
When you first open a PDF file using a text editor like BBEdit or my Podofyllin, it may come as something of a shock if you’re reasonably familiar with modern file formats, such as Property Lists or Rich Text.
One thing that you’ll probably find most daunting is that PDF mixes ASCII text (not Unicode UTF8, but plain old single-byte ASCII) with binary data. To see the structure of PDF files you don’t need to worry about those streams of binary, which are compressed series of drawing commands and similar, and can be left to the app to figure out.
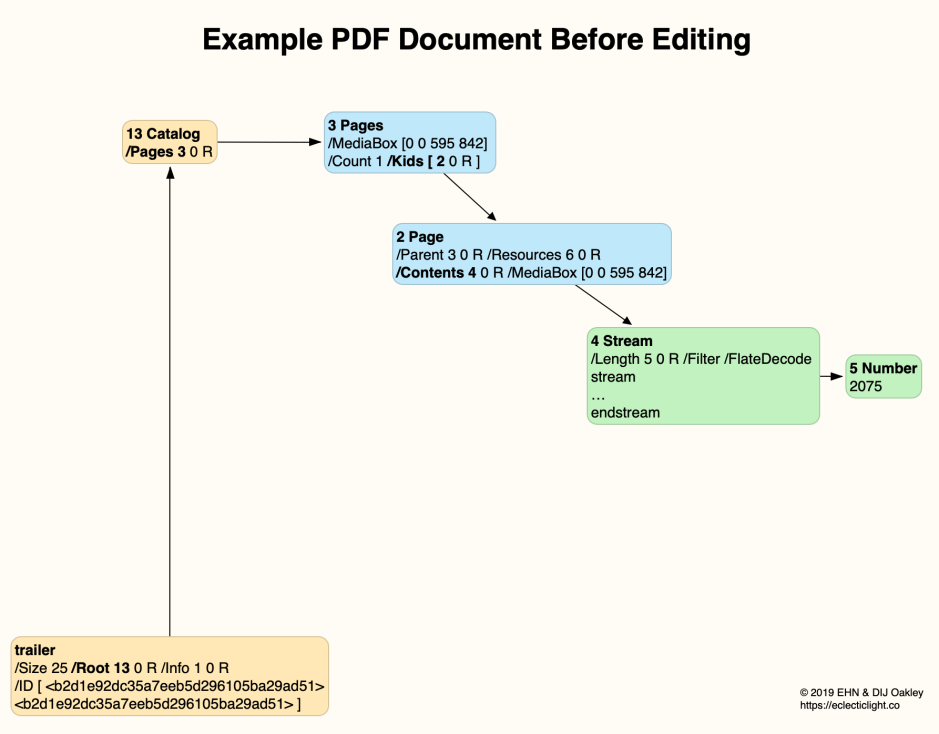
To remind you, a basic PDF file consists of four main sections:
- a brief header which declares the PDF version used,
- the body, which is a succession of objects, which form the content of the document,
- a cross-reference table, which lists the locations of all objects in the body,
- a trailer, containing among other things the object identity of the Root object in the body.
So the first two lines that you’ll see are the header:
%PDF-1.3
%Äåòåë§ó ÐÄÆ
where the first declares the version of PDF standard used, and the second are arbitrary bytes to inform software that this isn’t just a plain ASCII text file after all.
Then comes the body. Each object is declared like this:
4 0 obj
<< /Length 5 0 R /Filter /FlateDecode >>
stream
…
endstream
endobj
The first number (4) is the object number, the second is the generation number, which is almost always 0. The ellipsis … here indicates that this is a binary compressed stream which should be decompressed using the Flate method (essentially Zip). Normally, the Length is given directly, but here it is stored in another object, number 5, which gives that integer directly:
5 0 obj
164
endobj
Objects aren’t usually given in numerical order, and the most important are normally towards the end of the file. After various other objects, we find a Page definition, in object 2:
2 0 obj
<< /Type /Page /Parent 3 0 R /Resources 6 0 R /Contents 4 0 R /MediaBox [0 0 595.2756 841.8898] >>
endobj
This page states that its contents are in object 4, which was the initial binary stream shown above. Next is the list of Pages, in object 3:
3 0 obj
<< /Type /Pages /MediaBox [0 0 595.2756 841.8898] /Count 1 /Kids [ 2 0 R ] >>
endobj
The Count tells us there’s a single page, and it’s listed in the [] bracketed array of Kids – object 2 which we’ve just read. After that comes the most important object of all, the Catalog, which is number 13:
13 0 obj
<< /Type /Catalog /Pages 3 0 R >>
endobj
That tells us the list of Pages is in object 3, which again we’ve just seen. The other major top-level object is the Info, which is defined rather later. Before reaching that, there’s a series of objects which will be used for its contents. Each defines a string within parentheses ():
20 0 obj
(Untitled)
endobj
21 0 obj
(macOS Version 10.14.3 \(Build 18D109\) Quartz PDFContext)
endobj
22 0 obj
(TextEdit)
endobj
23 0 obj
(D:20190212203628Z00'00')
endobj
24 0 obj
()
endobj
25 0 obj
[ ]
endobj
Those are then assembled into the metadata object, Info:
1 0 obj
<< /Title 20 0 R /Producer 21 0 R /Creator 22 0 R /CreationDate 23 0 R /ModDate 23 0 R /Keywords 24 0 R /AAPL:Keywords 25 0 R >>
endobj
At the end of the body of objects comes a cross-reference table, which I won’t examine in any more detail here:
xref
0 26
0000000000 65535 f
0000010818 00000 n
0000000279 00000 n
and so on, which lists the byte offset for each of the 26 objects defined in the body above, starting with object 0, which isn’t used!
Then comes the trailer. This gives the number of entries in the xref table above, the number of the Root object (which is the Catalog, object number 13), and the metadata object (Info, object number 1). There are then two unique ID numbers, and the final code before the end of the file.
trailer
<< /Size 26 /Root 13 0 R /Info 1 0 R /ID [ <ade3a1567097542113ddff95fb3ddeff> <ade3a1567097542113ddff95fb3ddeff> ] >>
startxref
10962
%%EOF
These can be diagrammed readily (some minor details differ here, as the diagram was drawn from a different file).
When a PDF has been edited and saved incrementally, after the first cross-reference table and trailer, you’ll find more objects and new cross-reference tables and trailers. These are quite distinctive features which indicate that the file hasn’t been ‘flattened’ into a simple structure, and could thus contain orphaned objects.
The last of those might look something like:
xref
1 1
0000013664 00000 n
26 2
0000000000 65535 f
0000000000 65535 f
30 2
0000000000 65535 f
0000013644 00000 n
trailer
<< /ID [<ade3a1567097542113ddff95fb3ddeff> <ee8f2d1cab9f74a735cb85e8ad95713f>] /Info 1 0 R /Prev 13264 /Root 16 0 R /Size 32 >>
% PDF Expert 6110 Mac OS AppStore d18729114cca+
startxref
13827
%%EOF
where the editing app has been kind enough to embed a comment (with the % mark) to identify itself.
As usual, the PDF standard also supports different variations and special cases, but for PDFs written on macOS, most should stick fairly closely to what you see above.
I wish you bon voyage in your journeys through PDF files.
