
Originally, there wasn’t a great deal to file systems and files. A file was simply a chunk of data written to disk, and the file system was just a way of finding that, giving it a name, etc. Computers have come a long way since then: not only have file systems like APFS become far more sophisticated, but files themselves aren’t simply flat chunks of data. This article explains what now makes up what we treat as a file, in preparation for a more detailed look into its nooks and crannies in future articles.
In modern file systems, files are constituted from three different types of data, which are often stored separately:
- the data (or data fork), which is read and written by apps;
- the file’s attributes, which consist of all the metadata about the file, including its name, date of creation, permissions, etc.;
- any extended attributes, which contain supplementary information which isn’t part of the main data, but is richer than normal attributes.
Data
It’s up to the apps which use the data in a file to determine what format that’s in, and its content. At least, up to a point it is, because APFS adds some twists which aren’t entirely within an app’s control. The most notable and relevant here are sparse files, clones and compression. Support for these is set at a volume level, and can be inspected on mounted volumes using Mints.
Sparse files
Some files are largely empty, and for various reasons may be huge despite containing very little data. A simple example might be an image which consists of almost entirely white, with just a small object at one corner. In normal use, you’d use a compressed image format which would squeeze that down to a very small size. In specialist apps, it might be necessary to process very large arrays of data, of which only a very few cells are non-zero. Rather than trying compression, there are more direct ways of coding such empty arrays, and APFS can use them when storing such data in sparse files.
Outside of the system, on most users’ Macs, sparse files are likely to be unusual, and locating them isn’t easy. macOS has only recently gained a method by which apps can readily check whether a file is sparse, and that isn’t available on older versions. The simplest way to discover that a file is stored in sparse format is to compare its size with the storage space it requires.
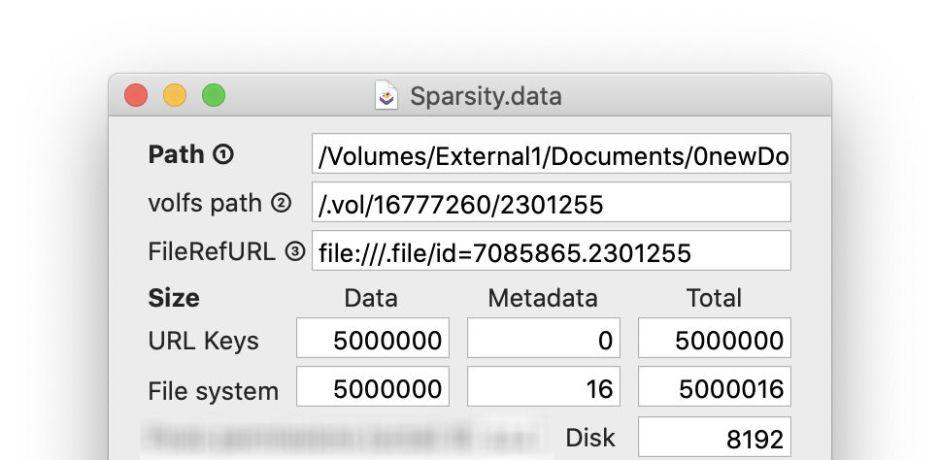
In this case, the file size is 5 GB, but it only requires 8 KB of storage, which is only likely to be achieved if it’s an APFS sparse file.
It’s not up to an app to determine whether its files are stored in sparse format. That’s for macOS to work out, depending on their content and the way they are written. I’ve just updated my little demo app Sparsity to its first full release so that you can experiment with sparse files. Set the overall file size you want using its controls, and click on the Save ‘sparse’ file button, and it will write a near-empty file containing just 20 bytes of data.
To ensure that macOS can save this as a sparse file whenever possible, the code used to write the file runs thus:
FileManager.default.createFile(atPath: url.path, contents: nil, attributes: nil)
create a new file at the path chosen by the user
let theFHandle = try FileHandle.init(forWritingTo: url)
create a FileHandle to that new file, for writing
let theData1 = Data.init([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
let theData2 = Data.init([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
initialise the two data blocks to go either side of the empty area
theFHandle.write(theData1)
write the first data block
theFHandle.seek(toFileOffset: ((theSizeUnits * theSizeVal) - 10))
then move the write pointer the required number of bytes through the file
theFHandle.write(theData2)
write the last data block at the end of the file
theFHandle.closeFile()
close the FileHandle.
Unfortunately, writing a large block of data with zeroed bytes to a file URL won’t create a sparse file.
Sparsity version 1.0 is available from here: sparsity1
and I’ll be adding it to a Product Page shortly.
To accompany it, you can either use the Finder’s Get Info to compare file size with on-disk size, or the new version 1.11 of my app Precize, which provided the example shown above.
Experimenting with sparse files demonstrates how pernickety they are. Duplicate them in the Finder, rename them, or move them around on the same volume, and they remain sparse. Copy them to another volume or perform normal file operations on them and they usually become unsparse. macOS currently (10.15.7) appears unable to recognise many situations when it could preserve their sparseness. You’ll also encounter frustrating anomalies, such as the fact that copying a sparse file to an HFS+ volume (which doesn’t support them) takes as long as copying the file at full size.
Clones
File clones are a feature of APFS which are commonly used, outside the control of the user and apps, and almost undetectable, which makes them very hard to investigate without going deep into the largely undocumented internals of the file system.
The concept itself isn’t straightforward either. When you duplicate a file in the Finder, APFS doesn’t normally make another copy of that file, and you’ve probably noticed this happen instantly with some large files which would ordinarily take some seconds or longer to copy. Instead, APFS creates what is at first an imaginary copy in the file system data without copying any of the data in the file itself.
Later, when you open and change that cloned copy, instead of APFS writing out the whole file, it saves only those parts of the data which have changed, rounded up to whole storage blocks, as shown in the diagram below.

This may appear similar to making a hard link, but in that case both file system references link to the same file data. If you then edit that data, both links will see the same changes, as they’re fetching the same data from the same place.
APFS clones are now the default means of creating a ‘copy’ when copying or duplicating files within the same volume: simply hold the Option key down when dragging the old file to its new location. You can also create them in Terminal using the command
cp -c oldfilename newfilename
where the c option requires cloning rather than a regular copy.
They’re completely transparent to the user appearing as and acting like quite separate files; only the file system knows how much of the data may be in common storage, and that will reduce as they diverge in content with editing. Unfortunately, they tend to be less common when apps save to files, because in many situations that save is ‘atomic’, in that it creates a complete uncloned copy as a temporary file which is then moved or renamed, so preventing cloning.
Compression
Transparent file compression was introduced in Mac OS X 10.6, where it was used on HFS+, and it’s a feature of APFS too. It’s used extensively by Apple in system files, but until Big Sur hasn’t been well-supported for anyone else, as few tools seem to support it. This changes in Big Sur, with the arrival of AppleArchive. Because this is intended to be transparent to the user, it’s extremely hard to identify even in system files.
From Big Sur, third-party developers are being encouraged to use AppleArchive’s lossless compression of folders and files. It isn’t appropriate or intended for use on whole volumes, though. Apple’s recommended compression method is its own proprietary LZFSE, but LZ4, LZMA and zlib are also available for compatibility with other platforms.
In the next article, I’ll look at file attributes.
