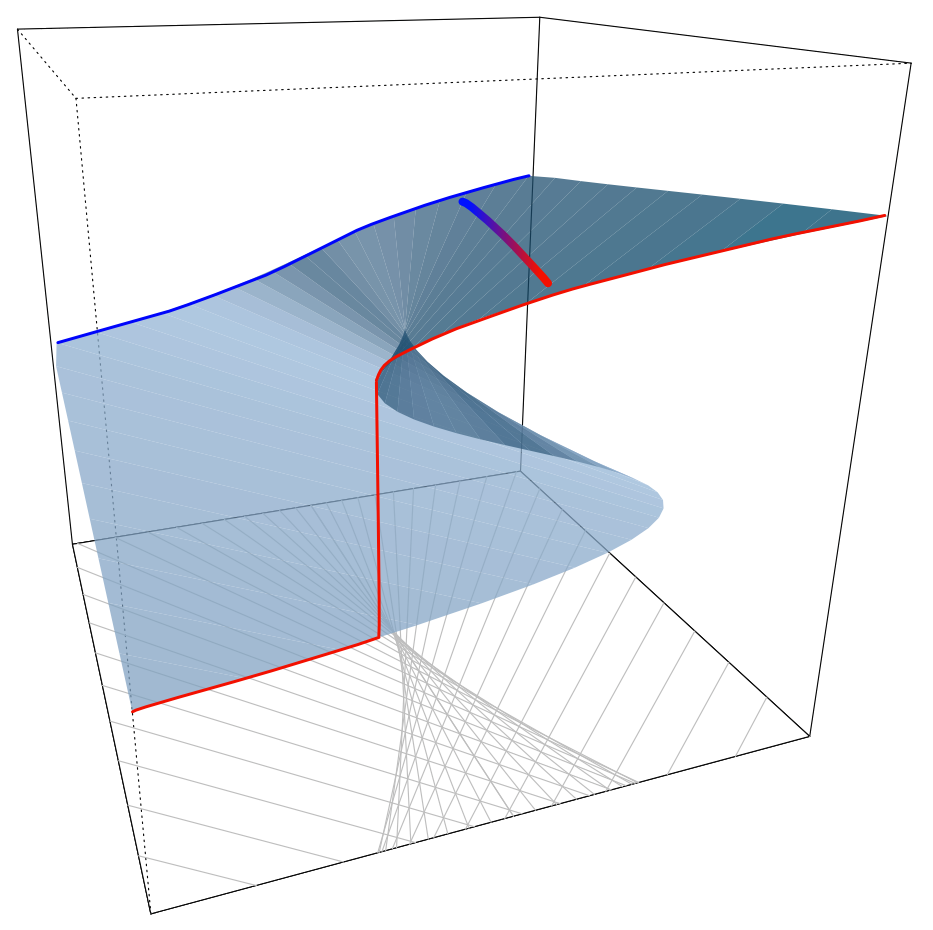 A non-viral event might follow the path represented by the blue line, starting at the top (back) of the surface. As the message spreads, the state moves steadily down the far edge of the surface to a new point. A viral event might follow the path represented by the red line, closest to the viewer. Starting at the top (right), the state reaches the lip and there is a sudden change in state, a catastrophe, which is the viral event.
A non-viral event might follow the path represented by the blue line, starting at the top (back) of the surface. As the message spreads, the state moves steadily down the far edge of the surface to a new point. A viral event might follow the path represented by the red line, closest to the viewer. Starting at the top (right), the state reaches the lip and there is a sudden change in state, a catastrophe, which is the viral event.
The thick line which changes from blue to red, linking the other two lines, illustrates the sort of change in path which the state might undergo to follow a viral path, as the result of a change in a control variable. This might, for instance, represent the involvement of some key influentials or gatekeepers in the event, transforming it from the blue, non-viral path to the red viral one.
In its early days, Catastrophe Theory was just that, theory, with elegant mathematical topology. In the years since then, it has been applied to animal behaviour, biological and physical systems. There are now numerical tools available (such as the cusp package in the R statistics environment) for fitting observed and experimental data to catastrophe models. It is time now to use these tools to gain better insight into what happens when events go viral.
In my next article, I will look further at what people claim they can do with knowledge about viral events, and how good is their evidence.
References and further reading
Bora S, Singh H, Sen A, Bagchi A & Singla P (2015) On the role of conductance, geography and topology in predicting hashtag virality. arXiv:1504.05351v1 [cs.SI] 21 Apr 2015.
Hu M, Liu S, Wei F, Wu Y, Stasko J and Ma K-L (2012) Breaking news on Twitter, Proceedings of the 2012 ACM Annual Conference on Human Factors in Computing, 2751-4. CHI ’12.
Nahon K & Hemsley J (2013) Going Viral, Polity Press. ISBN 978 0 7456 7548 0.
Ni MY, Chan BHY, Leung GM, Lau EHY and Pang H (2014) Transmissibility of the Ice Bucket Challenge among globally influential celebrities: retrospective cohort study, British Medical Journal doi: 10.1136/bmj.g7185.
Watts DJ & Dodds PS (2007) Influentials, networks, and public opinion formation, J Consumer Research 34:441-458.
