

In the first and previous article, I pointed out how Turner and Cézanne were unusual in showing discrepancies in the reflections which they painted.
I was careful to avoid going into too much detail as to the optical principles in such reflections. Before going any further, it is worth running through them. They will help clarify discrepancies seen in other paintings, and are also valuable information for any painter who wants to get their reflections correct.
Basic optics
The fundamental optical principles underlying all reflections on water surfaces are:
- light travels in a straight line when passing through a medium of constant refractive index;
- when light reaches the interface between two media of different refractive indexes, some will be reflected from the boundary, and some will be refracted through the boundary;
- the angles between a ray of light incident on, and that being reflected from a boundary (between media of different refractive indexes), with that boundary surface are equal;
- a water surface with air above it presents a suitable boundary at which reflection and refraction occur;
- still water surfaces are horizontal planes which therefore act as horizontal planar mirrors as far as incident light rays are concerned.
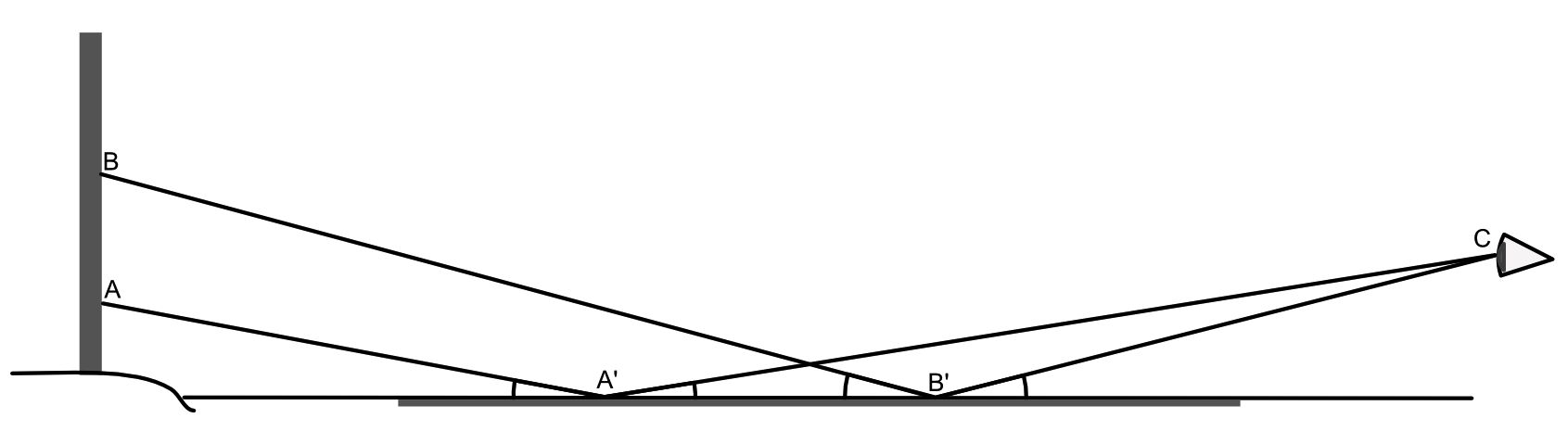
Here a post (with marks A and B), on the left of the diagram, is on the bank of a completely flat lake, with the observer on the opposite side of the lake at C, looking over the lake towards the post. A ray of light scattered from point A on the post passes over the lake to point A’. There, in passing from air to water, it reaches a boundary between media of different refractive indexes, and most of that light will then be reflected towards the observer at C.
Measured at the point A’ on the lake, the angle of incidence (between the ray and the horizontal water surface) equals the angle of reflection (between the ray and the water surface). The same process of reflection occurs to light scattered from point B on the post, with respect to its reflection at point B’ and the observer’s eye at C, although the angles at point A’ are less than those at point B’.
The relationship between heights above the water plane and the distances from the reflection on the water are a matter of simple geometry. Taking first the right-angled triangle formed by the points B, B’, and the base of the post, the perpendicular height of B above the water (H) and the distance from the base of the post to the point of reflection B’ (D) is the tangent of the angle of incidence of the light ray at B’, as H/D.
As the angle of reflection at B’ must be the same as the angle of incidence (point 3 above), the ratios of the heights at B and C to the distances along the water surface from the base of the post to the point of reflection, and the point of reflection to the observer, must be equal. Hence if three of the four variables are known, the fourth can be calculated, e.g. H = H’.D/D’.
This may seem complex and confuddling, but I strongly urge you to take some time, draw your own diagrams, and understand these basic principles, as they make everything else very much clearer and more logical. If they remain confused in your mind, then reflections will always be confusing.
Putting it together

Repeating this simple tracing of light rays enables visualisation of more complex examples of reflection, such as that shown above. It quickly becomes tedious for humans to trace individual light rays in a three-dimensional model, but computers excel at the task. The resulting image makes it clear that corresponding points in a reflection on water are vertically below their originals, although the slight waves seen here can result in limited lateral shift in the reflected points.
As is well known from real life, the reflected image in a horizontal mirror is effectively reflected on a local horizontal plane, so that the left of the original remains on the left of the reflection, but the reflected image is inverted (the top of the reflection shows the lowest part of the original); that is unlike reflections in a mirror positioned vertically, such as those in which we inspect our face, shave, or apply make-up, which (fortuitously) remain uninverted. Whether a mirror is vertical or horizontal, the left of the reflected image shows the left of the real image, and similarly for the right.
The patterning and slant of the pole illustrates the differences between such a reflected image and one that has simply been rotated through 180˚ (as might be achieved by a painter rotating the canvas on an easel). In the latter case the chirality (handedness) of the transformed image is opposite, the post would lean the opposite way, and the red spiral pattern on it would differ too.

Reflections in water are completely different from 180˚ rotation. Because mentally visualising reflection is a difficult task, I show above a composite image: alongside the original and its untransformed reflection, I have reflected the image of the reflection, and moved it up, alongside the original. This is similar to composite image which I used in the previous article, for example to show the problems in Turner’s Crossing the Brook (1815).

Complex 3D scenes

The reflections in a more complex 3D scene, above, show slight alteration in vertical dimensions, but remain strictly aligned with the original. Although the slight waves produce very small lateral displacements in the reflection, every point in the reflection corresponding to a point in the original remains in alignment across the width of the image.
Those objects at the front of the original remain at the front of the reflection: for example, the tree with red leaves retains its position relative to the green conifer tree behind it. The further back from the water’s edge that an object is situated, the more truncated is its reflection; truncation appears as if it occurred at the base of the original.

One useful rule of thumb that is sometimes given to gauge the effect of truncation is to imagine that the water extends right back to the base of the original, to construct the reflection on that imaginary water surface, then to erase the reflection on the water where it does not actually exist.
There are complex differences between the original and its reflection with respect to the position of details, tones and highlights. Although highlights are seen on the red leaves, their pattern is not the same, because the original leaves are seen direct, but those in the reflection are viewed as if from below and in front of the tree (from their points of reflection on the water).
This makes it impossible to create a completely accurate representation of a reflection unless you are able to see that reflection; even using modern ray-tracing software on a computer it is extremely difficult to construct or reconstruct a reflection from real life. Any painter who paints the original en plein air and later attempts to paint its reflection in the studio is only going to be able to guess its form and appearance, and will be unable to get tones and highlights correct with respect to those seen in nature.

The difficulties encountered in extensive reflections on water in the real world are illustrated in the composite image above. Note how the distant mountains almost disappear from the reflection with the change in vertical dimensions, but rigorous vertical alignment is maintained across the entire image. Painting reflections in images such as this is an incredibly difficult task without the complete view in front of the painter at the time.
Practical principles
Any faithful depiction of reflections on water will therefore show the following features:
- a line joining any point on the original with its equivalent on the reflection will be strictly vertical, allowing slight lateral shift resulting from the effects of small waves;
- an object which is behind another object in the original will also remain behind that object in the reflection, as reflections preserve depth order;
- the further back that an original object is from the water’s edge, the more its reflection will be cropped vertically;
- vertical cropping loses the lower section of the original from the reflection, and the upper section remains in the reflection;
- when the water surface is smooth, the position of reflections can be determined by simple geometry relating the height above the water surface to the distance between the point of reflection on the water and the perpendicular projection down onto the water plane (the tangent of the angle or incidence or reflection being equal to height/distance);
- the view of each part of the original seen in the reflection will be that as seen from the points of reflection, those being lower than the observer and closer to the original;
- what is seen on the (observer’s) left of the original appears on the left of the reflection, and what is seen on the right remains on the right of the reflection;
- because the reflection is vertically inverted, what is seen at the top of the original appears at the bottom of the reflection;
- the more the water surface departs from being a flat and smooth mirror, the more distortion will be introduced into the reflection, until eventually its form is lost in a series of vague areas of broken colour.
Further notes

Ripples in the water surface result in slight lateral shift in the reflected image, shown above in the green vertical lines, and can cause large vertical distortions, shown by the yellow horizontal lines. The resulting vertical scaling is impossible to predict without computer-based ray-tracing techniques, but may shrink the parts of the reflection showing the lowest parts of the original object, and magnify those of the higher parts of the original. Less bright parts of the original may be lost in the reflection, leading to what may appear to be very distorted reflections.

A more difficult but nonetheless pictorially fascinating issue is that of the perspective projection of features as seen in reflections.
In general, when considering reflecting surfaces of all forms and orientations, a reflection within an image is one of the very few examples in which two (or more) different but completely optically correct perspective projections can co-exist within a single image. However because of the simplifications which apply when considering only reflections on water, both the real and reflected (virtual) images share essentially the same projection, including vanishing points, as shown in Sisley’s Moret-sur-Loing, Morning (1892) above.
History
Although several early manuals on painting, such as that of Roger de Piles (1708), refer to the need to depict reflections accurately, detailed accounts first appeared in manuals on perspective, such as Brook Taylor’s in 1719.
Valenciennes’s Elements of Perspective (1820) gave sage advice to artists trying to tackle reflections, including those of the moon, and stress the vertical alignment of original and reflected images.
More recently, Rex Vicat Cole’s manual (1921) gives some good rules of thumb. However the rule of thumb which is often given — to extend the water surface to the base of the object, imagine the reflection as it would appear on that ‘virtual’ water, and then truncate that to the edge of the real water — is not strictly accurate.
Take a house on a hill some distance away from the edge of a perfectly-reflecting lake. To determine whether any of its reflection would appear on the lake, the hill under the house should be eroded to leave just a thin pillar directly under the house, so that the ground around that pillar is below the surface of the extended lake. You should then construct the reflection as it would appear on this extended water surface, before trimming the water back to its actual edge.
This may be both conceptually simpler and more accurate than working through geometric calculations using estimated heights and distances.
Cole also interestingly noted: “Though we have said that reflections are always vertically under the objects, I have noticed one is apt unconsciously to represent the reflection of vertical lines as very slightly inclined towards the spot we stand on, and I have seen them so painted, and I think rightly so, by artists of repute.”
Whether he had seen Turner’s leaning Ducal Palace and Custom-House, Venice: Canaletti Painting (1833), I do not know!
Unfortunately some recent accounts of painting reflections also give bad or confusing advice. One such is the recommendation to work on the painting when it is upside down, which can (because of the preservation of chirality in reflections) make them much harder to paint correctly.
References
Brook Taylor (1719) New Principles of Linear Perspective, or the Art of Designing on a Plane the Representations of All Sorts of Objects, in a more General and Simple Method than has been done before, London. (Not available online, and later editions omit much of the material on reflections.)
Cole, Rex Vicat (1921) Perspective, Seeley, Service and Co, London. (Available in various reprints, and Archive.org.)
de Piles, Roger (1708) Cours de Peinture par Principes, Paris. (Available at Archive.org.)
de Valenciennes P-H (1820) Élémens de Perspective Pratique à l’usage des artistes, 2nd edn., Paris.
