

We’ve been using APFS for over eighteen months now, but have you come across one of its sparse files yet? No, I hadn’t either. This article is the story of my quest to discover one of these rare beasts, if they even exist.
Sparse files must exist in APFS, because they’re one of the features which has been documented by Apple, and even in Wikipedia. They’re mentioned in passing a few times in the current Apple File System Reference too, although nowhere does Apple spell out how to create or recognise one.
Does the volume support sparse files?
Before going any further, if you want to find a sparse file you must discover whether any given volume supports them. So I turned to Disk Utility’s information about mounted volumes, which doesn’t mention this feature. It is available among all the resource values that an app can obtain, under the key volumeSupportsSparseFilesKey, so my first step was to dust off an old tool of mine, VolSizes, and hack it to discover which of my mounted volumes supports sparse files.
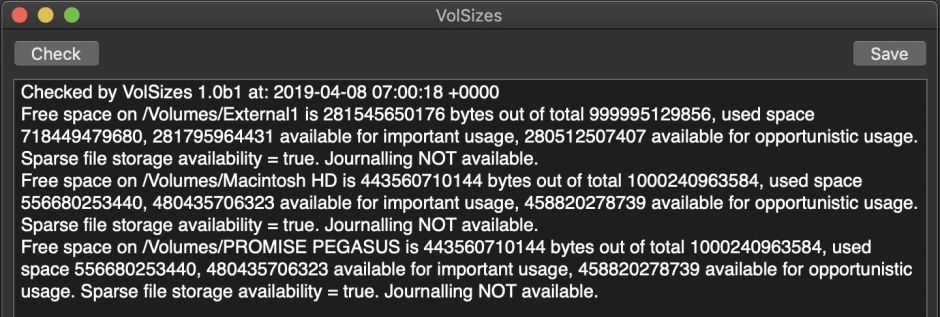
To my surprise, although one of those volumes is still HFS+ for my Time Machine backups, this reported that all three of my regular mounted volumes have the necessary support, in Mojave 10.14.4.
Writing a sparse file
Actually writing a sparse file is a different matter. If you assemble a block of data which is sparse, consisting of a few bytes of regular data, 5 GB of zero bytes, and another few bytes of regular data, writing that in the normal way to a file doesn’t create a sparse file. It just makes a file of a little over 5 GB, almost all of which consists of zero bytes.
The clue came in the vestigial account of APFS in Apple’s developer documentation: “When you use the FileHandle class to create a new write handle, a sparse file is created automatically.”
So to write a sparse file, you have to do the following:
FileManager.default.createFile(atPath: url.path, contents: nil, attributes: nil)
create a new file at the path chosen by the user
let theFHandle = try FileHandle.init(forWritingTo: url)
create a FileHandle to that new file, for writing
let theData1 = Data.init([1, 2, 3, 4, 5, 6, 7, 8, 9])
let theData2 = Data.init([9, 8, 7, 6, 5, 4, 3, 2, 1])
initialise the two data blocks to go either side of the empty area
theFHandle.write(theData1)
write the first data block
theFHandle.seek(toFileOffset: (UInt64(1000000000 * self.theFileSize)))
then move the write pointer the required number of bytes through the file
theFHandle.write(theData2)
write the last data block at the end of the file
theFHandle.closeFile()
close the FileHandle.
(Mis)behaviour
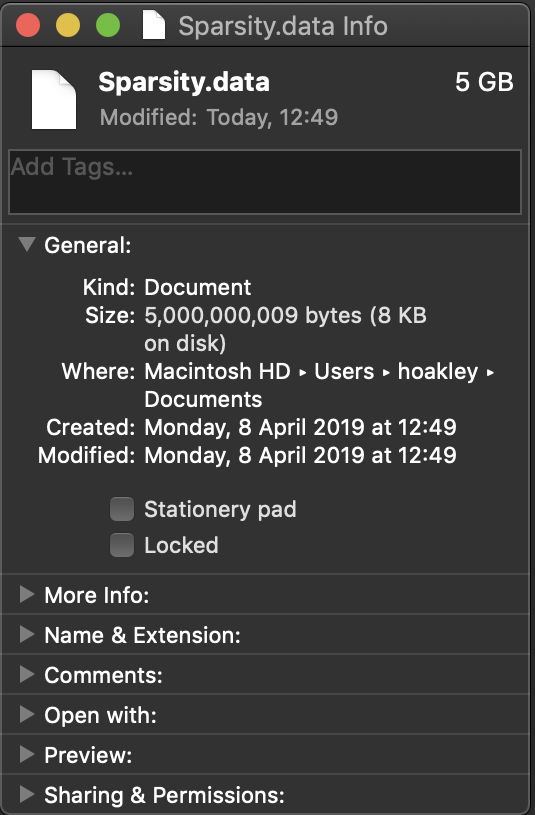
What you end up with behaves quite uniquely. Use Finder’s Get Info and you’ll see that its size is 5 GB, but it only uses 8 KB on disk.
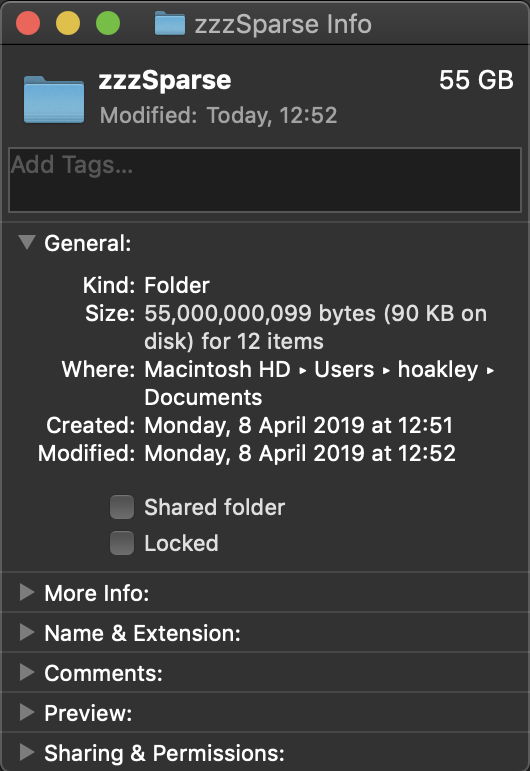
Duplicate it to fill a folder, and that will be reported as having a size of, say, 55 GB, but only taking 90 KB on disk. Results from Terminal are no more helpful: ls -la simply says that each of those sparse files is 5 GB in size.
Time taken for each of these operations is also a good indicator of whether APFS has kept the sparse file, or exploded it to full size. Creating, moving and copying as a sparse file takes an instant; the moment a progress indicator appears, you know that the sparse file has been exploded.
Finder operations depend on whether they can be carried out purely within APFS metadata, or whether any copying of data is required. Making a duplicate or moving the sparse file around retains their sparseness. But copy between volumes, or using cp in Terminal, and the copy suddenly occupies the whole 5 GB rather than just the 8 KB of sparse data.
Sparse files in APFS are a bit like unicorns, or Fabergé eggs: delicate and preciously-crafted. But it’s so easy to break their magic, and turn them back into a very large pile of empty data.
Breaking clones
There’s another issue with APFS which became apparent when experimenting with large and essentially empty files: clones are easily broken during normal file operations.
The idea of cloning is ingenious: when making a copy of a file on the same volume, instead of creating a new file and copying all the data, let the two files share their common and identical blocks of data. As the contents of the two files diverge, the total storage required for them will steadily increase, and the space saved by cloning will progressively fall to zero.
I was puzzled that editing a clone of a very large file invariably broke the clone altogether; when the clone was first made, two 5 GB files only occupied 5 GB of space, but changing a single byte at the start of the clone and saving it suddenly caused the clone to require another 5 GB of space.
This isn’t the fault of APFS, but of traditional techniques for writing out data to files. This normally occurs using the ‘atomic’ option, in which the changed file is written out in full to a temporary file, then that is moved or renamed to create the saved file. Because the temporary file is a new file not the clone, this guarantees that all the benefits of cloning by APFS will be blown away the first time that copy is saved.
The same, of course, applies to sparse files.
Do it yourself
If you want to experiment with sparse files in APFS, you can download my two apps, VolSizes to check that sparse files are available on volumes, and Sparsity to write out sparse files between 1 and 20 GB in size, from here: sparsity10b1
Happy hunting.
