
In my first article looking in detail at how Visual Look Up works, I considered a painting, which resulted in a search type of knowledgeSearch.art. As others have pointed out, recognising an image of a painting isn’t entirely novel, as that’s something already available using Google Image Search, although that’s less convenient and less informative than using Visual Look Up. What isn’t readily available elsewhere is identifying the breed of dog, species of flower, or well-known landmarks. This article examines how those are performed in Visual Look Up (VLU), and how they contrast with Live Text.
VLU operates the same way when working on photographic images as on those of paintings. In Preview or Photos, image analysis starts shortly after opening the image; in Safari or a WKWebView, it starts when the user opens the contextual menu for the image, using Control-Click. These initiate the first of the two phases, in which the image is analysed, classified and objects within it are detected and subjected to similar analysis.
Once those are complete and the white dot shown on the recognised object, Visual Search can be performed, either automatically or by clicking the white dot. This results in VLU sending Apple’s servers NeuralHash(es) for the object(s) identified, and the return of search results, which are then displayed in a floating window. In addition to using the search category knowledgeSearch.art, others used include knowledgeSearch.nature (flowers), knowledgeSearch.landmark (landmarks) and pets (pets).
Analysis
The same Analyzer and MAD Parse processes start the analysis phase, with a Visual Search Gating Task and entitlement check. Iterative use of neural networks is performed using the same method, which on an M1 Mac with its Apple Neural Engine (ANE) starts with discovery of the ANE and its services. mediaanalysisd then declares search purposes, such as coarseClassification or objectDetection, or categories. Espresso creates and destroys contexts, creates a plan, and loads the network. When those have been completed, search categories are declared for the search to be performed.
The ANE is referred to in several log entries as an H11; I’m grateful to @jankais3r for pointing out that this may be misleading. The H11 was the ANE included in the A12 chip, and it’s thought that the model in M1 series chips is the H13 instead, which appeared in the A14 as well. It may well be that the macOS API continues to refer to the ANE as H11ANE, even though it’s now the H13.
Visual Search
The same white dot is used to indicate the analysis is complete and VLU is ready to search the object(s) it has identified and generated NeuralHashes for. Where multiple objects have been recognised, multiple white buttons are shown, located in the centre of each of the objects. It’s early during this phase that mediaanalysisd declares the search categories.
As VLU works currently, objects of categories other than knowledgeSearch.art can’t be recognised within an image which has been assigned the category knowledgeSearch.art. This allows VLU to identify paintings within a painting, but not dogs, flowers or landmarks within paintings. The latter three categories only appear to be recognised when the whole image isn’t categorised as knowledgeSearch.art, that is a photographic image.
An identical TLS 1.3 connection over port 443 is then used to send the search queries to Apple servers, and the result is processed and displayed in the corresponding VLU floating window.
Live Text
Triggering Live Text recognition is quite different from VLU. This appears to occur when the pointer is placed over the part of the image containing text which can be recognised. Although the same Analyzer and MAD Parse processes are started, instead of starting a Visual Search Gating Task, a Document Recognition Task is run instead. This doesn’t require any entitlements, and after loading a couple of neural networks, mediaanalysisd creates a Composite Language Model and Linguistic Data are queried. MRC Parsing is completed quickly, which ends the MAD Parsing and calls a completion handler.
These can occur whenever it’s considered that an image may contain text. For example, an area in which there is a regular pattern which could conceivably be text can trigger this in an image which also contains a recognisable pet.
As far as I can see, these only confirm my original graphical summary:
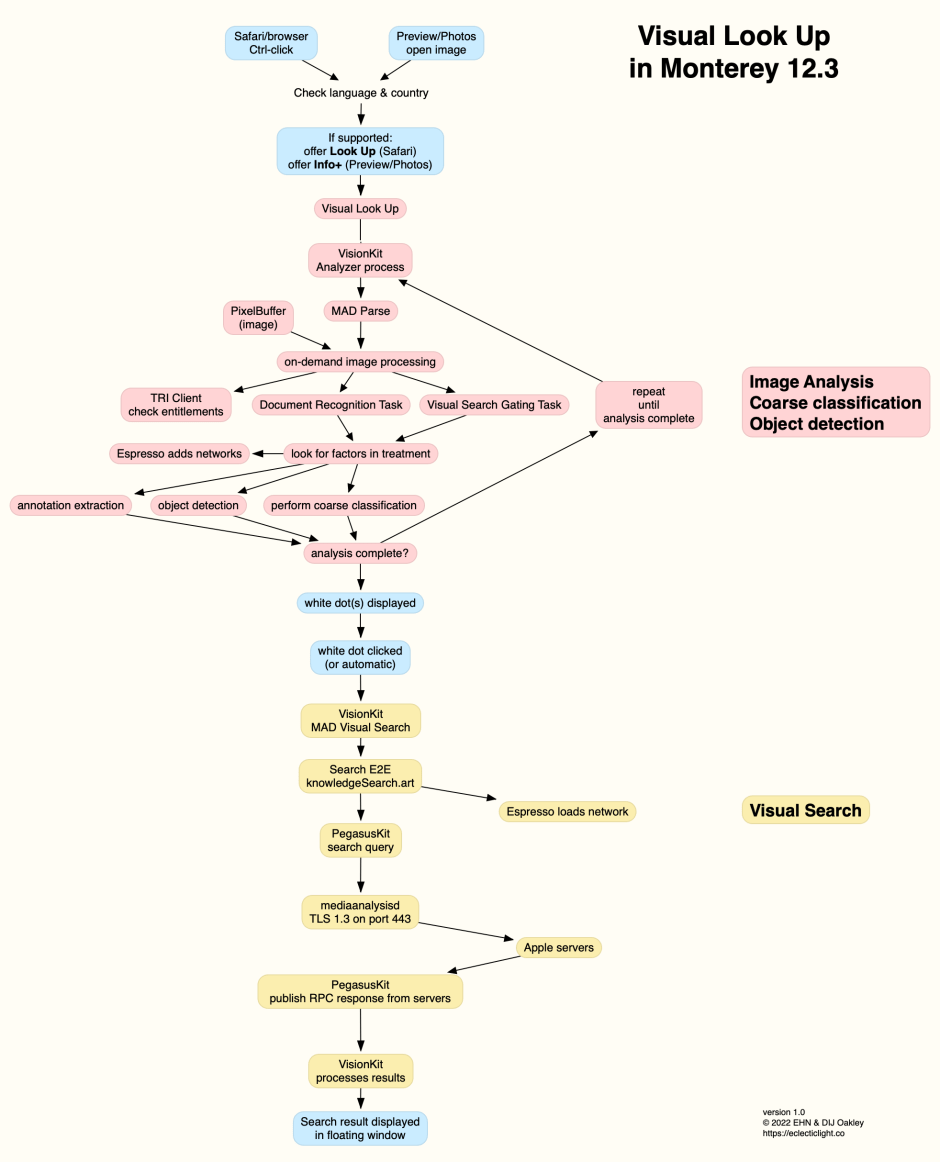
and its PDF: VisualLookUp1
I’ll next be looking at what can prevent VLU from working.
