APFS was primarily developed for solid-state storage in Macs and Apple’s devices down to the 8 GB on the earliest series of Watch. As a modern file system it has features that cater for SSDs rather than hard disks, among them its use of copy-on-write and clone files. This article explains how they work, and their impact on different storage media and the user.
Copy on Write
One of the big enemies of hard disk storage is fragmentation. When the storage blocks containing a file’s data get split up and occupy different locations on the platter, reading and writing that file takes longer as the heads have to seek those locations. To minimise fragmentation and time spent seeking, hard disks try to store each file in contiguous storage, and where possible to overwrite existing blocks.
SSDs are in effect the exact opposite: there’s no seeking involved, but the erase-write cycle takes most time, and each erase eats into the expected life of the SSD. Overwriting existing storage would be painfully slow, though, as it would have to be erased first. Instead of trying to write in place, APFS therefore tries to copy on write (COW).
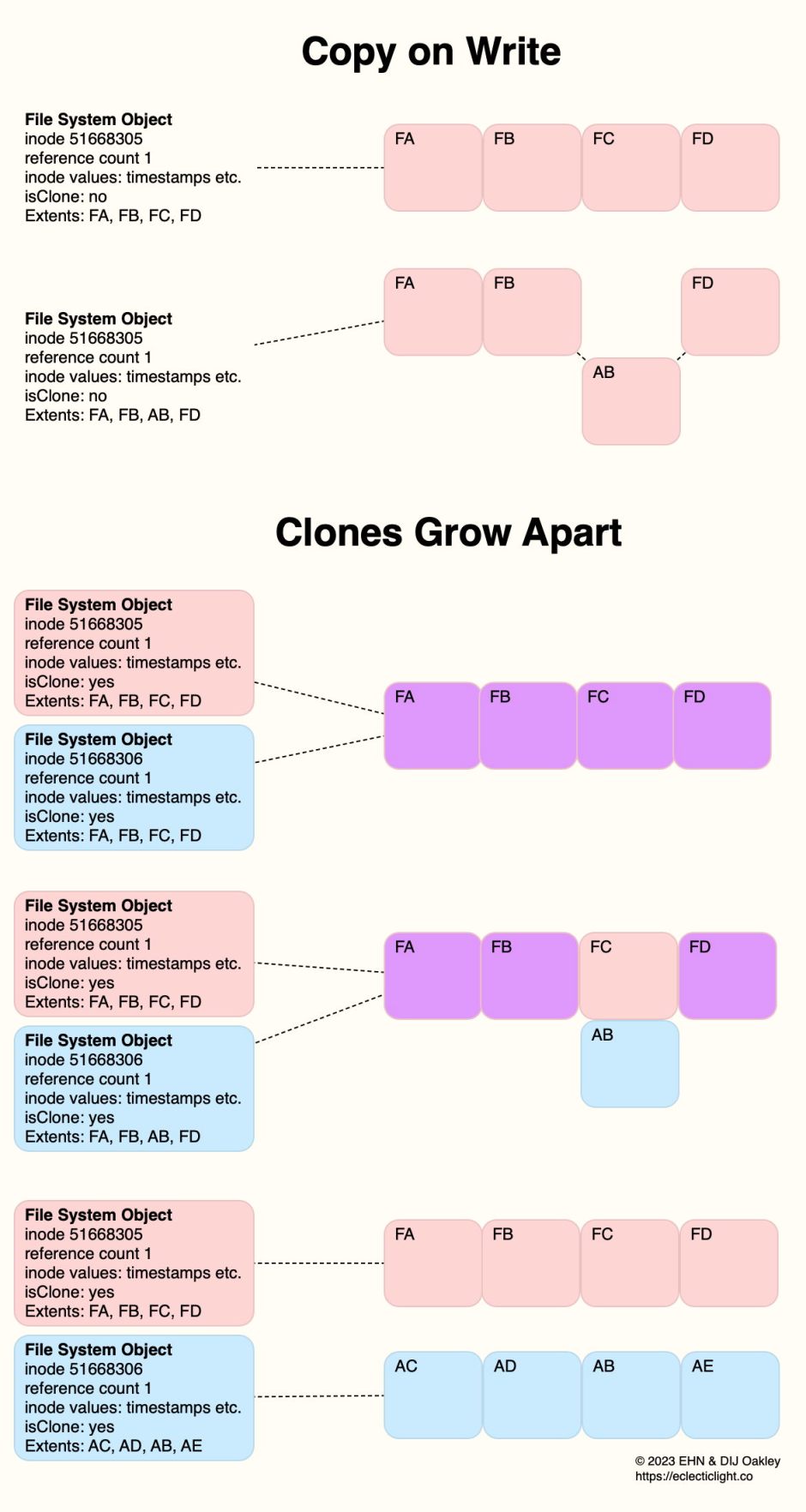
Take an example of a file initially occupying four contiguous blocks of storage FA-FD.
When the content of block FC is changed in an edit, that block is written out to a new location, copied on writing. On a hard disk, that would be a bad move, as the file has become fragmented; when reading it from disk, the heads would have to seek from FB to AB and back to FD. On an SSD, AB will already have been erased during housekeeping, ready to be written to, so COW is quickest. It’s also a lot safer, as the old block FC won’t be erased immediately. If anything goes wrong during the write, the file system can easily fall back to its previous state. If snapshots are being made, then the data in FC won’t be erased until it’s no longer required by a snapshot. COW thus has multiple roles in APFS.
Clones
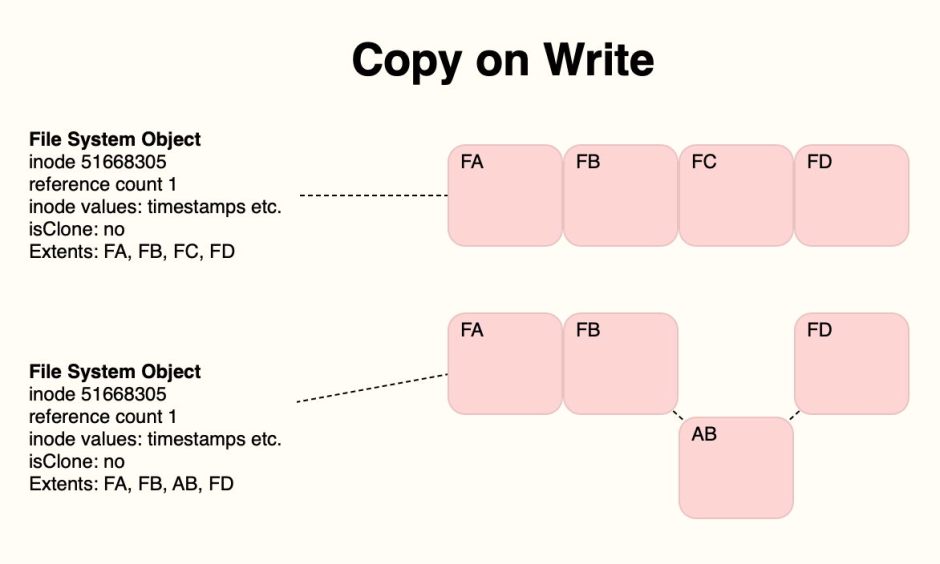
You’ll recall from my previous article that an APFS clone pair consists of two File System Objects that share the same data to begin with. For this example, I’ll colour their shared storage blocks in purple, and their unique blocks in pink or blue depending on which file they belong to.
When the clone pair is first made, they’re very efficient, as the pair only takes up the space of a single file, apart from the second File System Object, which is relatively small.
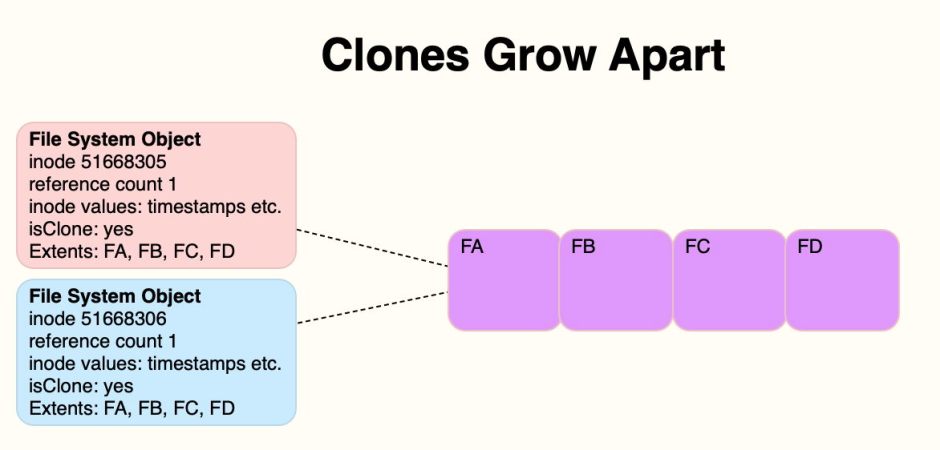
If you then open the blue clone and make changes to what has been stored in block FC, under COW those will be written out to a new block at AB.
After this first edit, the pink file’s data is stored in blocks FA, FB, FC, and FD as it was originally; the blue file’s data is now stored in FA, FB, AB (changed data) and FD. As this follows COW, it minimises the amount of storage required, now a total of just 5 blocks, minimises erase cycles on the SSD, and is safest in the event of anything going wrong. It also doesn’t require any additional space to be kept in a snapshot.
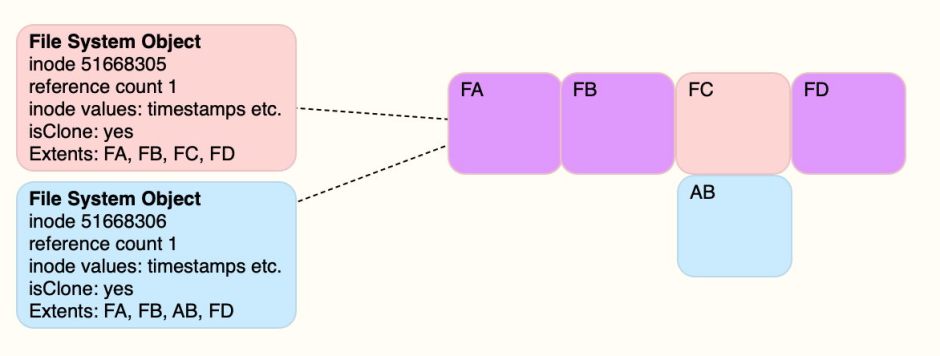
Eventually, changes made to the cloned pair of files reach the point where they differ in each of their storage blocks, and are effectively completely separate files.
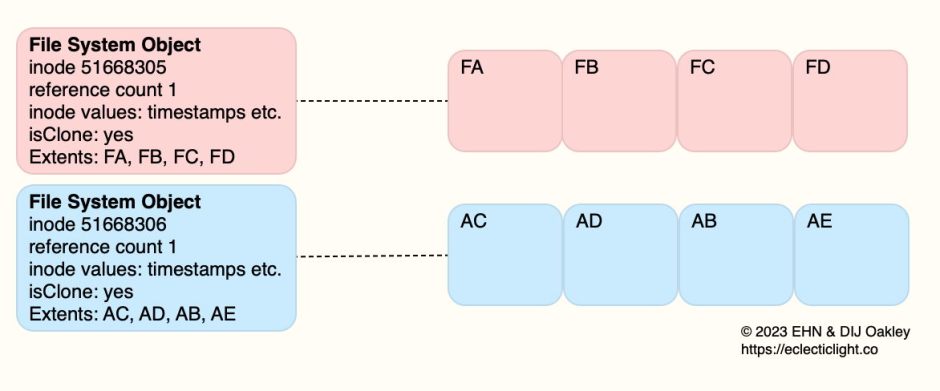
Now the pink file’s data remains stored in FA, FB, FC and FD, but the blue file’s data is in AC, AD, AB and AE. The two files now take twice the storage space that they did when they were first cloned, and a total of four extra blocks that need to be retained in any snapshot.
This explains how the space occupied by clone files usually increases over time and editing, and how the disk space required by a snapshot also grows over time. Normally, file systems like APFS report the space actually used at that moment in time, and can’t predict its growth potential in the future. So when you are editing a clone file, even though the size of the file you’re editing may not change, the space it requires in storage is likely to increase.
In this simplified example, the end result wouldn’t be particularly bad on a hard disk. In reality, file changes are much messier and fragmentation is more severe. But in APFS the sting in the tail, that causes most performance problems, isn’t so much in the file data as the file system itself. As that changes it becomes fragmented, forcing many more seeks to access objects and their structures, until it all comes to a grinding halt, with no easy solution. No file system can be ideal for all storage media.
Summary