

Last Saturday, in my explanations about numbers on computers, I wrote that, unlike mathematical numbers, Double (64-bit) floating-point numbers on computers aren’t infinite, but are spread very unevenly. Here I show just how uneven that is, and its effect on the numbers that your computer calculates with.
Perhaps the easier of my two graphs to understand is that showing the density of Double values.
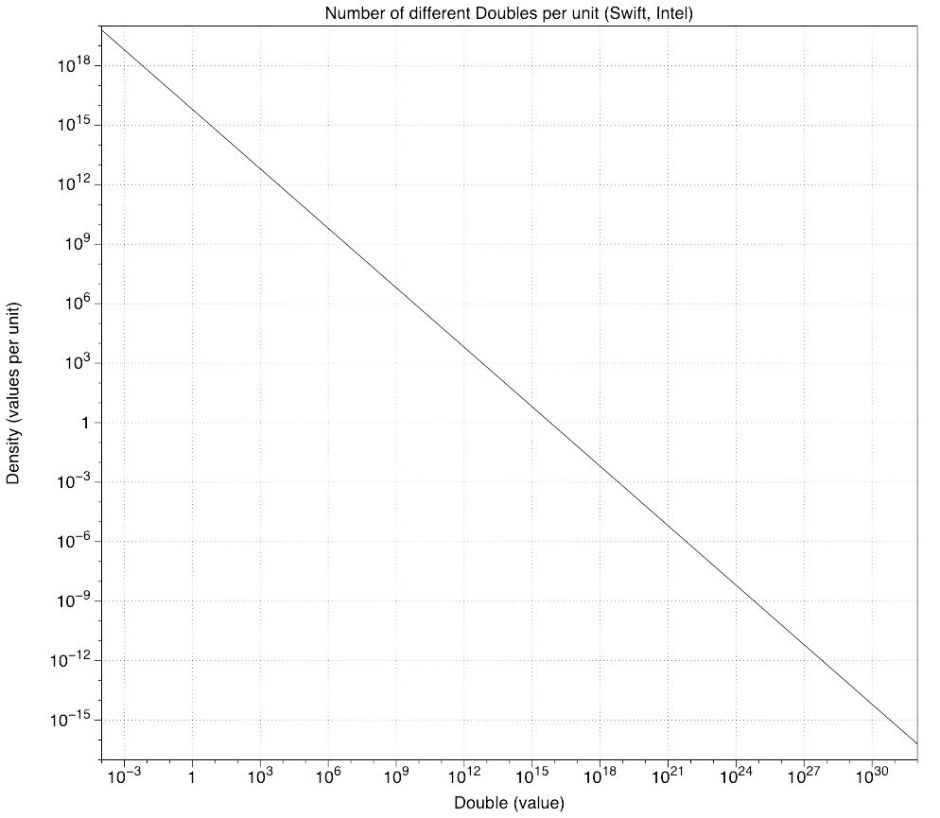
Both axes on this are logarithmic, for reasons which become obvious when you look at the values. Along the X (horizontal) axis are Double values ranging from 0.0001 up to 1.0 x 10^32 – that’s 1 followed by 32 noughts, which is far larger than even Apple’s annual revenue. On the Y axis (vertical) are the number of different Double numbers for each unit, that’s 1.0.
So at a Double value of 1.0, there are 4,503,599,627,370,496 different doubles for every 1.0 change in value – that’s a great deal of different numbers. At a value of 0.5 x 10^16, each step of 1.0 brings just one different Double, and at 1 x 10^32, there are less than 6.0 x 10^-17 Doubles in every change of 1.0.
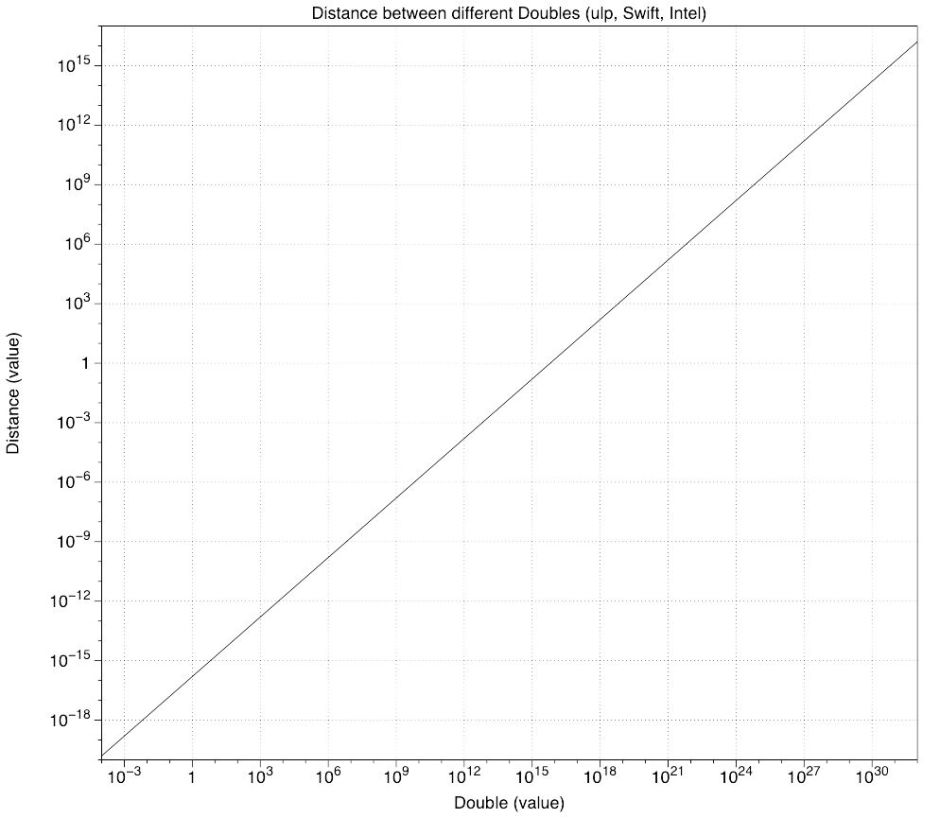
The other way of looking at this is what’s known as the ulp, effectively the difference between (different) consecutive Doubles. Around 1.0, they differ by around 2.2 x 10^-16, which is tiny by any standard. At 0.5 x 10^16, the difference is just 1.0, and when you get up to really huge Doubles at 1.0 x 10^32, consecutive Doubles are nearly 2 x 10^16 apart.
Negative Doubles behave as in mirror images of these graphs: the closer they towards 0.0, the more there are, and the smaller their difference. The more negative they become, the fewer there are of them.
This uneven distribution comes back to bite when you perform arithmetic with large numbers, particularly when subtracting two large numbers whose difference is relatively small. Indeed if that difference is small enough, the two large numbers might be represented by identical Doubles, making their difference 0.0. That’s a cancellation error.
