

Most PDFs open reliably in all respectable viewers and editors, from Preview and my own Podofyllin to Adobe Acrobat Pro. Every once in a while, though, you come across one which doesn’t behave: the fractious PDF. This article looks at why this can happen, and what you can do about these documents.
I’m grateful for Tristan Hubsch who found one for me a couple of weeks ago, a thesis published in 2007 by Piotr Sułkowski. Even when previewing it in your browser, your suspicion should be aroused that this spells trouble, as you can’t select the text on its pages properly.
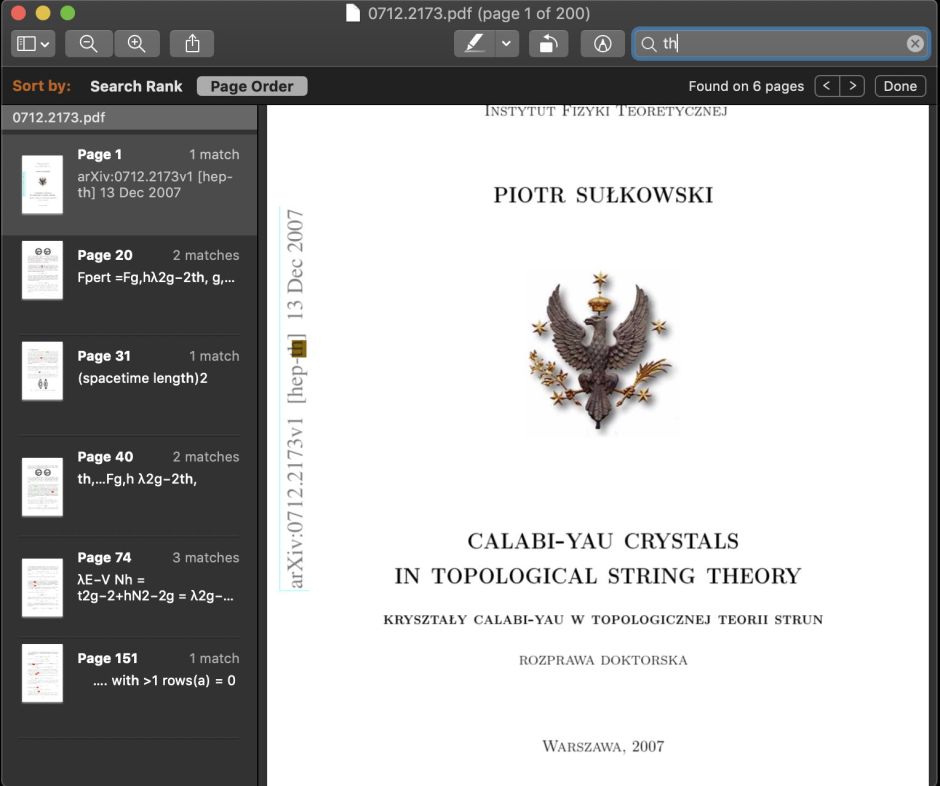
Tristan was naturally frustrated when he discovered that it was effectively impossible to search this document meaningfully when it’s opened in Preview. Type in a frequent pair of letters such as th, and it finds just six occurrences in the entire 200 pages. There are two common reasons for that type of failure in a PDF: either you’re looking at scanned images of pages which haven’t been passed through OCR (optical character recognition), or the characters that you’re seeing are in unusual encodings which render them inaccessible to regular search.
Try opening the PDF using Podofyllin, and before you can even see it, you’ll notice that the app sits spinning the beachball for a long time before the document appears. For a mere 200 pages, that also spells trouble ahead.
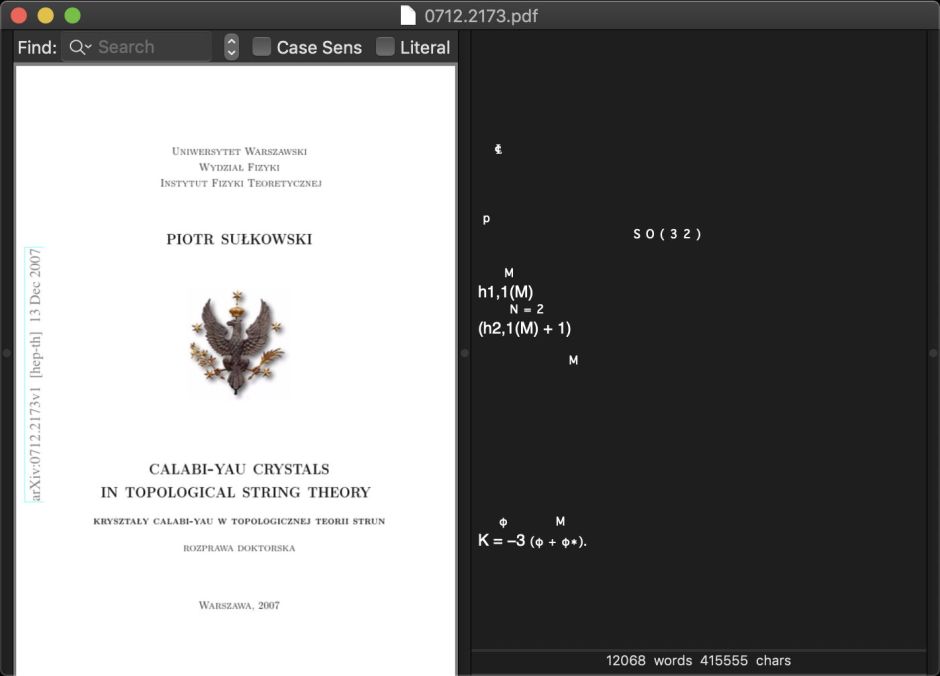
When it does eventually appear, the text view contains precious little, and what it does display there are fragmentary extracts from the equations in the document, and none of its text.
Opening its source involves another protracted appointment with the spinning beachball. When it appears, there are some important points to notice.
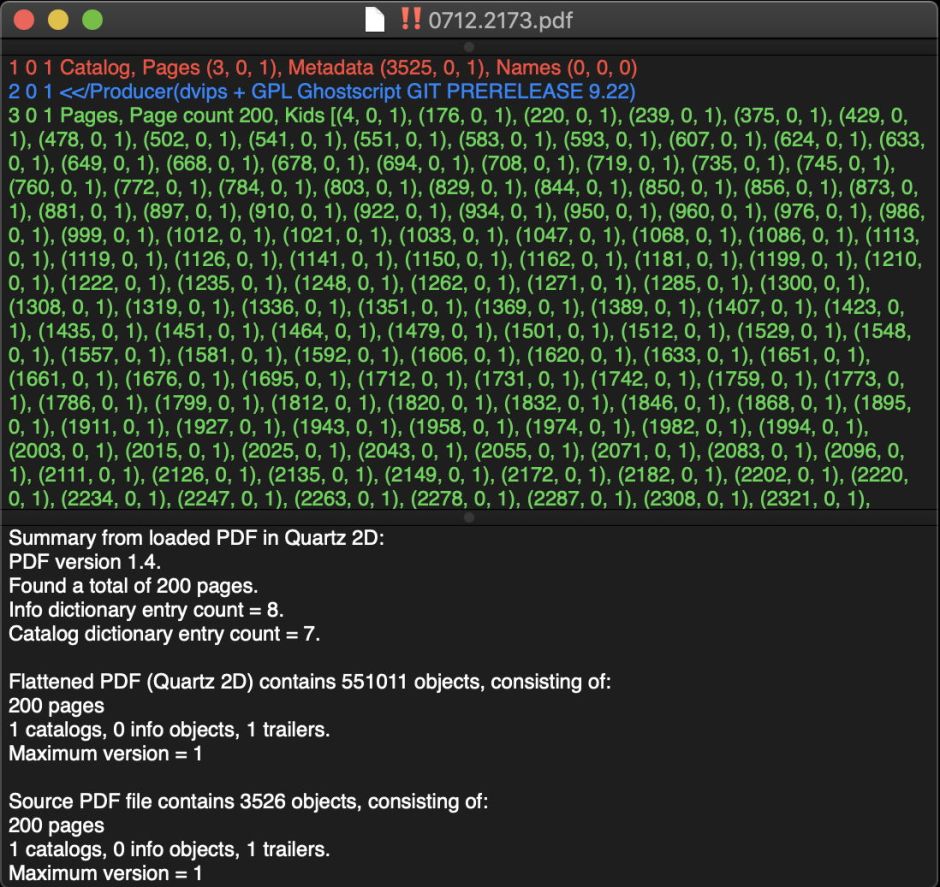
The document’s Producer is given as “dvips + GPL Ghostscript GIT PRERELEASE 9.22”. It’s never encouraging to see PDF which has been generated by this combination of tools, which started with a LaTeX original, rendered it into DVI (an ancient intermediary format used to image and print TeX), then into PostScript, and finally through to PDF. The current release of Ghostscript is 9.27, so at least the final rendering from PostScript to PDF has been performed by a fairly recent version, although it was in prelease form.
The version of PDF used is 1.4, which should be old enough for PDFKit to cope with in complete comfort. But the source PDF contains far fewer objects, 3526, than the more than half a million required by the Quartz 2D engine to render the document. There’s clearly something not right with this document.
Looking through its page contents, it uses a lot of custom fonts with names like NAUNZL+CMMI12. These are versions of the Computer Modern font family developed by Donald Knuth for use with TeX and LaTeX typesetting systems back in the 1970s, last updated in 1992, and almost certain to be completely ignorant of modern encodings like Unicode. There are a lot of Encoding objects at the end of the file which refer to WinAnsiEncoding: these encode text content using the Windows ANSI standard. At this point, you should prepare to run away from this document as fast as you can.
The Quartz 2D conversion of the original PDF consists almost entirely of XObjects, over half a million of them. These are objects which exist outside the normal PDF object structure, and their great number indicates a PDF engine trying to cope with near-insoluble problems in the source. The good news is that the PDF was generated quite recently, in 2018.
Other Mac apps which use the PDFKit and Quartz 2D engine in macOS have similar problems with this document, rendering it visually but unable to provide any useful access to its contents. The best solution is to try using Adobe’s engine, either in its free Acrobat Reader or, if you have access to it, Acrobat Pro.
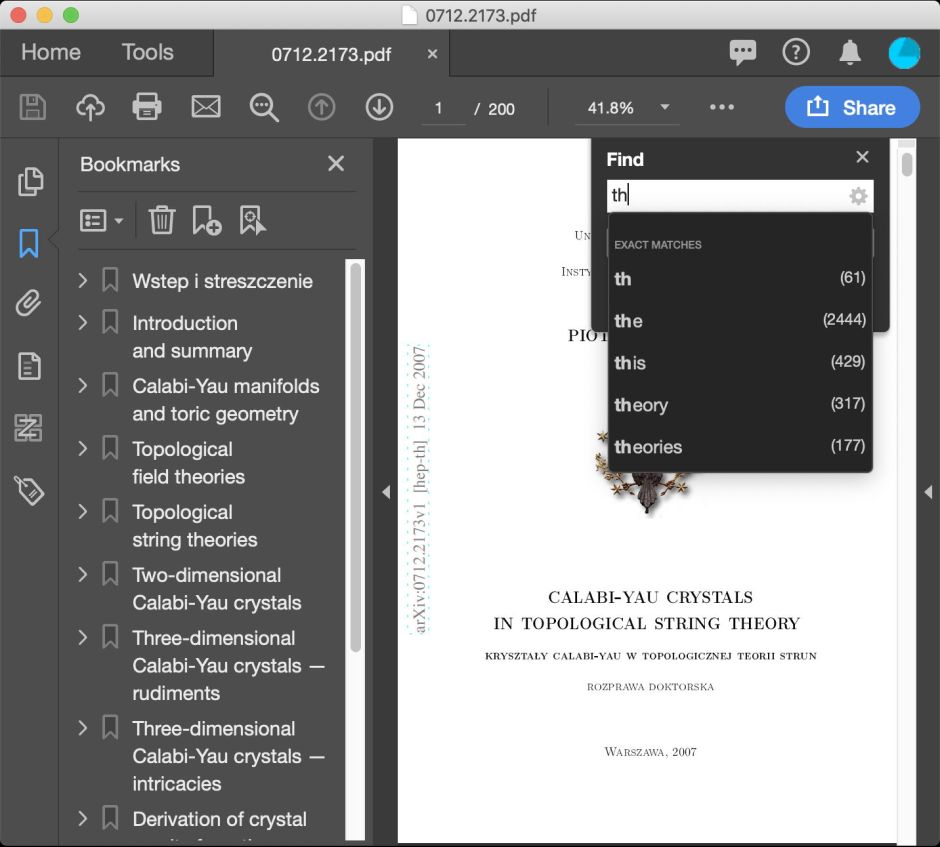
Sure enough, Adobe’s engine appears to come up trumps: its Find discovers many more instances of th, and all looks good at first. Acrobat Pro can save ‘optimised’ versions in formats back to PDF 1.3, and even compliant with the PDF/A standard, but oddly none of those versions behaves any better when opened using non-Adobe apps, and internally they are just as fraught as the original.
One excellent way of assessing this PDF is to see how well Adobe Acrobat can access its contents when it tries to export them. Here’s a sample paragraph as displayed by any of these apps, even Podofyllin and Preview.

I regret that I don’t read Polish, but that looks pretty good to me. But when the current version of Adobe Acrobat Pro exports that as text, it clearly disintegrates.
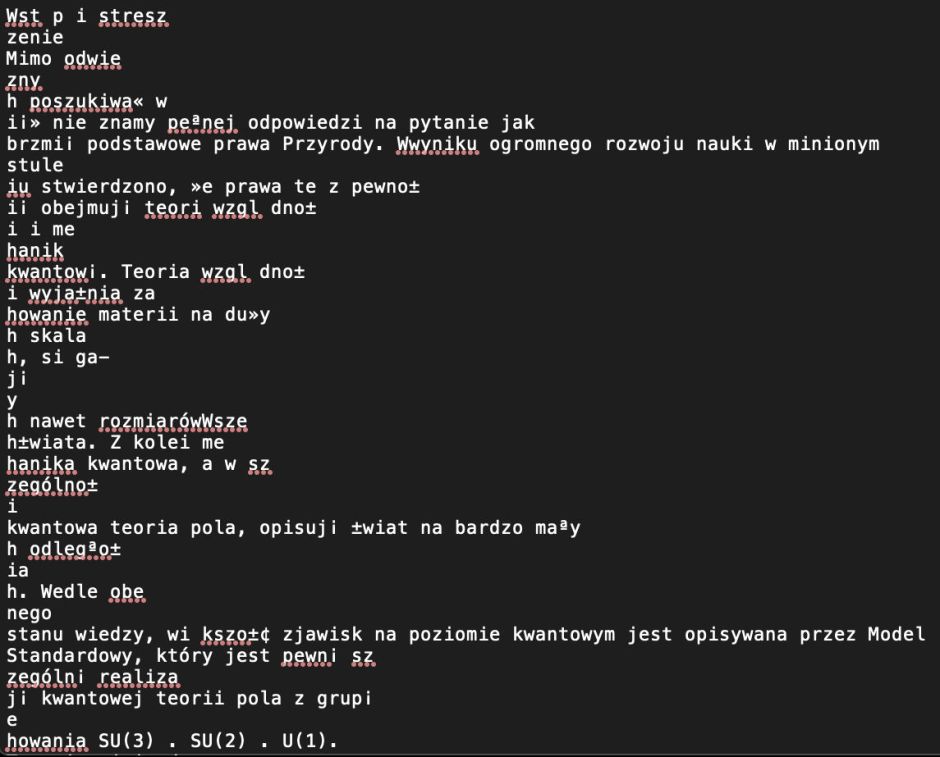
Exporting to Microsoft Word docx format is also disastrous.

This demonstrates that whatever Acrobat claimed it was doing in Find wasn’t actually working at all: even the benchmark PDF engine can’t reconstruct the text content of this document.
The reason for this is why we ended up with Unicode: before that existed, there was no coherent and consistent way of representing multilingual text. Unfortunately, instead of PDF standardising on Unicode to represent text content, it continued to support schemes which even Leonard Rosenthol’s excellent book on PDF stop short of describing properly because they are so complex.
This particular document started off life as LaTeX, using plain ASCII text with ‘special’ characters generated using escapes and macros. This was then converted into a DVI, which is intended purely for visualisation and not the preservation of content. That was then turned into PostScript, which again is intended to recreate the appearance of pages but not their text content, and finally arrived in PDF. It’s actually a miracle that any coherent text content has survived this.
If you want to access the content of such documents, the only way is to obtain the LaTeX original from its authors. Everything downstream of that will progressively corrupt its contents, and PDF is only really the finishing touch.
