
One of Mojave’s major new enabling technologies is its support for parsing natural language. This is enabled and supported by its Machine Learning (ML) system, and is aimed at controlling apps (primarily on iOS) using spoken input. Speech recognition in Siri converts what you said into text, which an app can then analyse and act on.
This linguistic analysis is a valuable tool in its own right, for tagging natural language to help you learn and improve second languages, for grammatical analysis (are you using “too many” adverbs, for example, if you like grammatical prescription), and for translation.
At present, support for languages is relatively limited: in the first release of Mojave, the full features of linguistic analysis are only available for five as far as I can tell: English, French, Spanish, German, and Russian. But Apple is clearly working on many other languages, and Mojave can already recognise many more, although it doesn’t yet seem to like Esperanto in the slightest.
The main support files for this appear to be in RequiredAssets bundles in /System/Library/LinguisticData, but there are also some additions which appear to relate to more dynamic models in ~/Library/LanguageModeling. According to Apple, improved language models and linguistic data are among the data files which will be updated silently and in the background, so we may not have to wait for full macOS updates to obtain improved support.
Adding new languages is dependent on the availability of suitable corpora. Any macOS developer can use the ML support in Xcode 10 to build support for a new language, provided that they have access to sufficient databases of texts in that language in which words are classified into parts of speech. Those databases are then used to train a new classifier model. The main limitation to this is the availability of suitable corpora: in the case of many ‘Latin’ languages, they are widely available, but many other major languages remain poorly supported at present.
I’ve been testing out twenty different languages, from العربية (Arabic) to Türkçe (Turkish), and am impressed at how well the current implementation of linguistic analysis works with multiple languages. It seems able to recognise the switch between language instantly, even when a language isn’t yet supported in full analysis.
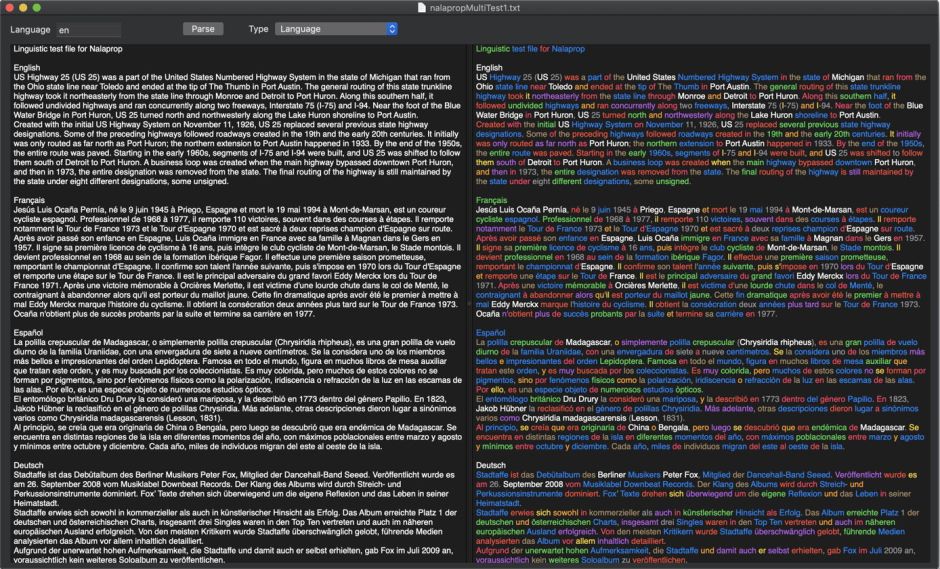
While Mojave was still in beta, I put together a small app Nalaprop, which uses linguistic analysis to mark up text according to parts of speech. I have just added a little colour key to it, and bundled my test file with passages in those twenty languages, in version 1.0b3 of Nalaprop, now available from here: nalaprop10b3
and from Downloads above.
If you’re studying a second language, interested in different languages, or just plain curious, I hope that you’ll find it interesting, and a demonstration of just what Mojave can do. But I am afraid this does only run on Mojave: High Sierra and earlier lack the support for linguistic analysis.
