

Thanks to a tweet from Maggie Haberman of the New York Times, within a few minutes of the Mueller Report being made available for download, I had a copy on my Mac. The first thing that I did with it was look inside to see whether its extensively redacted content could be deredacted, or even recover an earlier version of the whole document. So I opened it in Podofyllin.

What was immediately obvious from the blank text view on the right is that, in the original, there is no text at all: this isn’t a PDF that’s been created by the app used to generate the document in the first place, but a scan which hasn’t even been passed through Optical Character Recognition (OCR) to reconstitute its text content.
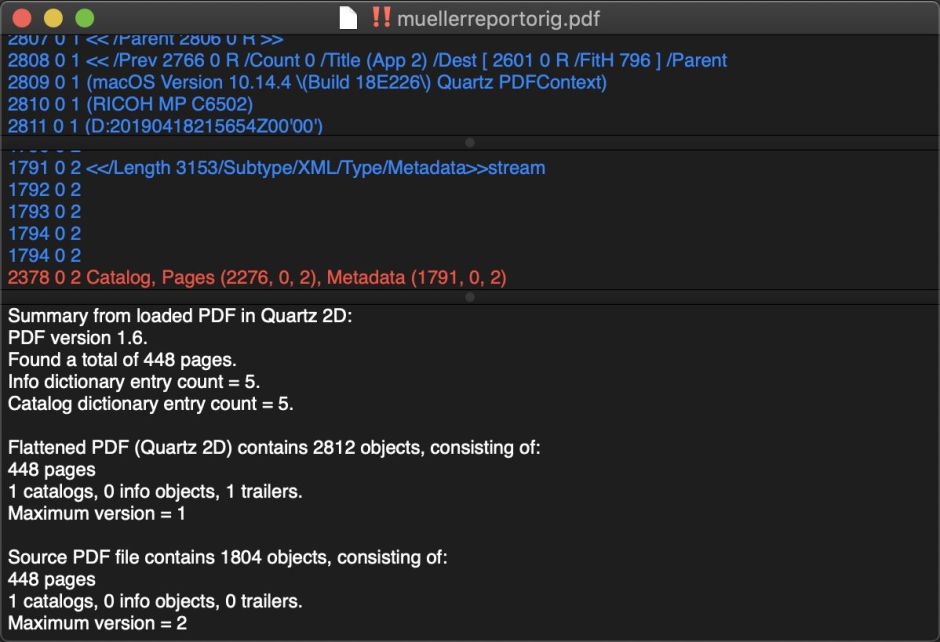
Sure enough, Podofyllin’s Source view reveals that it was generated by a Ricoh MP C6502 multi-function printer-scanner. Every single page in it has been scanned in from paper, where the redactions had already been made. Given that the redactions were clearly not made using a marker pen, but integral to the printing, what must have happened was:
- The original report was completed on a computer.
- That document then underwent electronic redaction.
- The redacted version of the document was printed out onto paper.
- The paper printout was scanned back in using a Ricoh MP C6502, to a PDF file.
- The PDF of the scanned document didn’t undergo OCR, but was distributed in raw form.
That’s a robust but extremely inefficient way to ensure that the redacted document couldn’t leak any information other than the make of the scanner.
Another telling piece of evidence is that the original file and its Quartz 2D rendering have identical numbers of pages (448), and there’s no evidence of multiple versions in the source file.
As published, though, the document is almost impossible to work with. It needs to be passed through OCR so that its text content can be accessed. I used Adobe Acrobat Pro to do this, then opened the PDF that generated.

The same underlying document now consists of almost 200,000 words, or over 1.25 million characters. The OCR has worked well, apart from the struck-through characters in the header of each page. The one fault which does appear occasionally is the running together of words, in sections of text where word spacing has been a little too tight for Adobe’s OCR engine. Thankfully they have little impact when searching the text.

Using Podofyllin, it’s easy to search the PDF using the bar at the top of that view, and the extracted text from a separate search window. Because there’s no direct link between the text version and the original PDF, linked search isn’t yet possible, but it’s straightforward to work with the views separately.
The original scanned report is nearly 150 MB in size; after OCR and a little gentle optimisation of the scanned images, that reduced to 140 MB. But it’s unnecessarily huge and ungainly for studying, and the next step is to reduce it to Rich Text using Podofyllin’s feature to export that directly to an RTF file.

Now I have opened the Rich Text – a mere 2 MB – in DelightEd and applied the Endarken command so that it reads comfortably in either appearance mode. At last I can start to work through its nearly 200,000 words in comfort.
To save you the few minutes it took me to go from the original scanned images to usable Rich Text, here’s a Zipped up copy of the report as an RTF: muellerreport
Sorry about the deredaction, but on this occasion someone was taking no chances, to the point where they couldn’t even trust Adobe Acrobat Pro to redact without leakage. That’s a troubling indictment of the state of PDF and its tools.
