

One of my goals in developing Podofyllin is to make it much easier for users to see inside PDF documents, and to detect problems such as potential leakage of data which they want to remain private. Because PDF is such an opaque format, it’s all too easy for its documents to contain information which you can’t see or find in regular PDF viewers or editors.
If you open a PDF file using a capable text editor like BBEdit, what you see doesn’t provide much help. Currently, you get the same view when you look at raw source in Podofyllin. Here’s an example of the start of a single-page document with just one paragraph of text.
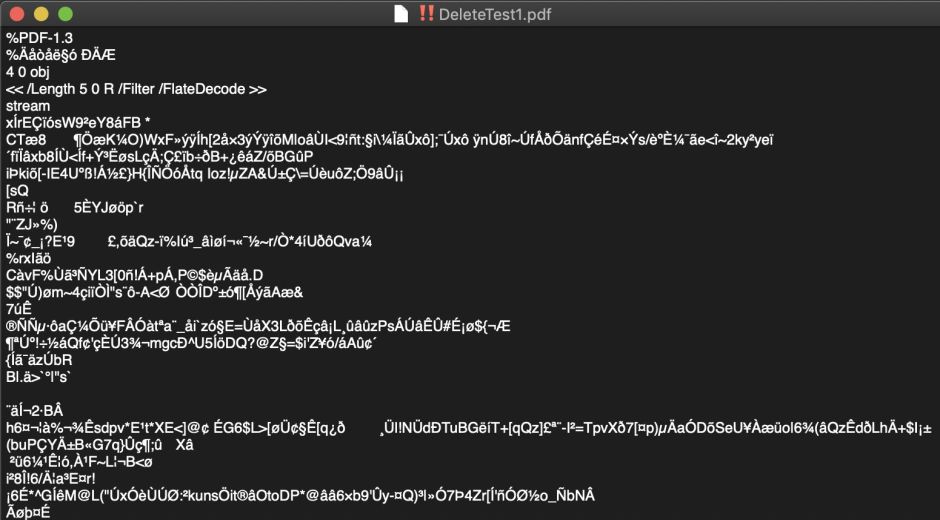
It’s obvious that this uses PDF version 1.3, but after that it gets all messy and binary, as most of its contents are stored in compressed form, using ‘Flate’ as the compressor.
The next step in Podofyllin was to chop out the unreadable binary sections, and present a briefer summary of what’s in the PDF file.
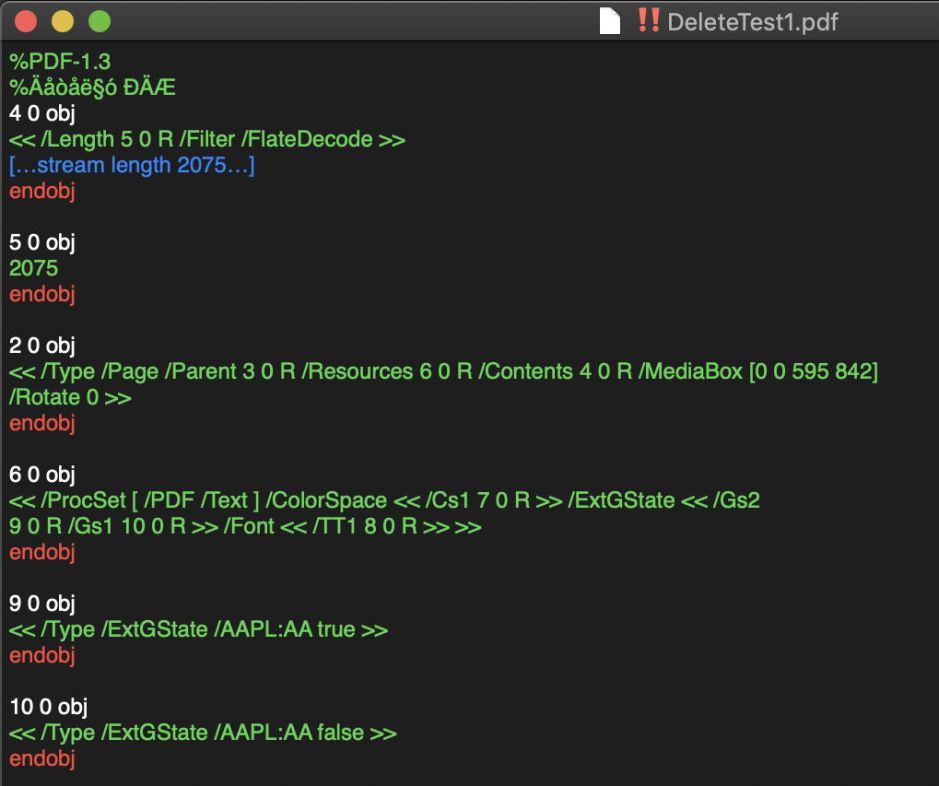
This shows clearly how it’s structured into objects, each of which is numbered, and how objects refer to others. For example, the long binary stream which filled the first view above is object number 4, and its length in bytes is given in object 5 below it, 2075. Below that is object number 2, which defines the single page, whose contents are in object number 4, and so on.
Some advanced PDF editors, such as Adobe Acrobat ‘Pro’ let you browse the object hierarchy, which can be both fascinating and helpful at times. However, because they don’t list objects which are no longer part of the document’s main hierarchy, given in its Catalog object, objects which have become orphaned or superceded may be omitted. And its objects like those which are my main concern.
Another problem is that PDF editors tend to examine not the original PDF file as exists in storage, but the objects and their structure when they’re parsed and converted into memory for display. So what you see in any source isn’t necessarily what you’ve got in the PDF file itself – another potential cause of leakage.
In this new version of Podofyllin, I now parse and analyse two different versions of each opened PDF document: the first is the file as read from storage, and the second is how it is rendered by Quartz 2D graphics in macOS. The analysis places new emphasis on structure, how different objects in the PDF relate to one another. And it’s so succinct that this simple example is summarised in just a few lines.
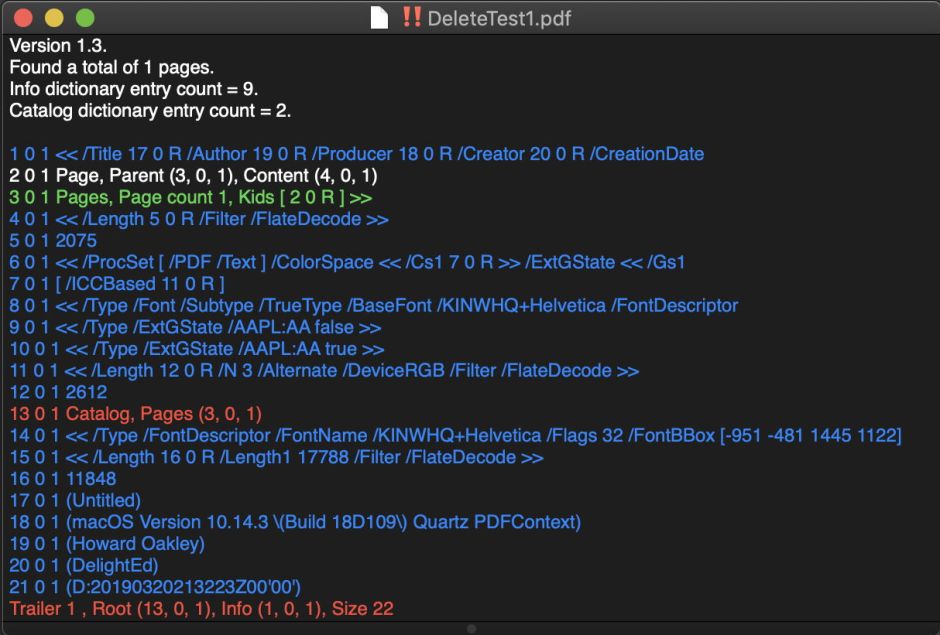
Each line, apart from the trailer at the end, starts with the number of that object, its generation (almost invariably 0), and the version number. The original PDF doesn’t contain the last of those: Podofyllin derives it from the sequence of objects in incrementally-saved documents.
Trailer 1 , Root (13, 0, 1), Info (1, 0, 1), Size 22
The Trailer at the end is from the first and only version of this file. It contains (as required) object references to the Root or Catalog of contents, and the old-style metadata, as well as listing the total number of objects.
1 0 1 << /Title 17 0 R /Author 19 0 R /Producer 18 0 R /Creator 20 0 R /CreationDate
The Info object gives us object references for metadata, such as
17 0 1 (Untitled)
18 0 1 (macOS Version 10.14.3 \(Build 18D109\) Quartz PDFContext)
19 0 1 (Howard Oakley)
20 0 1 (DelightEd)
21 0 1 (D:20190321144701Z00'00')
the Title, PDF engine which created it, author, creating app, and the date of creation, 2019/03/21 at 1447.
13 0 1 Catalog, Pages (3, 0, 1)
The Root object or Catalog tells us about the Pages in object 3 0 1:
3 0 1 Pages, Page count 1, Kids [ 2 0 R ] >>
which in turn tells us that there’s a single page, which is detailed in the object listed as its single Kid.
2 0 1 Page, Parent (3, 0, 1), Content (4, 0, 1)
The single page has a link back to its parent, and content in object 4 0 1:
4 0 1 << /Length 5 0 R /Filter /FlateDecode >>
this is a Flate-compressed file (which would appear in the raw view as binary junk) whose length is given in object 5 0:
5 0 1 2075
The remaining objects are concerned with fonts, colour, and displaying the page:
6 0 1 << /ProcSet [ /PDF /Text ] /ColorSpace << /Cs1 7 0 R >> /ExtGState
7 0 1 [ /ICCBased 11 0 R ]
8 0 1 << /Type /Font /Subtype /TrueType /BaseFont /QITOAR+Helvetica /FontDescriptor
9 0 1 << /Type /ExtGState /AAPL:AA false >>
10 0 1 << /Type /ExtGState /AAPL:AA true >>
11 0 1 << /Length 12 0 R /N 3 /Alternate /DeviceRGB /Filter /FlateDecode >>
12 0 1 2612
14 0 1 << /Type /FontDescriptor /FontName /QITOAR+Helvetica /Flags 32 /FontBBox [-951 -481 1445 1122]
15 0 1 << /Length 16 0 R /Length1 17788 /Filter /FlateDecode >>
16 0 1 11850
I hope you enjoy exploring PDFs using this new version of Podofyllin, which already should alert you to quite a lot of hidden data. My next step, now the app is parsing PDF data without accessing the macOS PDF engine, is to get it to associate linked objects, and to start alerting you to potential problems such as orphaned data.
Podofyllin version 1.0b14 is available from here: podofyllin10b14
and from Downloads above.
