
A week ago, I explained how to compare two files, to see if they were in every respect the same, in particular whether their extended attributes were identical. Although that article stands, I didn’t consider a special situation: when the files in question are archives, compressed or not, which contain other files. Just for good measure, they could be encrypted too, if you want.
To understand how to tackle this, you need to understand what happens when an archive is made.
Normal ‘native’ files consist of three main types of data:
- the attributes, including basic information about the file such as its name, date of creation, and other admin information about it;
- the extended attributes, or xattrs, which are not stored with the file, but in the file system metadata of that volume;
- the data (‘data fork’), which is the content that you normally get to see, such as the text content of a text file.
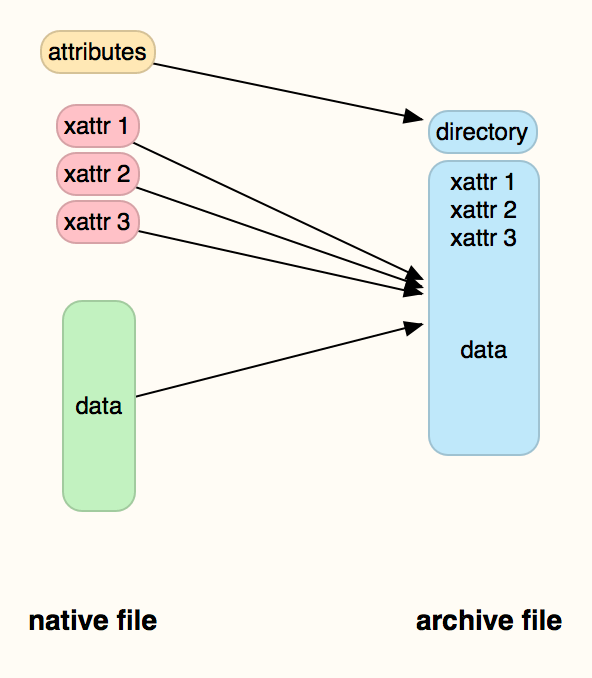
When they are turned into an archive, which might be compressed and/or encrypted, those three parts are flattened together. The attributes are mostly put into a directory section of the archive file, and the extended attributes and data are then put together into the data (‘data fork’) of the archive file.
I don’t know of any archive format which keeps the extended attributes as xattrs. This makes it simple to preserve the extended attributes even when the archive may be stored on a file system or storage which doesn’t understand xattrs at all. Only when you unarchive the file is the data stored from the file’s xattrs turned back into extended attributes, and tucked away in the file system metadata.
Given that, how can we reliably compare two archives, to tell whether their contents are identical?
The processes of archiving and unarchiving involve one-to-one mappings. Using the same method of archiving, there is only one archive which can be made from each file, and each archived file can only unarchive into one file. So comparing the two archives using a binary comparison tool such as cmp will reveal whether their contents are identical, so long as the archives were built in an identical manner. So the first and simplest test is to compare the data fork of the two archives:
cmp archive1.sitx archive2.sitx
The snag with this is that it is usually possible to build two or more archives which contain exactly the same files, only in a different order. Although those would then actually contain identical files, simple comparison of the archived files would incorrectly report them as being different. This could also occur if the same files were archived using different versions of the archiving tool, which write the archive using a slightly different structure.
The next step, then, if the initial comparison suggests that their data forks may be different, is to unarchive their contents into a temporary folder, and compare those contents one file at a time. If you’re wanting truly identical archives, then an easy approach here is to step through each file in archive A, find whether there is an identically-named item in archive B, then compare those two with respect to their data and xattr contents.
Keep a tally count of the number of files checked in archive A, and at the end ensure that matches the total number of files in archive B. If you don’t do that, you won’t discover when archive B contains files which are not in archive A at all.
I can think of three additional twists which can make this more complex still.
Do you want to know details of the differences, or is it sufficient to know whether they are identical, or different? Working through detailed comparisons to detect and report all the differences can be quite demanding, and you could end up with a report listing thousands of differences, which get messy to handle.
How close do you want these files to match? You may want to build in tolerance for differences in attributes, such as different creation/modification dates, or even different names, provided that the data forks and xattrs match identically. Flexibility here comes at the cost of complexity.
Some archive formats store files using a standard flattened format, so you could simply extract that flattened format (in which xattrs are effectively part of the file’s data) and compare that as a chunk of data. That could be much quicker than unarchiving both the archives, and would probably be the preferred ‘professional’ solution.
If you simply want to know whether the archives contain identical files or not, it shouldn’t be hard to write an Automator workflow, AppleScript, or shell script based on cmp and cmpxat which will do this very well.
