
Some of the most important new features coming in High Sierra are the direct result of APFS, and several of those depend on one of its key features: copy on write. This article explains how that works, and how it brings us benefits.
The great majority of writes to disk occur when saving modified versions of existing files. Traditionally, whenever possible, these changes are written out to the same storage blocks already occupied by the files. This minimises the changes required to the disk: if you just change a few words in a text document, it makes good sense not to have to create a whole new file somewhere else, write the revised version of the file out to that, then delete the original file.
There are snags with that, though. If anything goes wrong in writing the revised version of the file, you normally lose both the original and revised versions. If you want to keep the original version (in a versioning system, for example), you then end up with two complete copies of the file, which wastes a lot of space if they only differ in a few words. Various solutions have been proposed to this, of which copy on write is one.
In the past, apps have tried to handle this themselves. One technique which has been used on the Mac is for apps to write each saved file out to a temporary file, then when that action appears to have been successful, to delete the original file and rename the temporary file. This is very slow, and prone to its own problems.
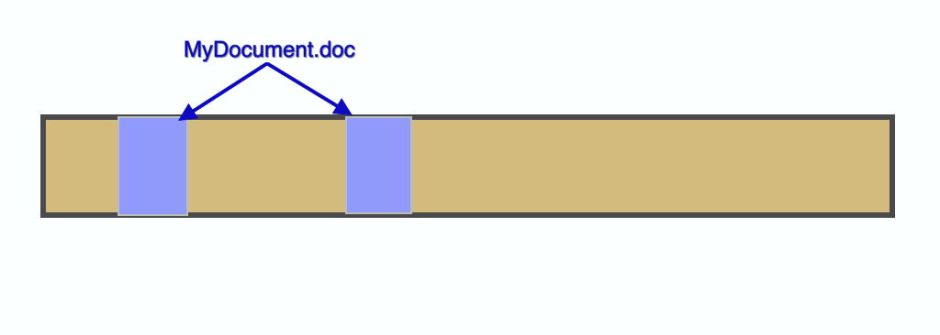
Let’s say that our original file consists of two blocks allocated from storage, for the document named MyDocument.doc. We then edit that file, and the changes are reflected in just one of those two blocks.
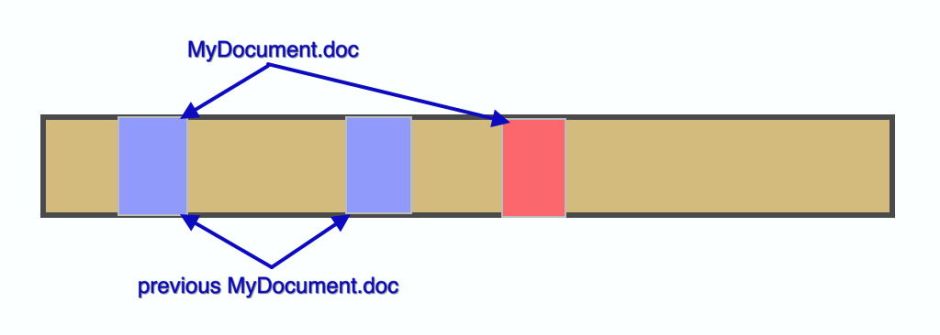
In copy on write, those changes are written out to a newly-allocated block on the disk, not the original. At that time, there are effectively two copies of the file on the disk: the two original blue blocks, which together make up the first version, and the first blue block and the pink one, making up the revised file.
There are several ways that this can be used. It provides a built-in versioning system (which Apple terms clones) which requires no additional effort on the part of the operating system or app: all that is required is to keep track of previous versions. By keeping a copy of the directory and other file metadata for any given moment in time, it also provides a snapshot of all the files in a given volume at that moment; you can then retrieve old files from that snapshot, or revert all files to that previous state.
Of course, eventually the blocks occupied by old file data will need to be freed up and re-used as free space, using the ‘trim’ command or an equivalent feature for an SSD. Provided that you have a reasonable amount of free space on that disk, and do not write excessive numbers of files out to it, these old versions and snapshots should remain for a useful period of time before they incur you any ‘cost’.
On SSDs, APFS also has to implement wear-leveling, which prevents individual memory segments wearing out prematurely. On hard disks, file defragmentation is important, and another background activity performed by APFS. These complicate copy on write systems, but all are becoming increasingly popular in other modern file systems such as Btrfs and ZFS.
APFS also uses a copy on write technique in its metadata (directories, etc.), which is claimed to ensure that changes to the file system are protected from crashes and faults. This makes journaling redundant, which significantly improves performance: when maintaining its journal, HFS+ writes changes twice, incurring significant overhead.
None of these features are new to APFS, but Apple claims to have implemented them particularly well. It will be interesting to see how they work out.
