
Over the previous two articles (links below), we’ve assembled most of the contents of an APFS volume, including its B+trees of files, directories, file extents and xattrs. This article describes how those volumes are set into containers, and how storage is divided into partitions. To understand these, I’ll reverse direction and start at the top with the partition table.
Partition table
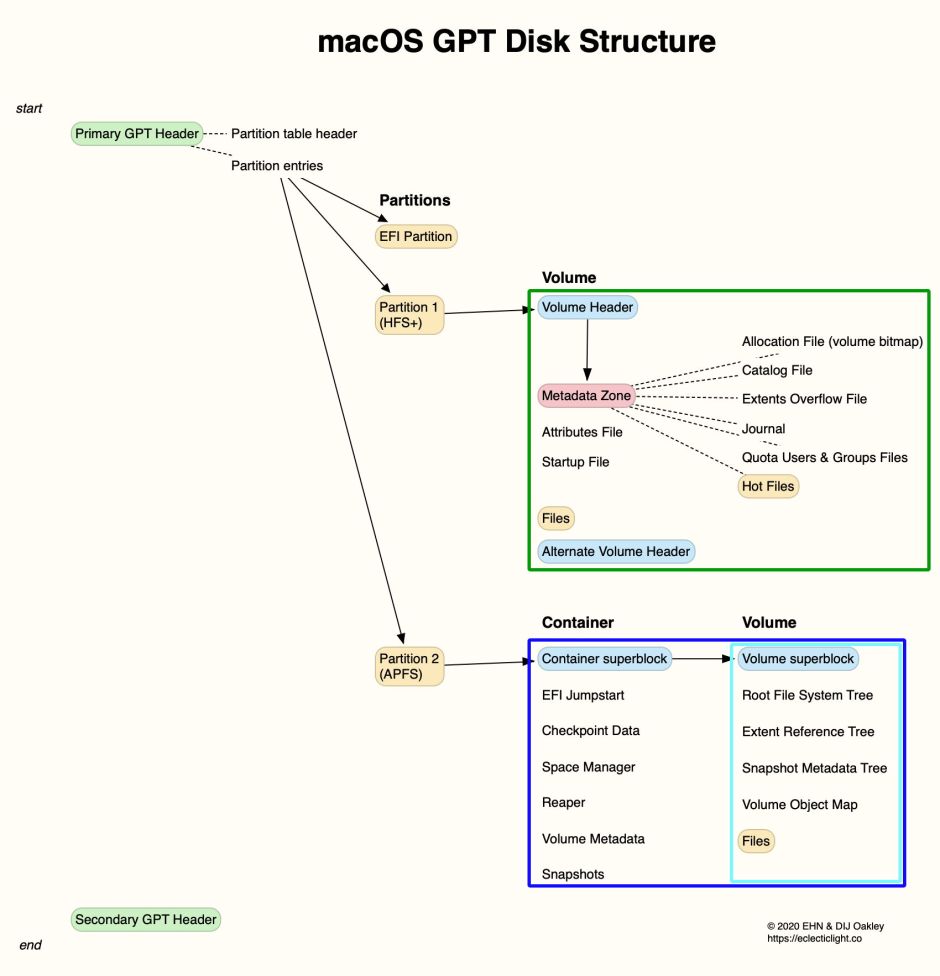
Whatever the type of storage, its space must be organised to store files and metadata. At the top level of each disk is its partitioning scheme, dividing that storage into large contiguous blocks for use with file systems. Conventional usage refers to these as partitions, but in APFS each holds a single structure known as a container. The partitioning scheme now used universally for macOS is the GUID Partition Table (GPT), shown diagrammatically below, where the start of the storage is at the top.

Near the start of the storage is a Primary GPT Header, containing the table that maps where the partitions are on the disk. This header is repeated at the end of the storage, as the Secondary GPT Header, which should of course remain identical at all times.
In the header, there’s an initial block containing information about the storage as a whole, followed by an entry for each partition. Those entries specify the type of partition, give each its own unique GUID/UUID, give the start and end locations of that partition, its attributes, and name. Following the header and its list of entries are the partitions themselves, each containing file-system specific data.
Partition
In HFS+ each volume, with its own file system, is a separate partition. If you want to change the size of a volume, that requires changing the disk’s partition table, which may be impossible without losing data. This also means that HFS+ volumes can’t share free space.
APFS containers are similar in that they have fixed size and don’t share storage with other containers. Within each container are one or more volumes, each containing its own file system and sharing the space inside that container. An APFS container stores all the higher-level information common to the file systems within it, including volume metadata, snapshots, and provision for space management and crash protection. To enable a Mac that requires an EFI driver to be able to boot from a partition, each APFS partition also contains an embedded EFI Jumpstart driver.
Currently, each APFS container can have as many as 100 file systems (volumes) within it, although in practice space requirements may impose a lower figure. To calculate the maximum number of file systems for any container, divide the container size by 512 MiB and round up to the nearest integer. For example, a container of size 10 GiB can contain a maximum of 20 volumes. The smallest permitted container has a size of 1,048,576 bytes. Storage block size is fixed at a minimum of 4096 bytes, which is also set as the default, and a maximum of 65536 bytes.
Each APFS container has one instance of the Space Manager, a major feature of APFS to keep track of free space within the container, allocate and free storage blocks on demand. It also has one instance of the Reaper, to manage the deletion of objects too large to be deleted between file system transactions, including snapshots. This tracks the deletion state of those large objects so they can be removed across multiple transactions.
There’s one situation where an APFS container is composed of two partitions: in Fusion Drives, the hard disk and SSD each have one partition that’s combined into a single container; each partition then has its own copy of the container superblock.
Because of the way that APFS was first implemented, the container layer is associated with the prefix nx_ in its data structure and function names, while the file system layers in volumes usually have the prefix j_.
Checkpoints and crash protection
A file system is highly dynamic. At any instant, many changes to be made to it may remain in memory, and may not have been committed as changes in physical storage. When everything works as intended, this is made robust by using the strategy common to SSDs of copy-on-write to ensure that changed data is saved completely before old data is rendered inaccessible, and by the processes involved in unmounting volumes and containers before unloading them. As described later, unmounting halts further changes and ensures that data saved to storage is an accurate reflection of what’s held in memory.
Perhaps the greatest challenge to any file system is coping with crashes and other events that prevent orderly unmounting, so that the file system can be remounted without it being rendered unusable. This is accomplished in APFS using a system of checkpoints and counting transactions using transaction identifiers or XIDs.
The first physical storage block in an APFS partition/container contains a copy of its superblock, with fields providing key information about its contents, including the address of the EFI Jumpstart. If that container was last unmounted cleanly, this superblock is a copy of the latest version, but if its last unmount wasn’t clean, it may be an older copy. This is addressed by reading checkpoint descriptors from a ring buffer stored as an array, to find the checkpoint that is formed correctly and has the highest transaction identifier, which is designated the latest valid checkpoint. That in turn provides the location of the container’s object map, and the location of each volume’s superblock. Provided that at least one correctly formed checkpoint can be found in a container, that container and its file systems should be mountable.
Volume
Each APFS volume has its own superblock, containing the location of its root file system B+tree, the extent reference B+tree, and the snapshot metadata B+tree, as well as the volume object map.
The maximum permitted length of the volume name is 256 Unicode characters. Each volume can be assigned a role, including System, User, Recovery, VM, Preboot, Installer, Data, Prelogin, Backup and None, according to their purpose in macOS. Supported volume personalities are case-sensitive (iOS) and case-insensitive (default for macOS, except for Time Machine backup stores, which are required to be case-sensitive), and each can be encrypted or unencrypted; encryption will be covered in a future article.
At the time of volume creation, the user can impose a reserve and/or quota size. The reserve ensures that volume is always able to occupy that size within the container, while the quota size imposes a maximum size for that volume. For example, a volume with a reserve size of 100 GB and a quota size of 1 TB is guaranteed to have at least 100 GB of storage space within its container, but won’t be allowed to grow to more than 1 TB of that. Currently there doesn’t appear to be any way of changing that once the volume has been created.
Objects within a volume use that volume’s object map, otherwise they use that of the container. To obtain the physical address of an object, in the appropriate object map, search its B+tree for the object identifier (OID) and the transaction identifier (XID). If an exact match is found, that leads to the physical address of that object on disk. If there’s no entry in the tree for that specific XID, then use the next smaller XID for that OID to provide the physical address.

In this excerpt from a volume’s object map, three leaves are shown for the object ID (OID) 768, each stored at a different time, as reflected in their transaction identifiers (XIDs). To access the latest entry for this OID, the highest XID given is 7010, which points to the physical address A200. To access the object as of XID 6054, the entry points to address A100. If an intermediate XID such as 7000 is required, then the next lower XID of 6081 is used, and points to address A300.
Mounting and unmounting
The first step in mounting an APFS container and its volume(s) is to locate the valid checkpoint in the container. If the container contains one or more volume groups, then those groups are identified and a volume groups tree is set up to handle their mounting.
Once stable checkpoint indices have been established for the container, individual volumes can be mounted. Once again, the valid checkpoint is found, and stable checkpoint indices established. Space Manager’s disk metazone and allocation zone are set up, and a check is made for any objects to be recovered.
Volume mounting proceeds in the light of the volume role, using the volume info. Space Manager first scans free blocks without performing any trims, then scans them again to perform trimming, when the storage medium supports it. Once that’s complete, that volume will be mounted, normally on a mount point in /Volumes. macOS manages name clashes that could occur when more than one volume with the same volume name is mounted; as APFS identifies volumes primarily using UUIDs, this mainly affects their presentation to the user.
When a container is to be unmounted, raw disk access is stopped, and only buffer I/O allowed. All background work with each volume is stopped. Provided that the volume isn’t a System or Data volume, unmounting starts, and the purgatory cleaner is then allowed to finish. Each volume is unmounted in turn, and once the total number of mounted volumes in that container reaches zero, the container’s vnode is closed, and that container unloaded.
Summary
- Storage is divided into large contiguous blocks of partitions using a GUID Partition Table.
- Each APFS partition contains a single APFS container, within which are individual file system volumes, each sharing the space within that partition.
- An APFS container stores all the higher-level information common to the file systems within it, including volume metadata, snapshots, and provision for space management and crash protection. It also contains a single embedded EFI Jumpstart driver.
- Space Manager keeps track of free space within the container, allocates and frees storage blocks on demand.
- Reaper manages the deletion of objects too large to be deleted between file system transactions.
- Copy-on-write saves changed data completely before old data is made inaccessible.
- If a container isn’t unmounted cleanly, its latest valid checkpoint is that with the highest correctly formed transaction identifier, and is used to locate the container’s object map and each volume’s superblock. This provides crash protection.
- An APFS volume has its own superblock, containing the locations of its root file system B+tree, the extent reference B+tree, and the snapshot metadata B+tree, as well as the volume object map.
- Volume names have a maximum length of 256 Unicode characters, and conflicts are resolved by macOS.
- Volume personalities are case-sensitive (iOS, macOS Time Machine backups) and case-insensitive (macOS default). Each can be encrypted or unencrypted, and can have a role assigned, such as System, Data or Backup.
- Volumes can have reserve (minimum) and/or quota (maximum) sizes set when created, but those can’t be changed later.
- Object maps provide the physical address for stored objects given their OID and transaction identifier, XID.
- Mounting starts with the container, then proceeds with each volume, and for supported media an initial trim is performed.
- Unmounting stops storage access, unmounts each volume in turn, and when the number of mounted volumes in the container reaches zero, the container’s vnode is closed, and the container unloaded.
Articles in this series
1. Files and clones
2. Directories and names
Reference
Apple’s APFS Reference (PDF), last revised 22 June 2020.
